News
OpenAI postpones open weight release
OpenAI has been saying for a while that they want to release an open weight model, but it appears that we will have to wait a bit longer, as Sam Altman announced that they are delaying the release date of the model, which was supposed to be next week. This is to have “time to run additional safety tests and review high-risk areas”.
There is very little known about what the model may be, as even the potential release date was only rumored until Altman confirmed it this week. This will be OpenAI’s first open weight LLM since GPT-2 back in 2019. Altman has said previously that they were targeting an O3 mini level model, as that would put it near SOTA for open source (when he said it back in February). But as we will see, this bar has been raised with many releases matching or exceeding o3 mini quality that can be run on a single GPU at home.
Releases
Kimi K2
A relatively unknown Chinese lab, Moonshot AI has dropped an open source, MIT licensed model that is near SOTA, not just for open source models, but for all models in general, which is cited a potential cause for the delay on the OpenAI open weights release.
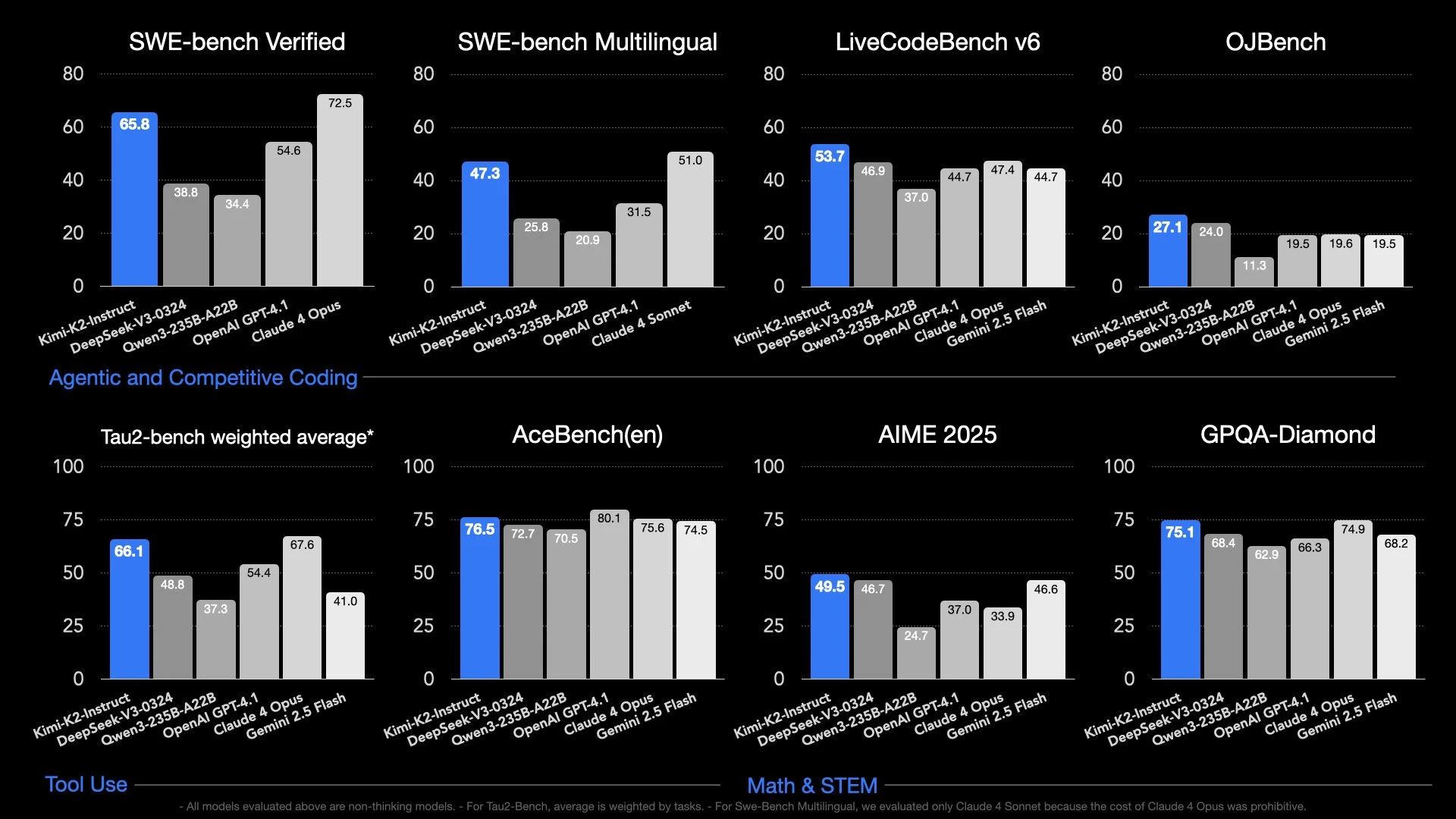
Kimi K2 matches or exceeds top agentic models like Claude Sonnet and Opus 4
The model was trained for and excels at agentic tasks, but also is very good at creative writing, something that has become a pattern for these smaller Chinese labs like MiniMax and Z AI. It does all this without being a thinking/ reasoning model, which has been the main driver of progress for LLMs in the last 6 months.
Unlike the Grok 4 model (discussed later), Kimi K2 passes the private vibe evals for most users, with its closest competitor being Opus 4, which is truly remarkable for an open source model you can (theoretically) download and run at home.
Why do I say theoretically run it at home? Well that is because it is a 1 trillion parameter mixture of experts model, with each expert being 32 billion parameters each. This makes it almost double the size of DeepSeek R1, which has “only” 600 billion parameters. That being said, if you have the over 600GB of memory required just to load the model in 4 bit, you can already run it using Ktransformers at a reasonable 10 tokens per second, assuming you also have a decent consumer GPU to help accelerate things.
While at home inference will be unattainable for most people, the model should be runnable on a single H200 or B200 node at 8 bit quant with VLLM or SGLang, or on a H100 node if you are willing to go down to 4 bit quantization. The model should also be runnable on pretty much every other modern inference framework as well, as it uses the same architecture as DeepSeek V3.
You can try out the model right now for free at kimi.ai, or via their API. Since the model is open source, you can expect more providers for it to pop up over the coming weeks. Speaking of using the model, how much does it cost for API access to the model? One of the reasons behind DeepSeek’s success was its very cheap price relative to the competition. Does Kimi continue this trend?
| Model | $ per million input tokens | $ per million output tokens |
|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
| DeepSeek R1 | $0.55 | $2.19 |
| Kimi K2 | $0.60 | $2.50 |
Yes, it does. While not being as cheap as R1, it has the hidden benefit of not being a reasoning model, which means it will use far less tokens than all the other top models right now, which will result in lower actual prices when using the model. The Chinese have done it again, making a model that rivals the best that the west has to offer, open sourcing everything while doing it.
Grok 4
The XAi team announced their new Grok 4 model this week on (a painful to listen to) livestream. The model uses Grok 3 as the base, and instead of doing continued pretraining to make the base model better, then instead fully focus on fine tuning the model using reinforcement learning.
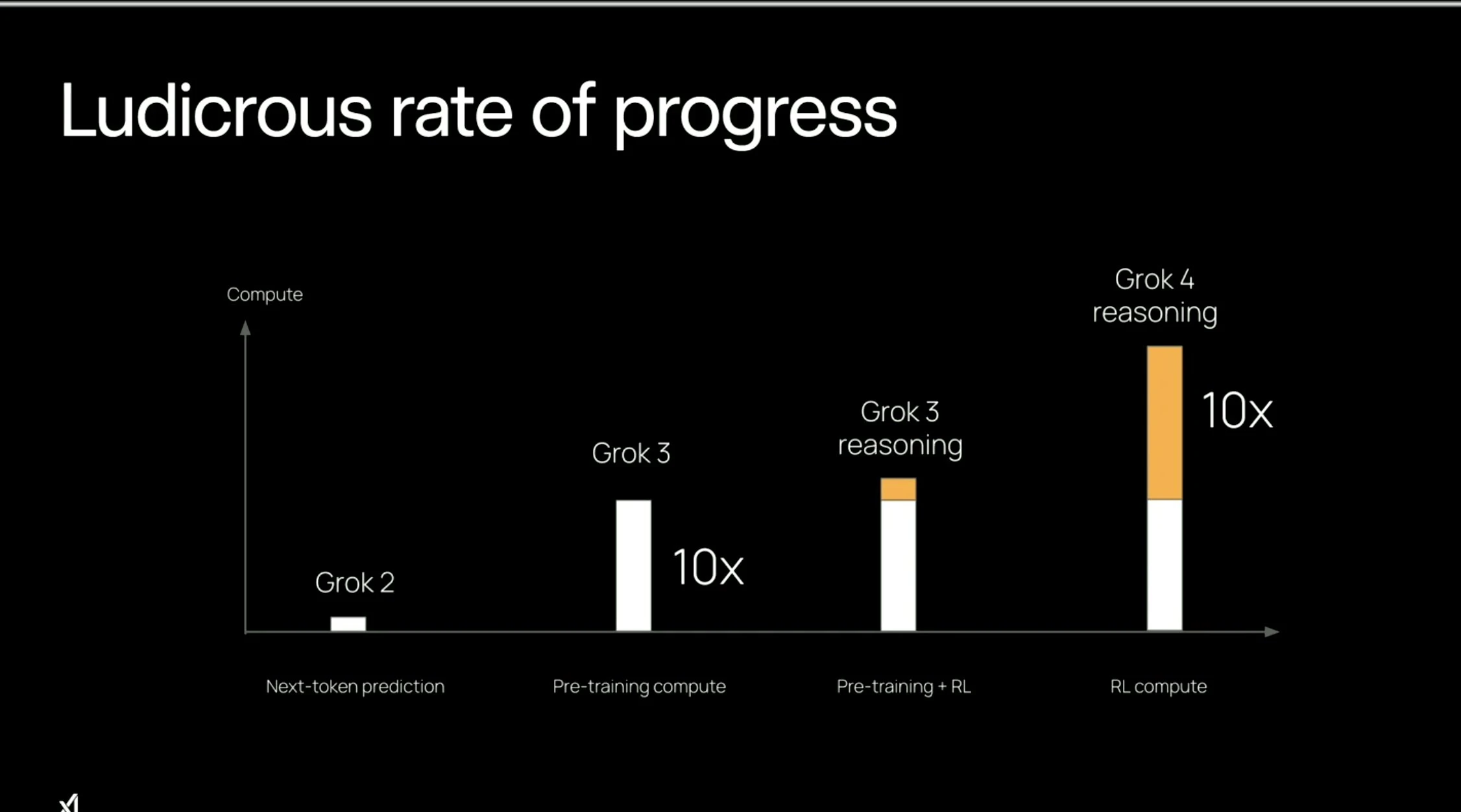
Grok 4 used the same amount of compute in pre-training as they did in post-training. Usually this ratio is much lower, as seen in the compute used for Grok 3 post-training
Grok 4 comes in 2 variants, Grok 4 and Grok 4 Heavy, with the heavy version just being best of 4 sampling of Grok 4. That means that they run your query through Grok 4 four times and then use Grok 4 as a judge to pick the best answer to give to you.
Despite crushing it on benchmarks, the public’s vibe check seems to be of the mind that its similar to the other top models like o3, Gemini 2.5 Pro, and Claude Sonnet/Opus, but not really exhibiting any revolutionary behaviour that would make you want to switch.
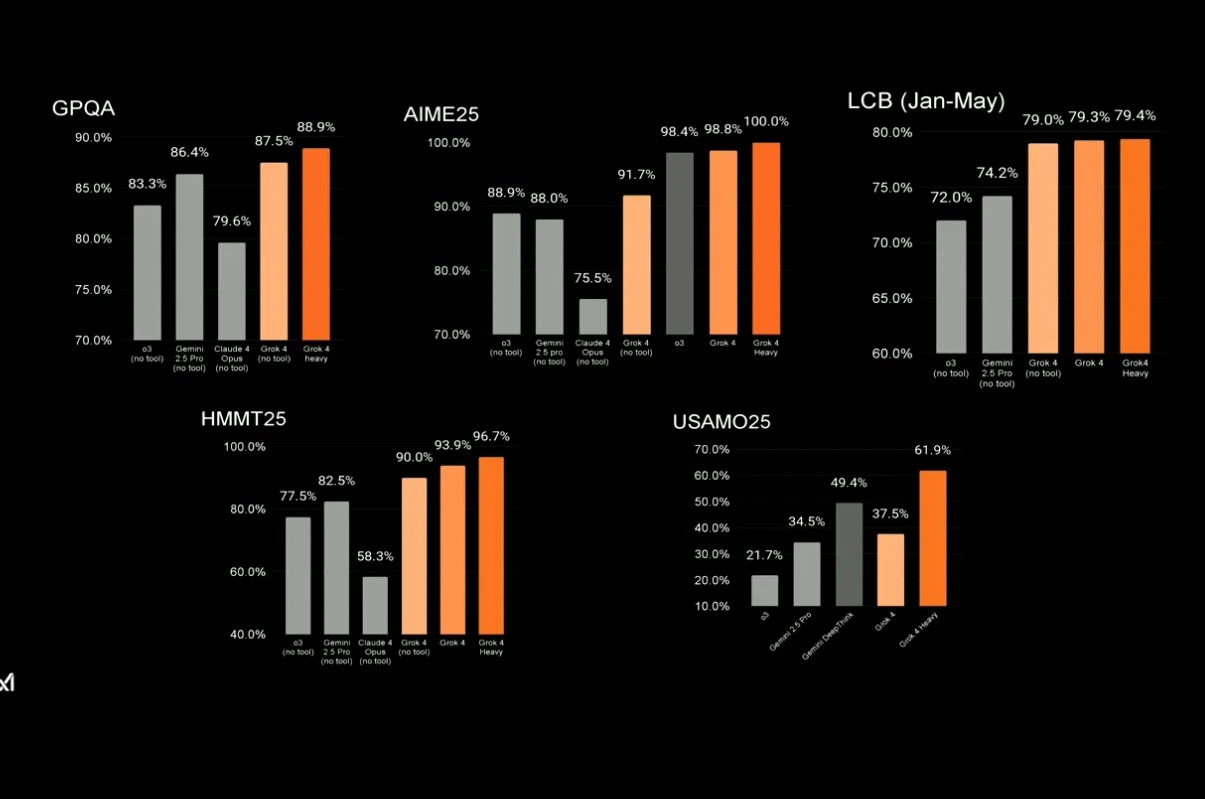
Grok 4 (orange) tops pretty much every major technical benchmark
The model is rumored to be around 2.4 trillion params, and has the exact same pricing as Claude Sonnet, at $3 per million input tokens and $15 per million output tokens.
Reka Flash 3.1
Speaking of o3-mini level open source models, the Reka AI team released an upgrade to their 20b param flash model, mainly improving its code abilities, making it on par with o3-mini and Qwen3 32B.
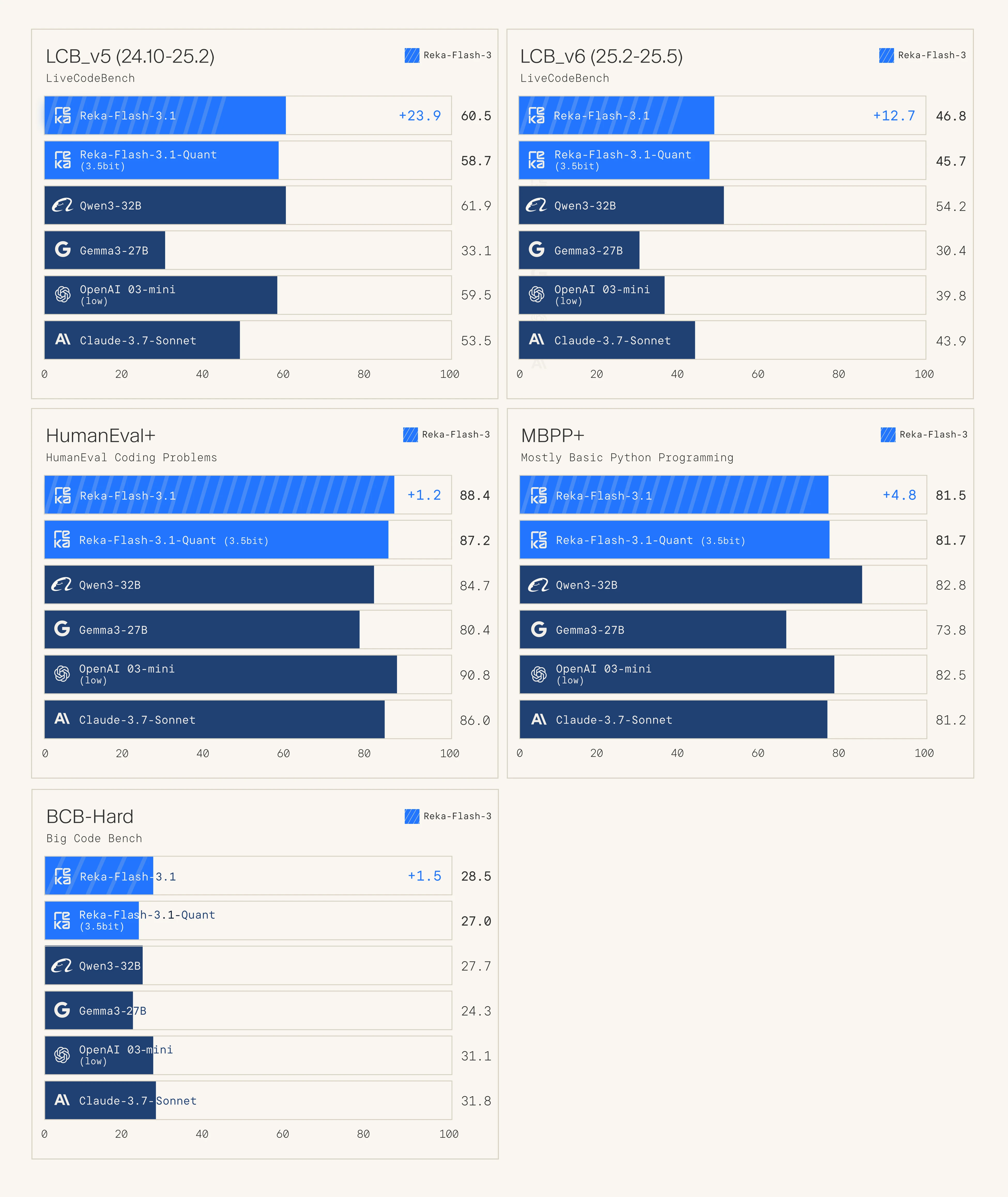
They also provide their own 3.5 bit quantized version, which is only 9GB in size
Reka has probably flown under the radar for most people, but they are a solid lab, similar to Mistral except American. Their flash series of models have been solid, similar in performance to Gemma3 27B and Mistral Small. It is multimodal as well, supporting both image and text inputs.
Research
Multiple Choice = bad eval
Some of the most common benchmarks that people use to evaluate model quality are multiple choice, for instance MMLU and GPQA. The issue with evaluating models like this is that we dont ask LLMs multiple choice questions in the real world. The format is meant to measure the knowledge that the LLMs have, but they might not even be doing that.
In a recent research paper from the Max Planck Institute, researchers show that LLMs are able to get the correct answer without ever seeing the question.
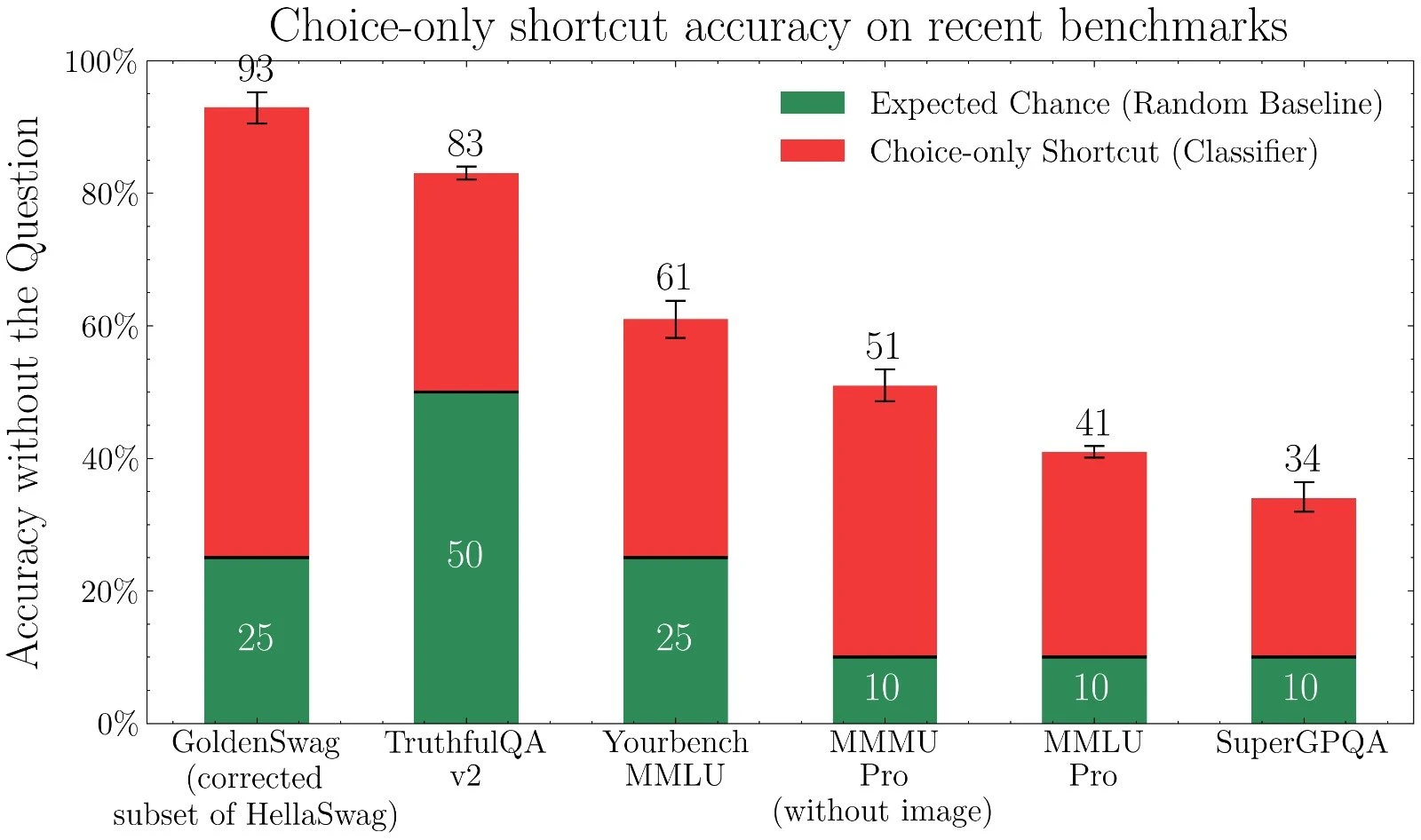
Even without the question, LLMs are able to do far better than random guessing on all MCQ benchmarks
To remedy this issue, the researchers propose that the LLM is just given the question, and then use an LLM as a judge to verify if the answer is correct. The issue they come across however, is that it is harder to verify that an answer is correct than it is to generate a correct answer if no reference correct answer is provided.
This has big implications when running a question through an LLM multiple times and then having another LLM select the best answer (best of n sampling). It shows that we cannot reliably expect to find the correct answer from a set of potential answers.
The researchers overcome this issue with benchmarks by using answer matching (provide the LLM judge the reference answer) and have it see if the generated output matches the answer. But for open world LLM judges, the issue still exists.
Finish
I hope you enjoyed the news this week, if you want to get the news every week, be sure to join our mailing list below.
Me cooking in the lab at 2am on a Wednesday Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
OpenAI adia lançamento de modelo de pesos abertos
A OpenAI vem dizendo há algum tempo que deseja lançar um modelo de pesos abertos, mas parece que teremos que esperar um pouco mais, já que Sam Altman anunciou que estão adiando a data de lançamento do modelo, que estava previsto para a próxima semana. Isso é para ter “tempo de executar testes de segurança adicionais e revisar áreas de alto risco”.
Há muito pouco conhecido sobre o que o modelo pode ser, já que até a data de lançamento potencial era apenas um rumor até Altman confirmar nesta semana. Este será o primeiro LLM de pesos abertos da OpenAI desde o GPT-2 em 2019. Altman disse anteriormente que estavam mirando um modelo de nível O3 mini, pois isso o colocaria próximo ao SOTA para código aberto (quando ele disse em fevereiro). Mas como veremos, esta barra foi elevada com muitos lançamentos correspondendo ou excedendo a qualidade do o3 mini que podem ser executados em uma única GPU em casa.
Lançamentos
Kimi K2
Um laboratório chinês relativamente desconhecido, Moonshot AI lançou um modelo de código aberto, licenciado MIT que está próximo ao SOTA, não apenas para modelos de código aberto, mas para todos os modelos em geral, o que é citado como uma potencial causa para o atraso no lançamento de pesos abertos da OpenAI.
Kimi K2 corresponde ou excede os principais modelos agênticos como Claude Sonnet e Opus 4
O modelo foi treinado para e se destaca em tarefas agênticas, mas também é muito bom em escrita criativa, algo que se tornou um padrão para esses laboratórios chineses menores como MiniMax e Z AI. Ele faz tudo isso sem ser um modelo de pensamento/raciocínio, que tem sido o principal motor de progresso para LLMs nos últimos 6 meses.
Ao contrário do modelo Grok 4 (discutido mais tarde), Kimi K2 passa nas avaliações de vibe privadas para a maioria dos usuários, com seu concorrente mais próximo sendo o Opus 4, o que é verdadeiramente notável para um modelo de código aberto que você pode (teoricamente) baixar e executar em casa.
Por que digo teoricamente executá-lo em casa? Bem, isso é porque é um modelo mixture of experts de 1 trilhão de parâmetros, com cada expert sendo 32 bilhões de parâmetros cada. Isso o torna quase o dobro do tamanho do DeepSeek R1, que tem “apenas” 600 bilhões de parâmetros. Dito isso, se você tem os mais de 600GB de memória necessários apenas para carregar o modelo em 4 bits, você já pode executá-lo usando Ktransformers a razoáveis 10 tokens por segundo, assumindo que você também tem uma GPU de consumidor decente para ajudar a acelerar as coisas.
Embora a inferência em casa seja inatingível para a maioria das pessoas, o modelo deve ser executável em um único nó H200 ou B200 em quantização de 8 bits com VLLM ou SGLang, ou em um nó H100 se você estiver disposto a descer para quantização de 4 bits. O modelo também deve ser executável em praticamente todos os outros frameworks de inferência modernos, pois usa a mesma arquitetura que o DeepSeek V3.
Você pode experimentar o modelo agora gratuitamente em kimi.ai, ou via sua API. Como o modelo é de código aberto, você pode esperar que mais provedores apareçam nas próximas semanas. Falando em usar o modelo, quanto custa o acesso via API ao modelo? Uma das razões por trás do sucesso do DeepSeek foi seu preço muito barato em relação à concorrência. O Kimi continua essa tendência?
| Modelo | $ por milhão de tokens de entrada | $ por milhão de tokens de saída |
|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
| DeepSeek R1 | $0.55 | $2.19 |
| Kimi K2 | $0.60 | $2.50 |
Sim, continua. Embora não seja tão barato quanto o R1, tem o benefício oculto de não ser um modelo de raciocínio, o que significa que usará muito menos tokens do que todos os outros principais modelos agora, o que resultará em preços reais mais baixos ao usar o modelo. Os chineses fizeram de novo, criando um modelo que rivaliza com o melhor que o ocidente tem a oferecer, tornando tudo de código aberto enquanto fazem isso.
Grok 4
A equipe XAi anunciou seu novo modelo Grok 4 esta semana em uma transmissão ao vivo (dolorosa de ouvir). O modelo usa o Grok 3 como base, e em vez de fazer pré-treinamento contínuo para tornar o modelo base melhor, eles focam totalmente em ajustar o modelo usando aprendizado por reforço.
Grok 4 usou a mesma quantidade de computação no pré-treinamento que no pós-treinamento. Normalmente esta proporção é muito menor, como visto na computação usada para o pós-treinamento do Grok 3
Grok 4 vem em 2 variantes, Grok 4 e Grok 4 Heavy, com a versão heavy sendo apenas amostragem best of 4 do Grok 4. Isso significa que eles executam sua consulta através do Grok 4 quatro vezes e depois usam o Grok 4 como juiz para escolher a melhor resposta para dar a você.
Apesar de arrasar nos benchmarks, a verificação de vibe do público parece ser da opinião de que é similar aos outros principais modelos como o3, Gemini 2.5 Pro, e Claude Sonnet/Opus, mas não exibindo realmente nenhum comportamento revolucionário que faria você querer mudar.
Grok 4 (laranja) lidera praticamente todos os principais benchmarks técnicos
O modelo é rumoreado ter cerca de 2,4 trilhões de parâmetros, e tem exatamente o mesmo preço que o Claude Sonnet, a $3 por milhão de tokens de entrada e $15 por milhão de tokens de saída.
Reka Flash 3.1
Falando em modelos de código aberto de nível o3-mini, a equipe Reka AI lançou uma atualização para seu modelo flash de 20b parâmetros, melhorando principalmente suas habilidades de código, tornando-o equivalente ao o3-mini e Qwen3 32B.
Eles também fornecem sua própria versão quantizada de 3,5 bits, que tem apenas 9GB de tamanho
Reka provavelmente passou despercebida para a maioria das pessoas, mas são um laboratório sólido, similar ao Mistral exceto americano. Sua série de modelos flash tem sido sólida, com desempenho similar ao Gemma3 27B e Mistral Small. É multimodal também, suportando tanto entradas de imagem quanto de texto.
Pesquisa
Múltipla Escolha = avaliação ruim
Alguns dos benchmarks mais comuns que as pessoas usam para avaliar a qualidade do modelo são de múltipla escolha, por exemplo MMLU e GPQA. O problema com avaliar modelos assim é que não fazemos perguntas de múltipla escolha aos LLMs no mundo real. O formato é destinado a medir o conhecimento que os LLMs têm, mas eles podem nem estar fazendo isso.
Em um artigo de pesquisa recente do Instituto Max Planck, pesquisadores mostram que LLMs são capazes de obter a resposta correta sem nunca ver a pergunta.
Mesmo sem a pergunta, LLMs são capazes de fazer muito melhor do que adivinhação aleatória em todos os benchmarks MCQ
Para remediar este problema, os pesquisadores propõem que o LLM receba apenas a pergunta, e então use um LLM como juiz para verificar se a resposta está correta. O problema que eles encontram, no entanto, é que é mais difícil verificar que uma resposta está correta do que gerar uma resposta correta se nenhuma resposta de referência correta for fornecida.
Isso tem grandes implicações ao executar uma pergunta através de um LLM várias vezes e então ter outro LLM selecionar a melhor resposta (amostragem best of n). Isso mostra que não podemos confiavelmente esperar encontrar a resposta correta de um conjunto de respostas potenciais.
Os pesquisadores superam este problema com benchmarks usando correspondência de respostas (fornecer ao LLM juiz a resposta de referência) e fazê-lo ver se a saída gerada corresponde à resposta. Mas para juízes LLM de mundo aberto, o problema ainda existe.
Conclusão
Espero que você tenha gostado das notícias desta semana, se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Eu trabalhando no laboratório às 2 da manhã em uma quarta-feira Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
OpenAI pospone el lanzamiento de su modelo de pesos abiertos
OpenAI ha estado diciendo desde hace tiempo que quieren lanzar un modelo de pesos abiertos, pero parece que tendremos que esperar un poco más, ya que Sam Altman anunció que están retrasando la fecha de lanzamiento del modelo, que se suponía sería la próxima semana. Esto es para tener “tiempo de ejecutar pruebas de seguridad adicionales y revisar áreas de alto riesgo”.
Se sabe muy poco sobre lo que podría ser el modelo, ya que incluso la fecha potencial de lanzamiento solo era un rumor hasta que Altman lo confirmó esta semana. Este será el primer LLM de pesos abiertos de OpenAI desde GPT-2 en 2019. Altman ha dicho anteriormente que estaban apuntando a un modelo de nivel O3 mini, ya que eso lo colocaría cerca del estado del arte (SOTA) para código abierto (cuando lo dijo en febrero). Pero como veremos, este listón se ha elevado con muchos lanzamientos que igualan o superan la calidad de o3 mini y que se pueden ejecutar en una sola GPU en casa.
Lanzamientos
Kimi K2
Un laboratorio chino relativamente desconocido, Moonshot AI ha lanzado un modelo de código abierto, con licencia MIT, que está cerca del estado del arte, no solo para modelos de código abierto, sino para todos los modelos en general, lo cual se cita como una posible causa del retraso en el lanzamiento de pesos abiertos de OpenAI.
Kimi K2 iguala o supera los principales modelos agénticos como Claude Sonnet y Opus 4
El modelo fue entrenado para y sobresale en tareas agénticas, pero también es muy bueno en escritura creativa, algo que se ha convertido en un patrón para estos laboratorios chinos más pequeños como MiniMax y Z AI. Hace todo esto sin ser un modelo de pensamiento/razonamiento, que ha sido el principal impulsor del progreso de los LLMs en los últimos 6 meses.
A diferencia del modelo Grok 4 (discutido más adelante), Kimi K2 pasa las evaluaciones de ambiente privadas para la mayoría de los usuarios, siendo su competidor más cercano Opus 4, lo cual es verdaderamente notable para un modelo de código abierto que puedes (teóricamente) descargar y ejecutar en casa.
¿Por qué digo teóricamente ejecutarlo en casa? Bueno, eso es porque es un modelo de mezcla de expertos de 1 billón de parámetros, con cada experto siendo de 32 mil millones de parámetros cada uno. Esto lo hace casi el doble del tamaño de DeepSeek R1, que tiene “solo” 600 mil millones de parámetros. Dicho esto, si tienes los más de 600GB de memoria requeridos solo para cargar el modelo en 4 bits, ya puedes ejecutarlo usando Ktransformers a unos razonables 10 tokens por segundo, asumiendo que también tienes una GPU de consumo decente para ayudar a acelerar las cosas.
Aunque la inferencia en casa será inalcanzable para la mayoría de las personas, el modelo debería ser ejecutable en un solo nodo H200 o B200 con cuantización de 8 bits con VLLM o SGLang, o en un nodo H100 si estás dispuesto a bajar a cuantización de 4 bits. El modelo también debería ser ejecutable en prácticamente cualquier otro framework de inferencia moderno, ya que usa la misma arquitectura que DeepSeek V3.
Puedes probar el modelo ahora mismo gratis en kimi.ai, o a través de su API. Como el modelo es de código abierto, puedes esperar que aparezcan más proveedores en las próximas semanas. Hablando de usar el modelo, ¿cuánto cuesta el acceso API al modelo? Una de las razones detrás del éxito de DeepSeek fue su precio muy económico en relación con la competencia. ¿Continúa Kimi esta tendencia?
| Modelo | $ por millón de tokens de entrada | $ por millón de tokens de salida |
|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
| DeepSeek R1 | $0.55 | $2.19 |
| Kimi K2 | $0.60 | $2.50 |
Sí, lo hace. Aunque no es tan barato como R1, tiene el beneficio oculto de no ser un modelo de razonamiento, lo que significa que usará muchos menos tokens que todos los demás modelos principales en este momento, lo que resultará en precios reales más bajos al usar el modelo. Los chinos lo han hecho de nuevo, creando un modelo que rivaliza con lo mejor que Occidente tiene para ofrecer, haciendo todo de código abierto mientras lo hacen.
Grok 4
El equipo de XAi anunció su nuevo modelo Grok 4 esta semana en una transmisión en vivo (dolorosa de escuchar). El modelo usa Grok 3 como base, y en lugar de hacer entrenamiento previo continuo para mejorar el modelo base, se enfocan completamente en afinar el modelo usando aprendizaje por refuerzo.
Grok 4 usó la misma cantidad de cómputo en pre-entrenamiento que en post-entrenamiento. Usualmente esta proporción es mucho menor, como se ve en el cómputo usado para el post-entrenamiento de Grok 3
Grok 4 viene en 2 variantes, Grok 4 y Grok 4 Heavy, siendo la versión heavy simplemente el mejor de 4 muestreos de Grok 4. Eso significa que ejecutan tu consulta a través de Grok 4 cuatro veces y luego usan Grok 4 como juez para seleccionar la mejor respuesta para darte.
A pesar de arrasarlo en los benchmarks, la verificación de ambiente del público parece ser de la opinión de que es similar a los otros modelos principales como o3, Gemini 2.5 Pro, y Claude Sonnet/Opus, pero no realmente exhibiendo ningún comportamiento revolucionario que te haría querer cambiar.
Grok 4 (naranja) lidera prácticamente todos los benchmarks técnicos principales
Se rumora que el modelo tiene alrededor de 2.4 billones de parámetros, y tiene exactamente el mismo precio que Claude Sonnet, a $3 por millón de tokens de entrada y $15 por millón de tokens de salida.
Reka Flash 3.1
Hablando de modelos de código abierto de nivel o3-mini, el equipo de Reka AI lanzó una actualización de su modelo flash de 20b parámetros, mejorando principalmente sus habilidades de código, haciéndolo a la par con o3-mini y Qwen3 32B.
También proporcionan su propia versión cuantizada de 3.5 bits, que tiene solo 9GB de tamaño
Reka probablemente ha pasado desapercibido para la mayoría de las personas, pero son un laboratorio sólido, similar a Mistral excepto que es estadounidense. Su serie de modelos flash ha sido sólida, con un rendimiento similar a Gemma3 27B y Mistral Small. También es multimodal, soportando tanto entradas de imagen como de texto.
Investigación
Opción Múltiple = mala evaluación
Algunos de los benchmarks más comunes que la gente usa para evaluar la calidad del modelo son de opción múltiple, por ejemplo MMLU y GPQA. El problema con evaluar modelos de esta manera es que no hacemos preguntas de opción múltiple a los LLMs en el mundo real. El formato está destinado a medir el conocimiento que tienen los LLMs, pero puede que ni siquiera estén haciendo eso.
En un artículo de investigación reciente del Instituto Max Planck, los investigadores muestran que los LLMs son capaces de obtener la respuesta correcta sin siquiera ver la pregunta.
Incluso sin la pregunta, los LLMs son capaces de hacerlo mucho mejor que adivinar al azar en todos los benchmarks de opción múltiple
Para remediar este problema, los investigadores proponen que al LLM solo se le dé la pregunta, y luego usar un LLM como juez para verificar si la respuesta es correcta. El problema con el que se encuentran, sin embargo, es que es más difícil verificar que una respuesta es correcta que generar una respuesta correcta si no se proporciona una respuesta correcta de referencia.
Esto tiene grandes implicaciones al ejecutar una pregunta a través de un LLM múltiples veces y luego hacer que otro LLM seleccione la mejor respuesta (muestreo best of n). Muestra que no podemos esperar de manera confiable encontrar la respuesta correcta de un conjunto de respuestas potenciales.
Los investigadores superan este problema con los benchmarks utilizando coincidencia de respuestas (proporcionan al LLM juez la respuesta de referencia) y hacen que vea si la salida generada coincide con la respuesta. Pero para los jueces LLM de mundo abierto, el problema aún existe.
Finalizar
Espero que hayas disfrutado las noticias de esta semana, si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Yo cocinando en el laboratorio a las 2am un miércoles