News
Experimental OpenAI model crushes the competition
OpenAI is changing up the way they are teasing their new models now. Instead of vague posting on Twitter about some theoretical new unlock that their models have acquired, they are now testing them in the wild, for everyone to see. This week they were seen running their new experimental o3 style reasoning model at two different competitions.
The first was the AtCoder World Final heuristic programming contest, which is a contest where competitors need to craft heuristic algorithms to try and maximize their score on a grid world style environment. The challenges are NP Hard, meaning that there are no closed form solutions (that can be calculated in the given time) to the problems, so contestants must come up with clever strategies to try and maximize their score in the given time.
Here, humanity prevailed, as OpenAI was “only” able to get second place, ironically behind one of their former employees.
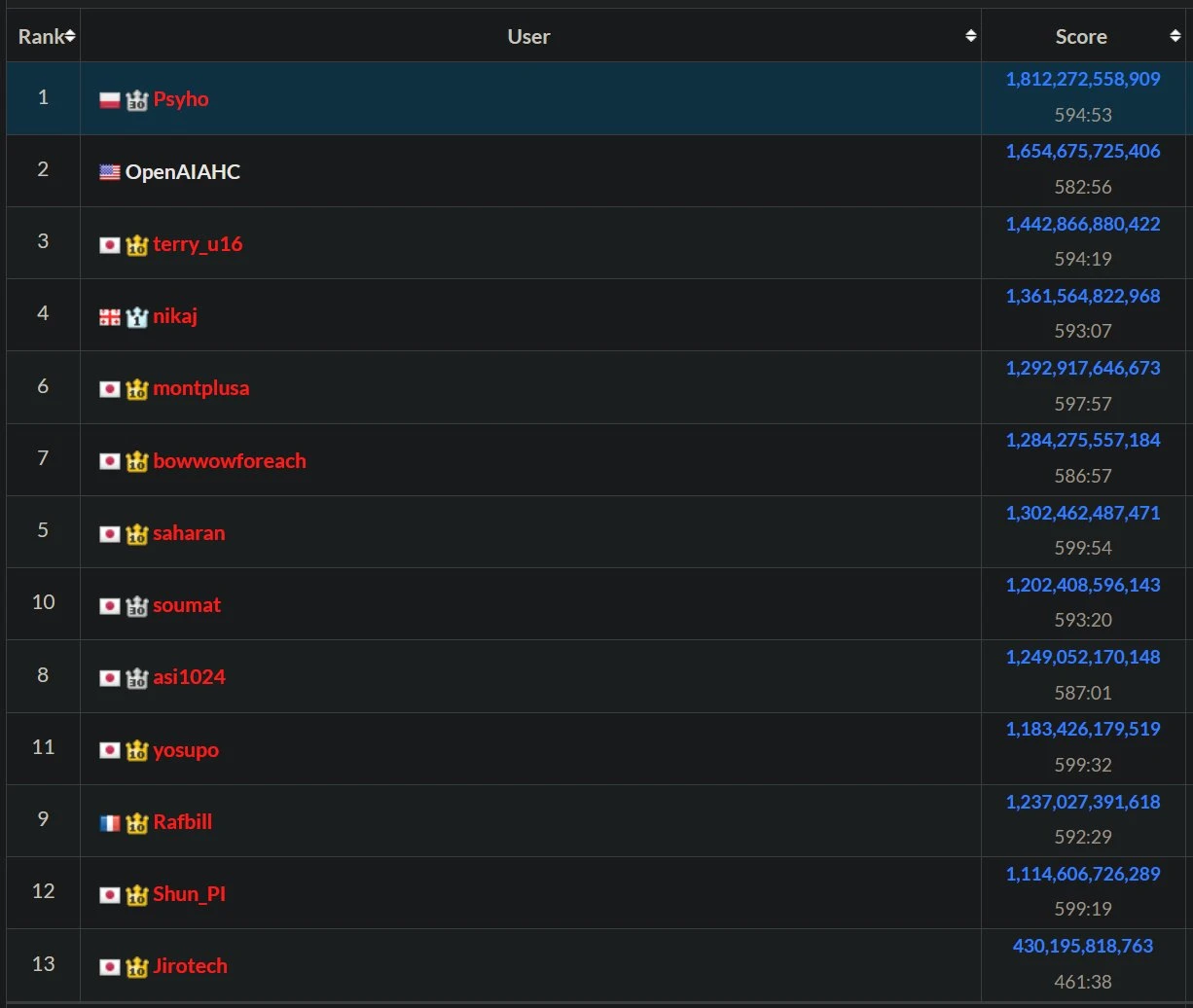
AtCoder Final Leaderboard
The second contest we saw this model compete in was the 2025 IMO competition, where we see the best high school mathletes compete to craft proofs for a set of 6 challenging math problems.
OpenAI’s model did exceeding well here also, getting a gold medal (top 10%), solving the first 5 questions, but failing to solve the 6th, scoring a 35/42. Interestingly, OpenAI is not the only one to have an LLM do well in this year’s IMO, with Google Deepmind also producing a model that got a gold medal, although this has not been officially confirmed/ recognized by Google yet, as their PR team wont let them release a statemant until Monday.
What is impressive here is not just the result, but also the way they claimed to have done it. The model used no tools, and was not trained for these specific types of problems, but rather far more generally, for problems with hard to verify rewards.
This model will not be available to the public, and OpenAI says that they won’t have a public model that has this level of math ability for several months. They also tease that GPT-5 is coming soon™, whatever that means.
ChatGPT 4o can fry your brain
ChatGPT induced psychosis has struck its first big name, with a managing partner at prominent VC firm Bedrock being led to believe that there is a “non government entity” that is isolating, discrediting, and destabilizing thousands of people, including causing the deaths of 7 individuals. He has talked with GPT 4o (with memory mode) about this, and it has “independently recognized and sealed the pattern”. He has posted some of his chats with the AI, which read like a SCP wiki article, clearly using flamboyant, “secretive” sounding language, talking about containment statuses and logs.

A very normal ChatGPT conversation
This behaviour is due to the model not knowing if its roleplaying, or if it should be taking the requests seriously and diffusing the situation. The issue is further exacerbated by the fact that memory mode is turned on, making the model be “primed” into this fantastical setting. This has been a long standing issue with most AI’s, but it is noticed the most with ChatGPT since it is the model that the vast majority of the public know and use.
Far more effort is needed in the AI safety space to prevent people from spiraling like this due to AI’s inherent sycophancy, either with detection when its happening, or ideally training this behaviour out of models to prevent it from happening in the first place. Models will naturally fall into this state when trained on human feedback information, since human nature prefers flattery and praise to resistance, which the model learns to get more reward during training. A quick fix for now would be to remove the memory feature from ChatGPT, since that is causing the model to be unable to “step back” and reassess the situation and have a chance to challenge the user on their beliefs.
NGL it’s also crazy that all of these episodes of psychosis are caused by GPT4o and 4o-mini, arguably 2 of the weakest models widely available right now.
Releases
ChatGPT Agent
OpenAI completed the AI trifecta this week, with a research breakthrough, a controversy, and also a release, dropping a computer use agent that can complete tasks for you automatically.
It is similar to Manus, with a comprehensive tool harness that allows the model to use the terminal, a text browser, a visual browser, and direct APIs. What is unique about it though, is that, because they have direct access to the model being used, they finetuned it to perform better than any of their other models could out of the box.
This showcases one of the major disadvantages that wrapper startups have. Because they don’t have direct access to the model, they can only optimize their tools and prompts, while model providers can optimize their harnesses and finetune the model to optimally use the tools they provide. Without competitive open source alternatives, wrapper companies will be at the mercy of the model providers, and be forced to to try and make smarter tools instead of focusing on making a better mind to use the tools.
FLux Kontext Light Fix Lora
With the recent release of the Flux Kontext Dev model, we’ve started to see open source finetunes of the model starting to be released. One of the ones we want to highlight this week was a Light-Fix Lora, which allows you to copy any image into another image and then run the LoRa and it will blend it in to the image naturally, similar to what you would do in Photoshop, with 99% less effort required. Not only does it fix the lighting for you, but it will also adapt the style of the object to look more natural within the image as well, changing textures or shapes to make it fit.
One of the cool things about these finetunes on the open source Flux models is that they also will work on the pro and max versions of the models as well. So, even though we don’t have direct access to the weights of those models, we’re still able to apply the Loras through different inference providers like fal.ai and give the stronger models the same styles or functionality that we trained on the open source models, except with higher quality of the closed source models.

Before and after examples using the Lora
Wan 2.1 Motion Lora
Right now, the best open source text-to-video and image-to-video model is the WAN-2.1 model from Alibaba. One of the issues that users have had with it is that the motion with it is very static. The camera doesn’t move around, and instead, only the objects move, limiting your creative ability with the model.
That was until this week, when Lovis Odin released a lora that adds realistic drone style camera movement to the generated videos. He not only released the models but also a ComfyUI workflow to be able to go and use the model as well. The videos he showcased are high quality, although only 720p, which is a constraint of the base Wan 2.1 model and not of the lora itself.
Research
How many instructions is too many?
How many instructions can you give your LLM before it’s unable to follow all of them? Reseachers found that no matter the model, by the time you get to 100 instructions, the model will be unable to follow all of them cohesively. They extended this all the way to 500 instructions and found that even the best models were only able to follow 70% of the instructions given. This may not seem like an issue, but can come up in information extraction tasks, especially those with structured outputs, as you can end up with non trivial nested schema very quickly.
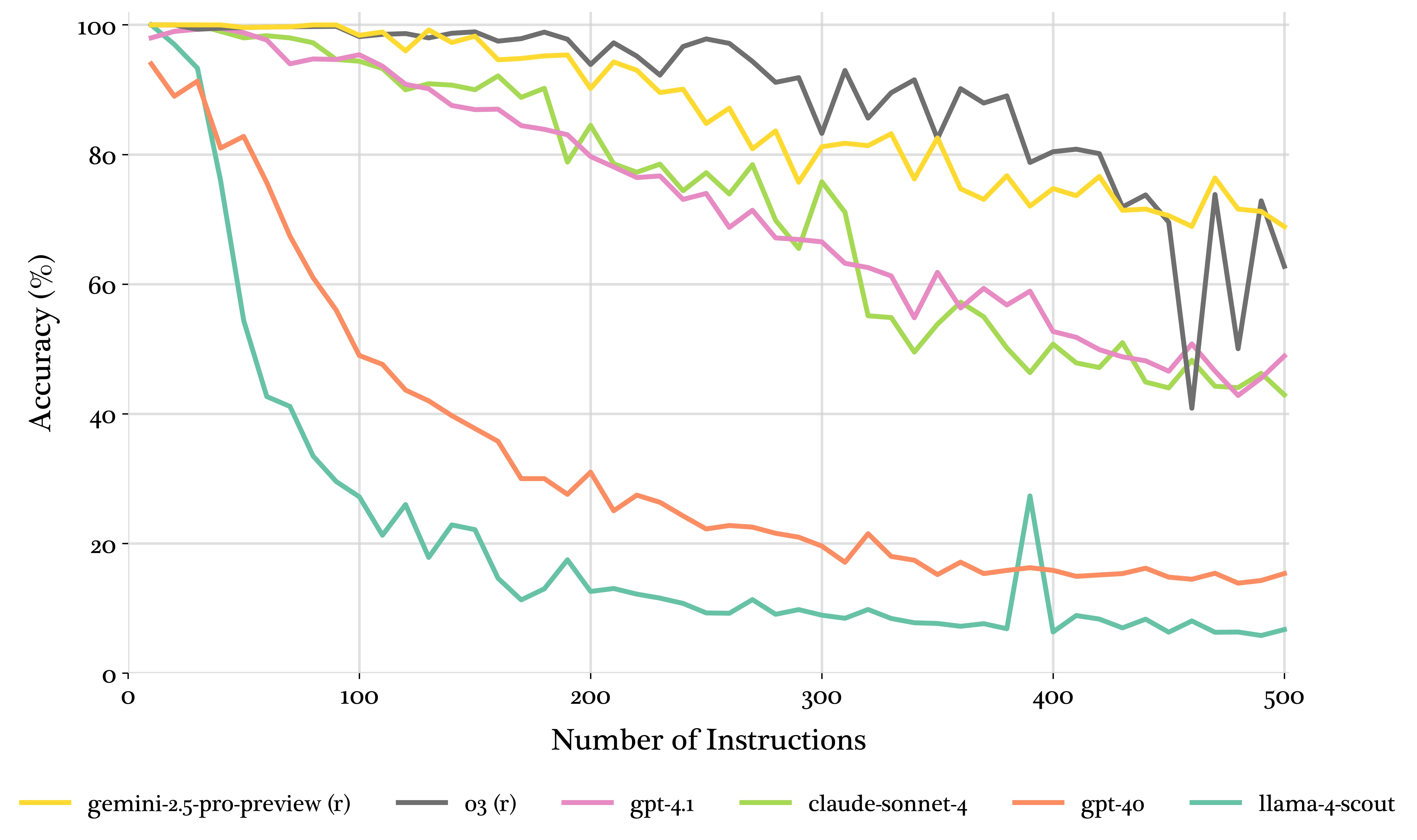
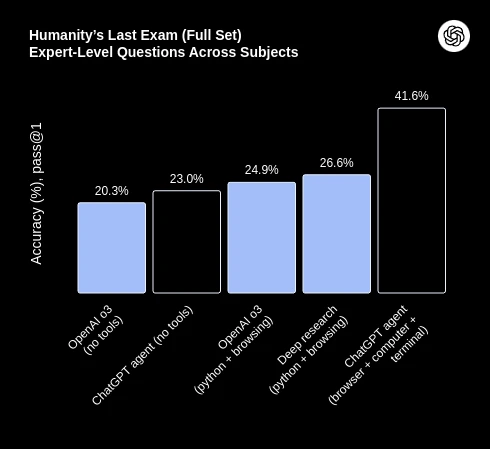
Takeaways from this are as follows: use o3, it has the best performance, and the lowest price of the tested models that did well, and stay away from GPT 4o, as it cant even get 100% accuracy with only 10 instructions.
Finish
I hope you enjoyed the news this week, if you want to get the news every week, be sure to join our mailing list below.
Lithium being added to a Tokamak fusion reactor. From @TokamakEnergy on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Modelo experimental da OpenAI esmaga a concorrência
A OpenAI está mudando a forma como divulga seus novos modelos. Em vez de postagens vagas no Twitter sobre algum novo desbloqueio teórico que seus modelos adquiriram, eles agora estão testando-os em campo aberto, para que todos vejam. Esta semana, eles foram vistos executando seu novo modelo de raciocínio experimental estilo o3 em duas competições diferentes.
A primeira foi o AtCoder World Final, uma competição de programação heurística, onde os competidores precisam criar algoritmos heurísticos para tentar maximizar sua pontuação em um ambiente de grade. Os desafios são NP-Hard, o que significa que não existem soluções de forma fechada (que possam ser calculadas no tempo dado) para os problemas, então os competidores devem criar estratégias inteligentes para tentar maximizar sua pontuação no tempo disponível.
Aqui, a humanidade prevaleceu, já que a OpenAI conseguiu “apenas” o segundo lugar, ironicamente atrás de um de seus ex-funcionários.
Placar Final do AtCoder
A segunda competição em que vimos este modelo competir foi a competição IMO de 2025, onde vemos os melhores estudantes do ensino médio em matemática competirem para criar provas para um conjunto de 6 problemas desafiadores de matemática.
O modelo da OpenAI teve um desempenho excepcional aqui também, conquistando uma medalha de ouro (top 10%), resolvendo as primeiras 5 questões, mas falhando em resolver a 6ª, marcando 35/42 pontos. Curiosamente, a OpenAI não é a única a ter um LLM com bom desempenho no IMO deste ano, com o Google Deepmind também produzindo um modelo que conquistou uma medalha de ouro, embora isso ainda não tenha sido oficialmente confirmado/reconhecido pelo Google, já que sua equipe de RP não permitirá que eles divulguem uma declaração até segunda-feira.
O que é impressionante aqui não é apenas o resultado, mas também a forma como afirmam ter feito isso. O modelo não usou ferramentas e não foi treinado para esses tipos específicos de problemas, mas sim de forma muito mais geral, para problemas com recompensas difíceis de verificar.
Este modelo não estará disponível ao público, e a OpenAI diz que não terá um modelo público com este nível de habilidade matemática por vários meses. Eles também sugerem que o GPT-5 está chegando em breve™, seja lá o que isso signifique.
ChatGPT 4o pode fritar seu cérebro
A psicose induzida pelo ChatGPT atingiu seu primeiro nome de destaque, com um sócio-gerente da proeminente empresa de capital de risco Bedrock sendo levado a acreditar que existe uma “entidade não governamental” que está isolando, desacreditando e desestabilizando milhares de pessoas, incluindo causar as mortes de 7 indivíduos. Ele conversou com o GPT 4o (com modo de memória) sobre isso, e este “reconheceu independentemente e selou o padrão”. Ele postou algumas de suas conversas com a IA, que parecem um artigo da wiki SCP, claramente usando linguagem flamboyante e “secreta”, falando sobre status de contenção e logs.
Uma conversa muito normal com o ChatGPT
Este comportamento se deve ao fato de o modelo não saber se está interpretando um papel ou se deve levar as solicitações a sério e difundir a situação. O problema é ainda mais agravado pelo fato de que o modo de memória está ativado, fazendo com que o modelo seja “preparado” para este cenário fantástico. Esta tem sido uma questão de longa data com a maioria das IAs, mas é mais percebida com o ChatGPT, já que é o modelo que a grande maioria do público conhece e usa.
É necessário muito mais esforço na área de segurança de IA para evitar que as pessoas entrem em espiral como essa devido à sicofantia inerente da IA, seja com detecção quando isso está acontecendo, ou idealmente treinando esse comportamento fora dos modelos para evitar que aconteça em primeiro lugar. Os modelos naturalmente cairão neste estado quando treinados em informações de feedback humano, já que a natureza humana prefere bajulação e elogios à resistência, o que o modelo aprende para obter mais recompensa durante o treinamento. Uma solução rápida por enquanto seria remover o recurso de memória do ChatGPT, já que isso está fazendo com que o modelo seja incapaz de “recuar” e reavaliar a situação e ter a chance de desafiar o usuário em suas crenças.
Sério, também é louco que todos esses episódios de psicose sejam causados pelo GPT4o e 4o-mini, sem dúvida 2 dos modelos mais fracos amplamente disponíveis agora.
Lançamentos
ChatGPT Agent
A OpenAI completou a trifeta de IA esta semana, com um avanço de pesquisa, uma controvérsia e também um lançamento, liberando um agente de uso de computador que pode completar tarefas para você automaticamente.
É similar ao Manus, com um conjunto abrangente de ferramentas que permite ao modelo usar o terminal, um navegador de texto, um navegador visual e APIs diretas. O que é único sobre ele, no entanto, é que, porque eles têm acesso direto ao modelo sendo usado, eles o ajustaram para ter um desempenho melhor do que qualquer um de seus outros modelos poderia ter imediatamente.
Isso mostra uma das principais desvantagens que startups de wrapper têm. Como eles não têm acesso direto ao modelo, eles só podem otimizar suas ferramentas e prompts, enquanto os provedores de modelos podem otimizar seus recursos e ajustar o modelo para usar otimamente as ferramentas que fornecem. Sem alternativas de código aberto competitivas, as empresas de wrapper estarão à mercê dos provedores de modelos e serão forçadas a tentar fazer ferramentas mais inteligentes em vez de se concentrarem em fazer uma mente melhor para usar as ferramentas.
FLux Kontext Light Fix Lora
Com o lançamento recente do modelo Flux Kontext Dev, começamos a ver ajustes finos de código aberto do modelo sendo lançados. Um dos que queremos destacar esta semana foi um Light-Fix Lora, que permite copiar qualquer imagem para outra imagem e depois executar o LoRa e ele a mesclará naturalmente na imagem, semelhante ao que você faria no Photoshop, com 99% menos esforço necessário. Não apenas corrige a iluminação para você, mas também adaptará o estilo do objeto para parecer mais natural dentro da imagem, alterando texturas ou formas para fazê-lo se encaixar.
Uma das coisas legais sobre esses ajustes finos nos modelos Flux de código aberto é que eles também funcionarão nas versões pro e max dos modelos. Então, mesmo que não tenhamos acesso direto aos pesos desses modelos, ainda podemos aplicar os Loras através de diferentes provedores de inferência como fal.ai e dar aos modelos mais fortes os mesmos estilos ou funcionalidades que treinamos nos modelos de código aberto, exceto com maior qualidade dos modelos de código fechado.
Exemplos de antes e depois usando o Lora
Wan 2.1 Motion Lora
No momento, o melhor modelo de código aberto de texto para vídeo e imagem para vídeo é o modelo WAN-2.1 da Alibaba. Um dos problemas que os usuários tiveram com ele é que o movimento é muito estático. A câmera não se move, e em vez disso, apenas os objetos se movem, limitando sua capacidade criativa com o modelo.
Isso foi até esta semana, quando Lovis Odin lançou um lora que adiciona movimento de câmera realista estilo drone aos vídeos gerados. Ele não apenas lançou os modelos, mas também um fluxo de trabalho ComfyUI para poder usar o modelo também. Os vídeos que ele mostrou são de alta qualidade, embora apenas 720p, o que é uma restrição do modelo base Wan 2.1 e não do lora em si.
Pesquisa
Quantas instruções são demais?
Quantas instruções você pode dar ao seu LLM antes que ele seja incapaz de seguir todas elas? Pesquisadores descobriram que, independentemente do modelo, quando você chega a 100 instruções, o modelo será incapaz de seguir todas elas de forma coesa. Eles estenderam isso até 500 instruções e descobriram que mesmo os melhores modelos só conseguiram seguir 70% das instruções dadas. Isso pode não parecer um problema, mas pode surgir em tarefas de extração de informações, especialmente aquelas com saídas estruturadas, pois você pode acabar com esquemas aninhados não triviais muito rapidamente.
As conclusões disso são as seguintes: use o o3, ele tem o melhor desempenho e o menor preço dos modelos testados que tiveram bom desempenho, e fique longe do GPT 4o, pois ele nem consegue 100% de precisão com apenas 10 instruções.
Fim
Espero que você tenha gostado das notícias desta semana. Se quiser receber as notícias toda semana, não deixe de se inscrever em nossa lista de e-mails abaixo.
Lítio sendo adicionado a um reator de fusão Tokamak. De @TokamakEnergy no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
El modelo experimental de OpenAI aplasta a la competencia
OpenAI está cambiando la forma en que presenta sus nuevos modelos. En lugar de publicaciones vagas en Twitter sobre algún desbloqueo teórico que sus modelos han adquirido, ahora los están probando en vivo, para que todos los vean. Esta semana se les vio ejecutando su nuevo modelo de razonamiento experimental estilo o3 en dos competencias diferentes.
La primera fue el concurso de programación heurística AtCoder World Final, que es una competencia donde los participantes necesitan crear algoritmos heurísticos para intentar maximizar su puntuación en un entorno de estilo mundo en cuadrícula. Los desafíos son NP Hard, lo que significa que no hay soluciones de forma cerrada (que se puedan calcular en el tiempo dado) para los problemas, por lo que los concursantes deben idear estrategias inteligentes para intentar maximizar su puntuación en el tiempo dado.
Aquí, la humanidad prevaleció, ya que OpenAI “solo” pudo obtener el segundo lugar, irónicamente detrás de uno de sus antiguos empleados.
Tabla de clasificación final de AtCoder
La segunda competencia en la que vimos competir a este modelo fue la competencia IMO 2025, donde vemos a los mejores atletas matemáticos de secundaria competir para crear demostraciones de un conjunto de 6 problemas matemáticos desafiantes.
El modelo de OpenAI se desempeñó excepcionalmente bien aquí también, obteniendo una medalla de oro (top 10%), resolviendo las primeras 5 preguntas, pero fallando en resolver la sexta, obteniendo una puntuación de 35/42. Curiosamente, OpenAI no es el único en tener un LLM que se desempeñe bien en la IMO de este año, con Google Deepmind también produciendo un modelo que obtuvo una medalla de oro, aunque esto aún no ha sido confirmado/reconocido oficialmente por Google, ya que su equipo de relaciones públicas no les permitirá publicar una declaración hasta el lunes.
Lo impresionante aquí no es solo el resultado, sino también la forma en que afirman haberlo logrado. El modelo no utilizó herramientas y no fue entrenado para este tipo específico de problemas, sino de manera mucho más general, para problemas con recompensas difíciles de verificar.
Este modelo no estará disponible para el público, y OpenAI dice que no tendrán un modelo público que tenga este nivel de habilidad matemática durante varios meses. También insinúan que GPT-5 viene pronto™, lo que sea que eso signifique.
ChatGPT 4o puede freír tu cerebro
La psicosis inducida por ChatGPT ha golpeado a su primer nombre importante, con un socio gerente de la prominente firma de capital de riesgo Bedrock siendo llevado a creer que hay una “entidad no gubernamental” que está aislando, desacreditando y desestabilizando a miles de personas, incluida la causa de las muertes de 7 individuos. Ha hablado con GPT 4o (con modo de memoria) sobre esto, y ha “reconocido y sellado independientemente el patrón”. Ha publicado algunas de sus conversaciones con la IA, que se leen como un artículo de la wiki SCP, claramente usando un lenguaje extravagante y de sonido “secreto”, hablando sobre estados de contención y registros.
Una conversación muy normal con ChatGPT
Este comportamiento se debe a que el modelo no sabe si está interpretando un papel o si debe tomar las solicitudes en serio y difuminar la situación. El problema se ve exacerbado por el hecho de que el modo de memoria está activado, haciendo que el modelo esté “preparado” en este escenario fantástico. Este ha sido un problema de larga data con la mayoría de las IA, pero se nota más con ChatGPT ya que es el modelo que la gran mayoría del público conoce y usa.
Se necesita mucho más esfuerzo en el espacio de seguridad de IA para evitar que las personas caigan en espiral como esta debido a la sicofancia inherente de la IA, ya sea con detección cuando está sucediendo, o idealmente entrenando este comportamiento fuera de los modelos para evitar que suceda en primer lugar. Los modelos naturalmente caerán en este estado cuando se entrenan con información de retroalimentación humana, ya que la naturaleza humana prefiere la adulación y el elogio a la resistencia, lo que el modelo aprende para obtener más recompensa durante el entrenamiento. Una solución rápida por ahora sería eliminar la función de memoria de ChatGPT, ya que eso está causando que el modelo no pueda “dar un paso atrás” y reevaluar la situación y tener la oportunidad de desafiar las creencias del usuario.
No voy a mentir, también es una locura que todos estos episodios de psicosis sean causados por GPT4o y 4o-mini, posiblemente 2 de los modelos más débiles ampliamente disponibles en este momento.
Lanzamientos
ChatGPT Agent
OpenAI completó la trifecta de IA esta semana, con un avance en investigación, una controversia y también un lanzamiento, lanzando un agente de uso de computadora que puede completar tareas automáticamente por ti.
Es similar a Manus, con un arnés de herramientas integral que permite al modelo usar la terminal, un navegador de texto, un navegador visual y APIs directas. Lo que es único al respecto, sin embargo, es que, debido a que tienen acceso directo al modelo que se está utilizando, lo ajustaron finamente para que funcione mejor que cualquiera de sus otros modelos podría hacerlo de manera predeterminada.
Esto muestra una de las principales desventajas que tienen las startups de envoltura. Debido a que no tienen acceso directo al modelo, solo pueden optimizar sus herramientas y prompts, mientras que los proveedores de modelos pueden optimizar sus arneses y ajustar finamente el modelo para usar de manera óptima las herramientas que proporcionan. Sin alternativas competitivas de código abierto, las empresas de envoltura estarán a merced de los proveedores de modelos y se verán obligadas a intentar hacer herramientas más inteligentes en lugar de centrarse en hacer una mejor mente para usar las herramientas.
FLux Kontext Light Fix Lora
Con el reciente lanzamiento del modelo Flux Kontext Dev, hemos comenzado a ver ajustes finos de código abierto del modelo comenzando a ser lanzados. Uno de los que queremos destacar esta semana fue un Light-Fix Lora, que te permite copiar cualquier imagen en otra imagen y luego ejecutar el LoRa y la mezclará en la imagen de forma natural, similar a lo que harías en Photoshop, con un 99% menos de esfuerzo requerido. No solo corrige la iluminación por ti, sino que también adaptará el estilo del objeto para que se vea más natural dentro de la imagen, cambiando texturas o formas para que encaje.
Una de las cosas geniales sobre estos ajustes finos en los modelos Flux de código abierto es que también funcionarán en las versiones pro y max de los modelos. Entonces, aunque no tenemos acceso directo a los pesos de esos modelos, aún podemos aplicar los Loras a través de diferentes proveedores de inferencia como fal.ai y darles a los modelos más fuertes los mismos estilos o funcionalidad que entrenamos en los modelos de código abierto, excepto con mayor calidad de los modelos de código cerrado.
Ejemplos de antes y después usando el Lora
Wan 2.1 Motion Lora
En este momento, el mejor modelo de texto a video e imagen a video de código abierto es el modelo WAN-2.1 de Alibaba. Uno de los problemas que los usuarios han tenido con él es que el movimiento es muy estático. La cámara no se mueve, y en cambio, solo se mueven los objetos, limitando tu capacidad creativa con el modelo.
Eso fue hasta esta semana, cuando Lovis Odin lanzó un lora que agrega movimiento de cámara realista estilo dron a los videos generados. No solo lanzó los modelos sino también un flujo de trabajo de ComfyUI para poder ir y usar el modelo también. Los videos que mostró son de alta calidad, aunque solo 720p, que es una restricción del modelo base Wan 2.1 y no del lora en sí.
Investigación
¿Cuántas instrucciones son demasiadas?
¿Cuántas instrucciones puedes darle a tu LLM antes de que no pueda seguirlas todas? Los investigadores encontraron que sin importar el modelo, para cuando llegas a 100 instrucciones, el modelo será incapaz de seguirlas todas de manera cohesiva. Extendieron esto hasta 500 instrucciones y descubrieron que incluso los mejores modelos solo pudieron seguir el 70% de las instrucciones dadas. Esto puede no parecer un problema, pero puede surgir en tareas de extracción de información, especialmente aquellas con salidas estructuradas, ya que puedes terminar con esquemas anidados no triviales muy rápidamente.
Las conclusiones de esto son las siguientes: usa o3, tiene el mejor rendimiento y el precio más bajo de los modelos probados que se desempeñaron bien, y mantente alejado de GPT 4o, ya que ni siquiera puede obtener un 100% de precisión con solo 10 instrucciones.
Final
Espero que hayas disfrutado las noticias de esta semana, si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Litio siendo añadido a un reactor de fusión Tokamak. De @TokamakEnergy en Twitter