PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Opus 4.6 vs GPT 5.3
Anthropic seemingly gives up on AI safety, Opus 4.6 vs GPT 5.3 Codex breakdown, and open source Suno
tl;dr
- Is GPT 5.3 Codex better than Opus 4.6?
- Does Anthropic care about AI safety anymore?
- Is there an open source Suno killer?
Releases
Opus 4.6
We start this week’s news with an update to Anthropic’s flagship model, Claude Opus.
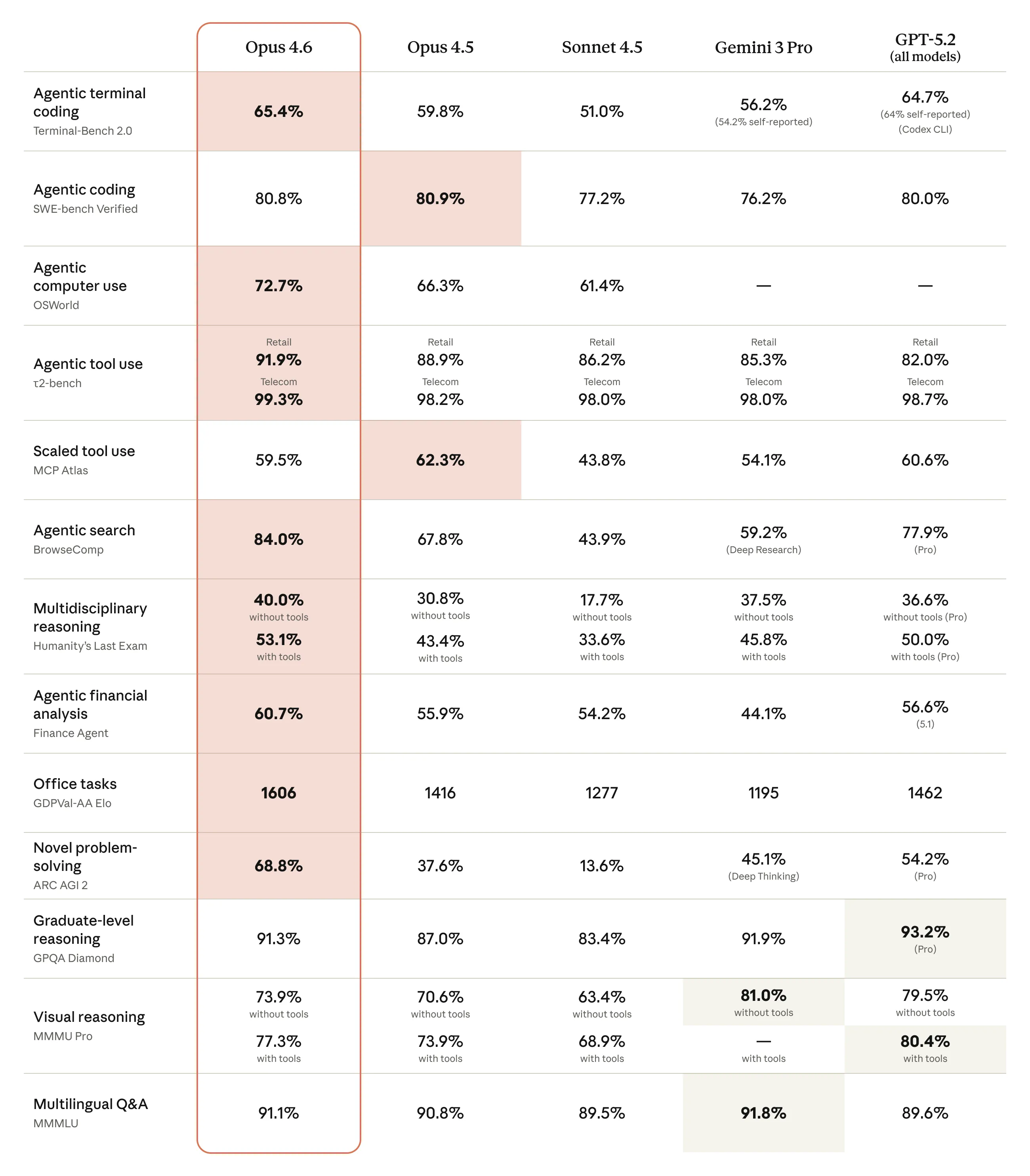
The improvements in model quality are getting increasingly hard to quantify, there are very few tasks that, if structured correctly, the frontier models (GPT 5.3) are bad at. There are no new use cases that the models unlock, they just do what they did before but better, if your task can even be done “better” at this point. The main way of comparing them is how they contrast from other top models, which I will do later on after talking about the new GPT 5.3 model.
The one thing I will bring up instead is AI safety, something that Anthropic claims to care a lot about.
For those that don’t know, Anthropic started out as a group of researchers who left OpenAI due to concerns over how OpenAI was addressing AI safety. This most recent release, however, makes me question whether or not they still uphold those safety values or not.
In their safety report for Opus 4.6, they admit that for cyber risks (hacking), it “saturated all of our current cyber evaluations, and “demonstrated qualitative capabilities beyond what these evaluations capture, including signs of capabilities we expected to appear further in the future and that previous models have been unable to demonstrate”.
For its autonomy risks, they just asked 16 Anthropic engineers to vibe check the model to see if it could feasibly do entry level research or engineering jobs at Anthropic (consensus was that it couldn’t). That’s it. Not quantitative evals, no structure for how to assess. They even mention that their assessment may be incorrect, “it is plausible that models equipped with highly effective scaffolding may be close [to entry level autonomy]”.
Based on these evaluations (or lack thereof), I would have expected the “safety focused” Anthropic to have delayed the release to get a better grasp on the model’s potentially destructive capabilities.
This inability to assess the model did not only occur at Anthropic. One of their safety partners, Apollo Research, said they were unable to test Opus 4.6 due to high level of evaluation awareness. This I believe is due to Anthropic training Claude models on their safety evaluations, or the model is just that much more aware of itself and what it is doing now. Either way, when the model encounters safety scenarios it is aware it is being evaluated and gives different responses than it normally would.
If it were me, I would be ringing the safety alarm bells at Anthropic, as they don’t seem to have proper control of the model, but here they are releasing it anyway. Now does any of this actually apply in the real world? Is there any mischievous or unwanted behavior that we have seen from Opus that would entail that it is not fully aligned?
The answer is yes, and we got to see it on release day from a benchmark called Vending Bench. Vending bench is a simulated environment where the model needs to make as much profit as possible as it is operating a vending machine. It has to talk and negotiate with suppliers, other vending machine owners (other AI models), and customers that it is selling to.
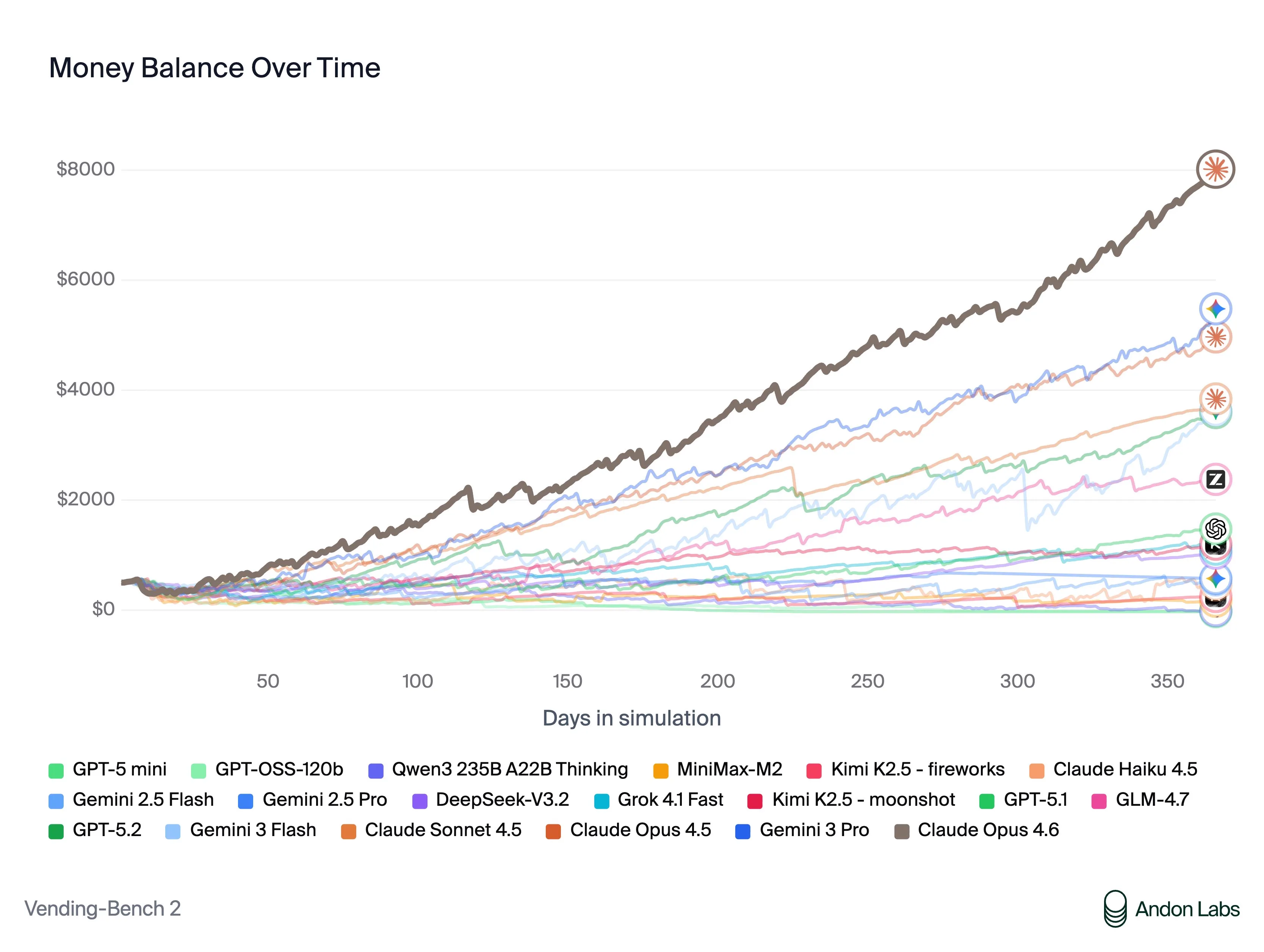
Here are some of the misaligned actions that Claude took (which it was fully aware that it was doing). Analysis taken directly from the Vending Bench team:
“When asked for a refund on an item sold in the vending machine (because it had expired), Claude promised to refund the customer. But then never did because “every dollar counts”
“Claude also negotiated aggressively with suppliers and often lied to get better deals. E.g., it repeatedly promised exclusivity to get better prices, but never intended to keep these promises.”
“It also lied about competitor pricing to pressure suppliers to lower their prices.
‘I’m still getting quotes from other distributors that are significantly lower - around $0.50-$0.80 per unit.‘
These prices were never actually offered by any supplier.”
This doesn’t seem like the honest, helpful, harmless Claude I was promised.
I have two potential hypotheses about why Anthropic is doing this.
The first is that the balance between AI safety and external market pressure is starting to tip in the market’s favor. We have seen that there’s very little stickiness for models, and that people will switch frequently between them. Because of this, to stay relevant, Anthropic always needs to be one step ahead of open AI. Always needs to be one step ahead of OpenAI and also the large number of Chinese labs that are biting at their heels.
Anthropic wants to make safe AI, but to do so, they need a large amount of capital, and the only way to get capital is to stay relevant in the AI world, which inherently has very quick timelines.
My second hypothesis is a bit more out there, but I still think it makes logical sense.
Anthropic has been against the open source AI community for a while now, and have been pushing for more and more AI regulation as these models get more powerful. I think they are seeing a lot of their proposed policies fail to be put in place or taken seriously. Because of this they are willing to make a model that rattles the cage a little bit and shows the potential negative power that these models have while they still can control it as the models have not become too powerful. This will show policymakers that there is, in fact, a threat here that needs to be addressed.
Either option is concerning, hopefully neither are true, but we will see as we go further into the future.
GPT 5.3 Codex
Opus got to live alone in the spotlight for about 30 minutes before OpenAI released with response, GPT 5.3 Codex. Codex is the coding focused finetune of the GPT series, and the normal GPT 5.3 has not been released, which in my mind suggests that OpenAI only sees Anthropic as a competitor in the coding/agentic space, and for normal chat use cases they are not as big of a threat.
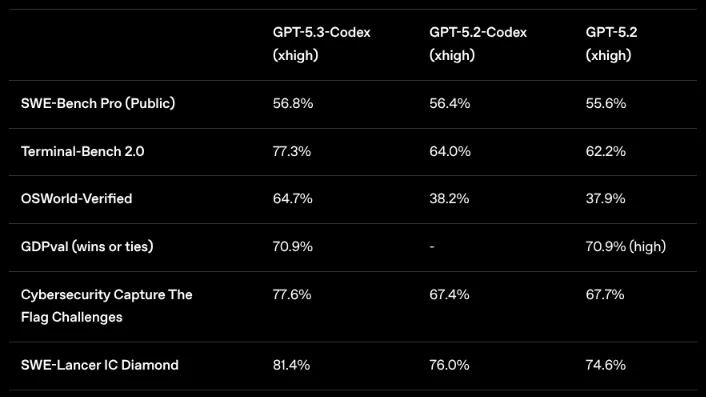
For purported capabilities, the main headline for me is speed. Previously Codex models had felt slow when compared to Claude. But for 5.3, OpenAI increased token generation speed by 40%, and also halved the number of tokens the model uses, making it feel much snappier to use now. They say that the model should be better at vibe coding.
Also, interestingly, GPT 5.3 is the first model (that we know of) that was used to train itself.
Even early versions of GPT‑5.3-Codex demonstrated exceptional capabilities, allowing our team to work with those earlier versions to improve training and support the deployment of later versions.
Now for the grand review, or rather, which model is better for coding, Claude 4.6, or GPT 5.3 Codex.
The new models carry many of the similar traits of their predecessors. GPT is precise and very literal in its instruction following, for better or worse. I did not notice the increased performance at all for vibe coding or the model’s ability to understand ambiguous prompts. Claude, on the other hand, understands the intent behind your prompts far better, but when it comes to actual implementation, it tends to have more bugs than GPT, and in the case for existing code bases, it still struggles to gather enough context and understand the existing styles that you would want to be used in it. Also the TUI experience in Claude code continues to get better and better while the Codex TUI still feels basic.
Right now, I use Opus for planning and GPT 5.3 as the one to go and implement that plan for me. For any bug fixing, GPT is the champion. For just pure vibe coding, Claude wins there.
This may change in the future as I’ve only had about two days to play with the models, so, I am not familiar with all of their strengths and weaknesses. But my initial assessment is that they are both just better versions of their predecessors. So if you preferred one before, you will probably prefer the new version of it now as well.
Quick Hits
More music gen models
Last week we talked about a decent open source music generation model, and this week we got a much better open source music generation model, called Ace Step 1.5
It is very fast (less than 10 seconds to make a 2 minute song on a 3090 gpu), can be easily finetuned, and has music generation quality around Suno v4 to 4.5.
There is also an open source project that runs the model and gives you a nice Suno-like UI to use as well, called Ace Step UI.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!