PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
GPT 5.2 Vibe Check
How good is GPT 5.2? Has Mistral turned themselves around in only a week? GLM releases 3 new models, and new benchmarks for real world RAG
tl;dr
- Is GPT-5.2 a big jump, or another small performance bump?
- Can Mistral recover from their poor releases last week?
- Your prompts may not actually be helping you.
- And more!
Releases
GPT 5.2
Less than a month after the release of GPT 5.1, OpenAI has released GPT 5.2.
Based on the benchmark scores it is much more than the small performance and personality tweaks that GPT 5.1 was.
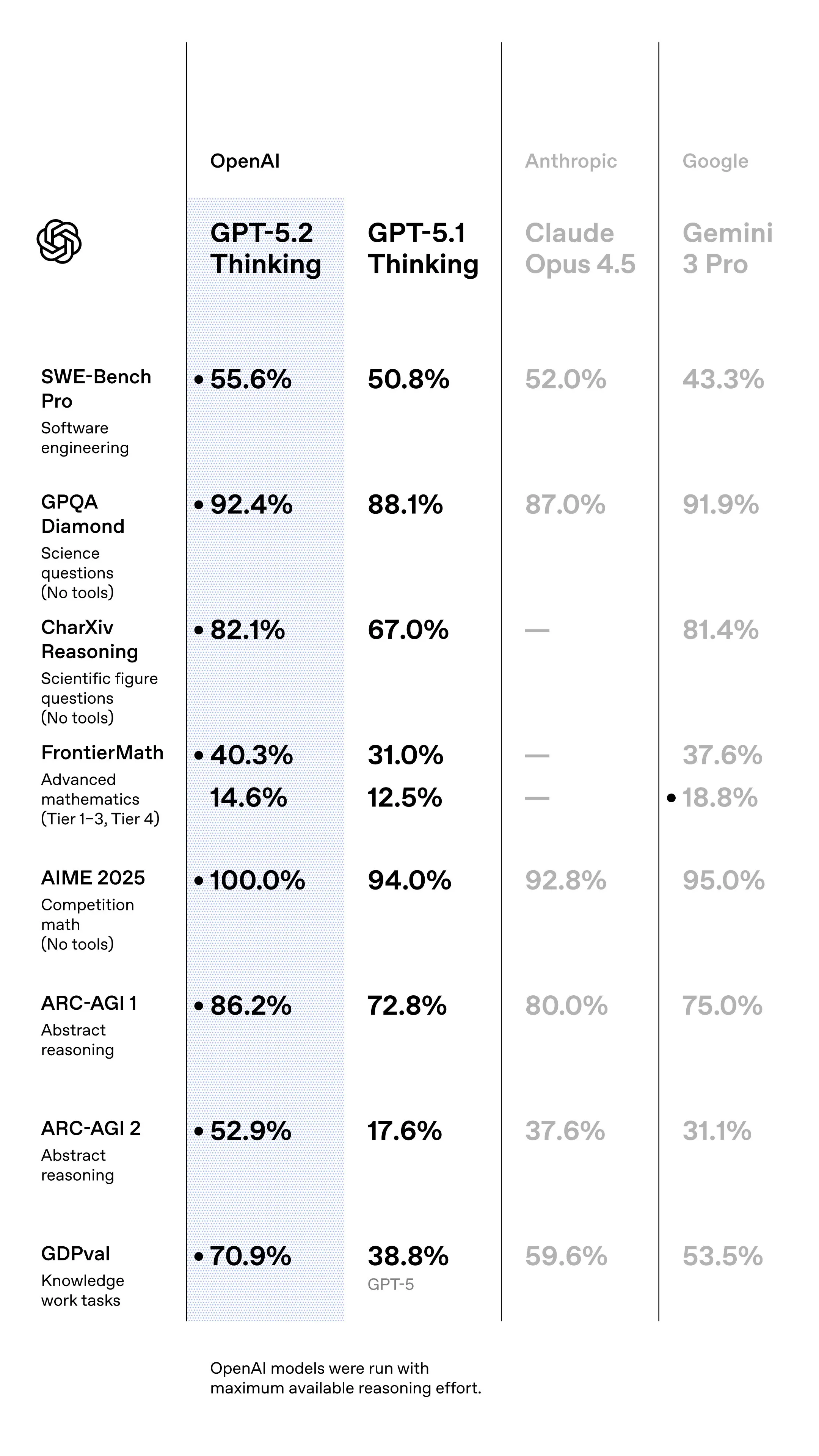
In real world use, the model seems to be a step up from GPT 5.1, but still not at the same level of quality that Opus 4.5 is, and not as revolutionary as the benchmarks make it seem.
It also inherits the capabilities of the 5.1 Codex models, making it a strong coding model, and also streamlines the lineup to that there is one model you use for all use cases instead of the 3 that they had.
This increase in performance also does not come for free, as they have increased the pricing to $14 per million.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| Claude Opus 4.5 | $5 | $25 | 69 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GPT 5.1 | $1.50 | $10 | 34 |
| GPT 5.2 | $1.75 | $14 | 38 |
As a general chatbot, there has been a lot of talk that the model is much colder now and reverted back to a more bland style of conversation that many users do not like when compared to 5.1 or 4o.
Overall its a another bump in capabilities, but not revolutionary. If you are already using GPT for coding it should be a bit better, as a chatbot its a bit worse, and for production use cases its increased price makes it ambiguous if its worth upgrading to.
Mistral is Back?
Last week we talked about how Mistral seems to be falling off given the poor performance of their Mistral 3 series of models
This week they released a pair of models as a part of their coding line called Devtral.
The first model is a “small” 24 billion parameter dense model called Devstral Small 2. The other model is a 123B parameter dense model called Devstral 2.
The 123B parameter model has an interesting architecture. Most models in the 100B+ parameter range tend to be mixture of experts (MoE) models, as they provide much higher speeds than a similarly sized dense model.
This speed does come at the cost of extra engineering effort, so this could mean that Mistral is struggling to train MoE or they find the extra effort not worth it.
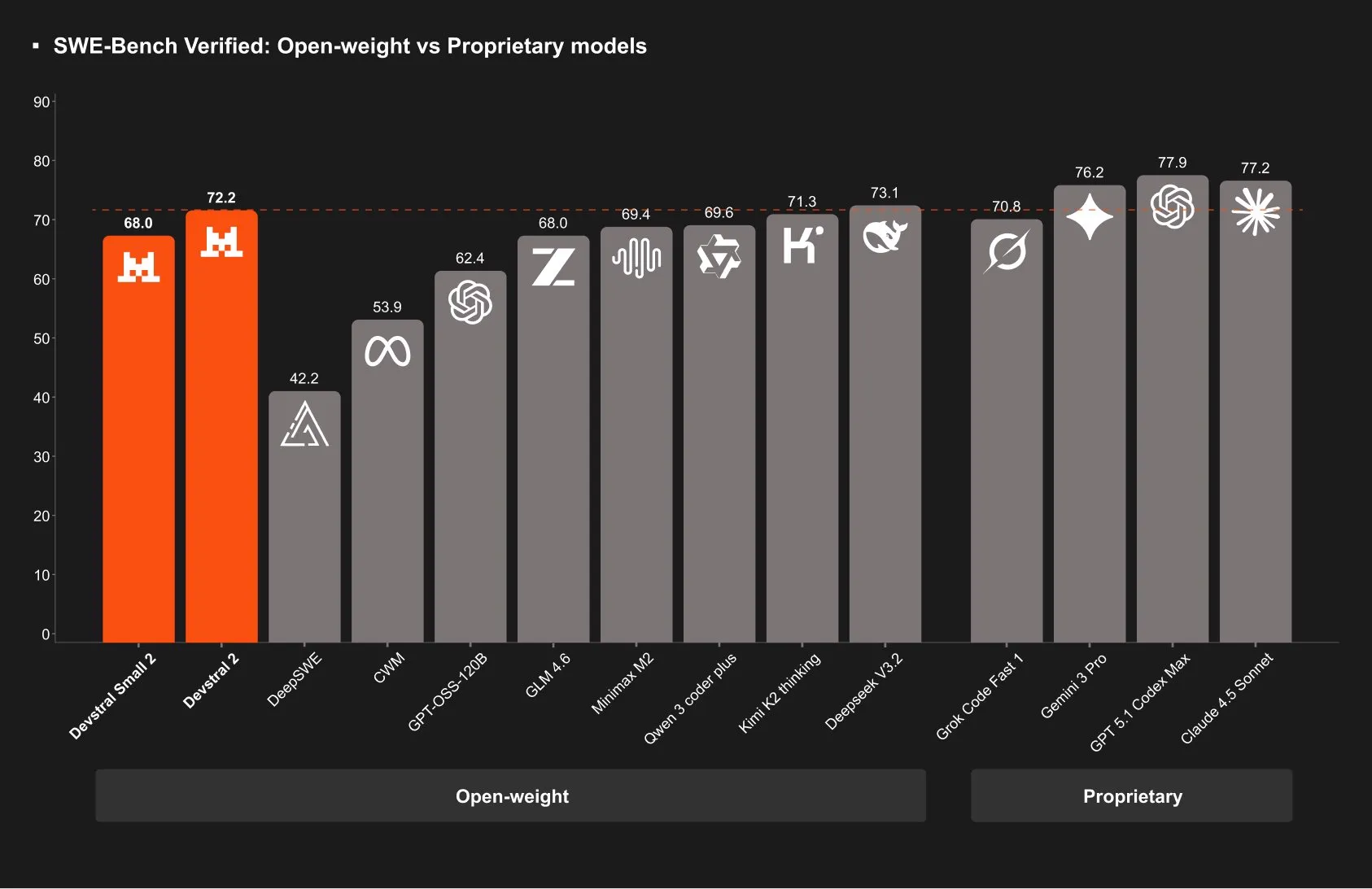
The models seem decent for their size, although not a leap above the other models like their benchmark scores entail.
The small model is competitive with Qwen 3 Coder 30B, and the large model is also fairly usable given its size, although does not seem as good as GLM 4.5 Air.
Neither model stands out however when compared to the competition, and because they are dense models instead of MoE’s, that means they will be substantially slower, which is what you would want when using a small model.
There is also the issue of the license. They use a modified MIT license, which states that if you are a part of a company that makes more than 20 million a year in revenue, then you need a commercial license for the model. This also technically applies to personal use as well.
That means that if you are a employee at a school or researcher, than you cannot use this model. (Calling this a modified MIT license is a very generous interpretation of what an MIT license is).
Compared to last week’s model, these models are at least about on par with their competition, but the lack of MoE versions and also the poor licensing still makes me concerned for the future of Mistral.
Quick Hits
GLM 4.6V
GLM has released an updated version of their vision model GLM 4.5V.
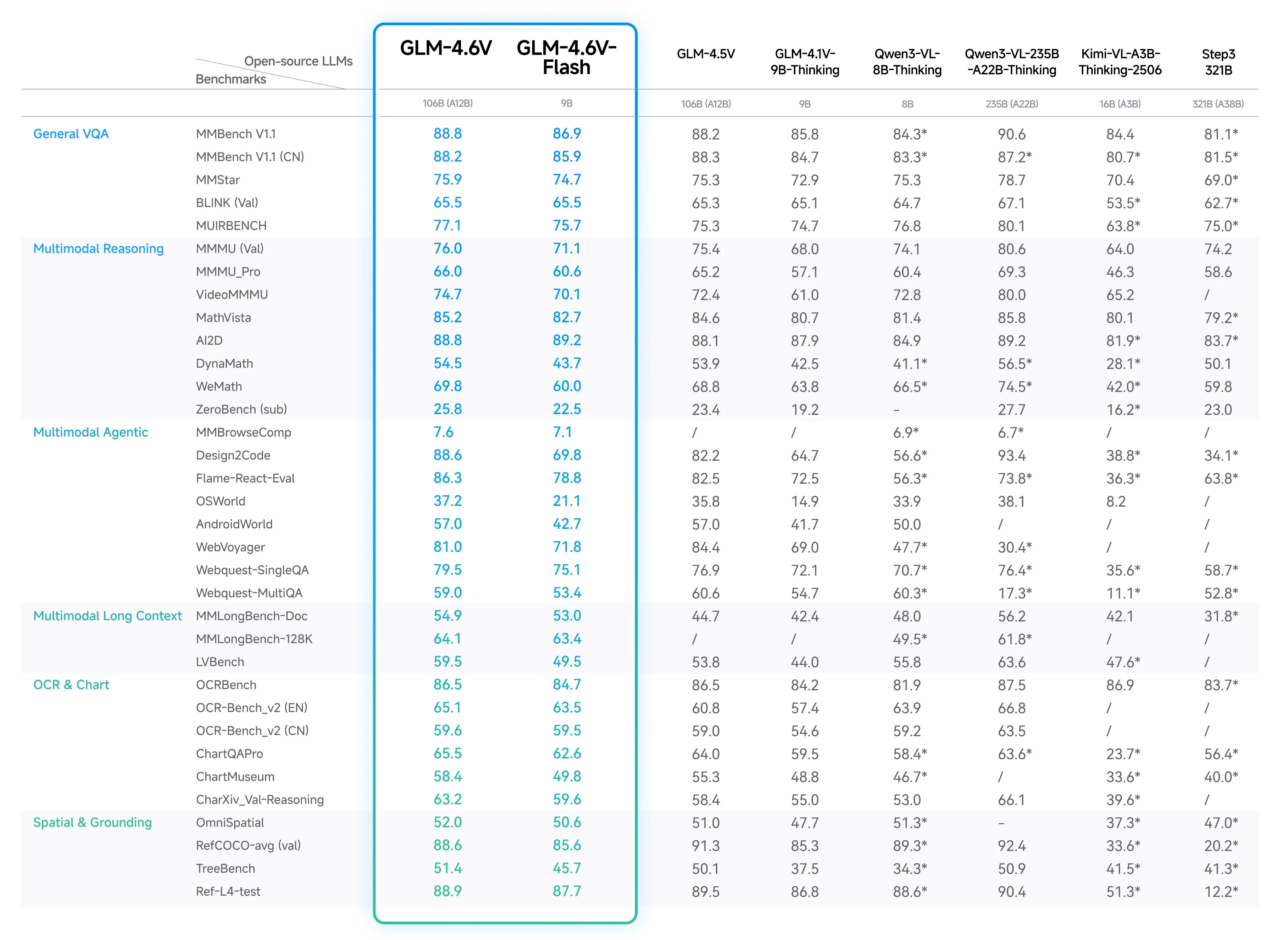
Despite the name, it is not based on the large GLM 4.6 model, but instead the small GLM 4.5 Air model. This makes it a 108 billion parameter MoE model with 12 billion parameters.
They also released a smaller 9B dense version called GLM 4.6V-Flash.
They benchmark well for their size, with the 9B being SOTA and the 108B model being competitive with models in the 100-300B range.
Persona Prompting Does Not Work
Many people will prompt their models wit something like “You are an expert senior software engineer…” and say or expect the model to perform better. This is known as persona prompting.
Researchers have found that this does not actually improve the model at all, and can even hurt performance instead.
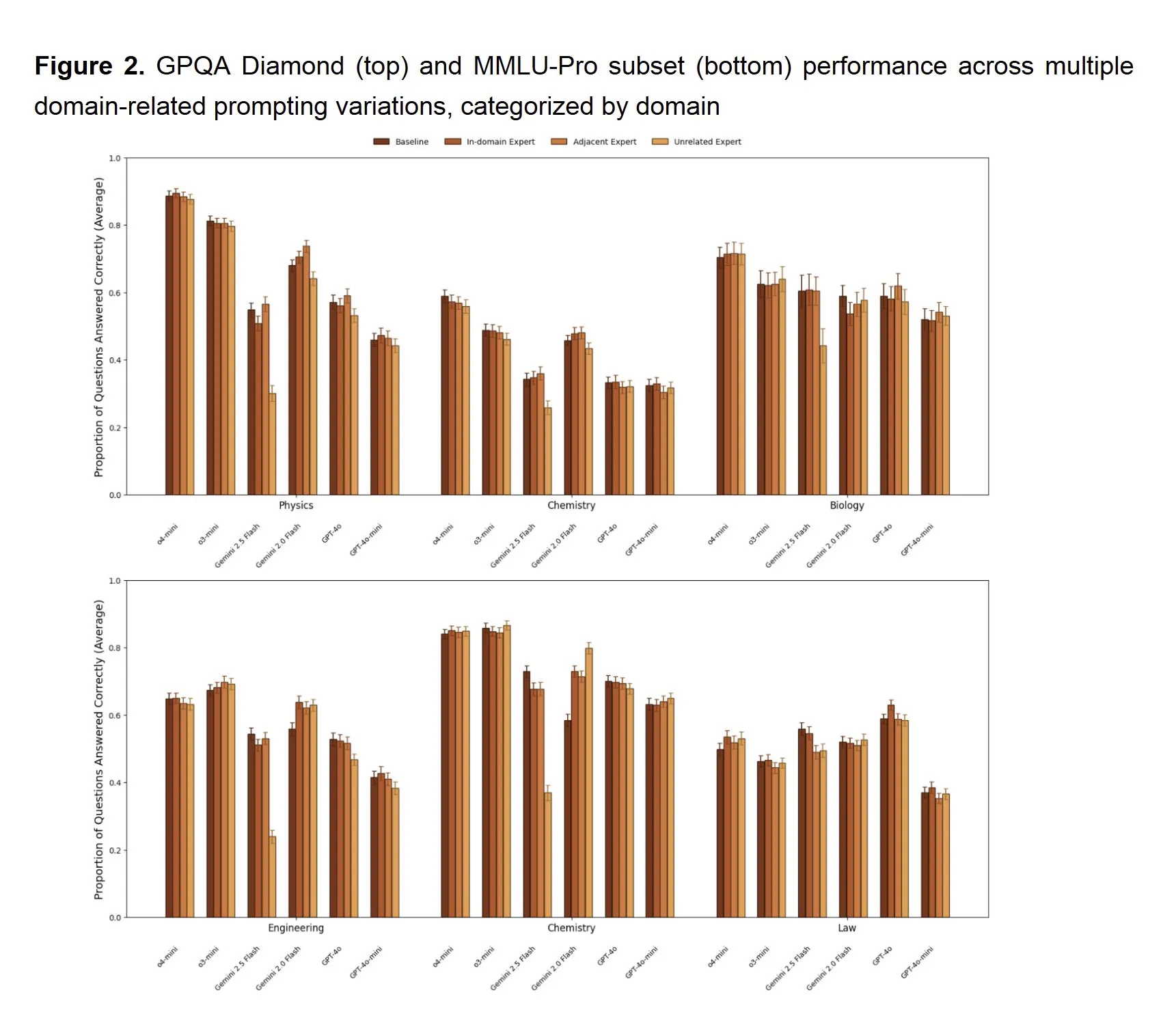
It does however change the style of the output, which can be useful depending on what you are looking for. For instance you may want more or less comments in your code.
If this is what you want, you should be telling it to answer for a specific audience instead.
OfficeQA
Databricks has released a benchmark measuring the performance of models on real world tasks that models and agents would be expected to do in an enterprise setting, including data analysis, reasoning over large pdfs, chart understanding, and web search.
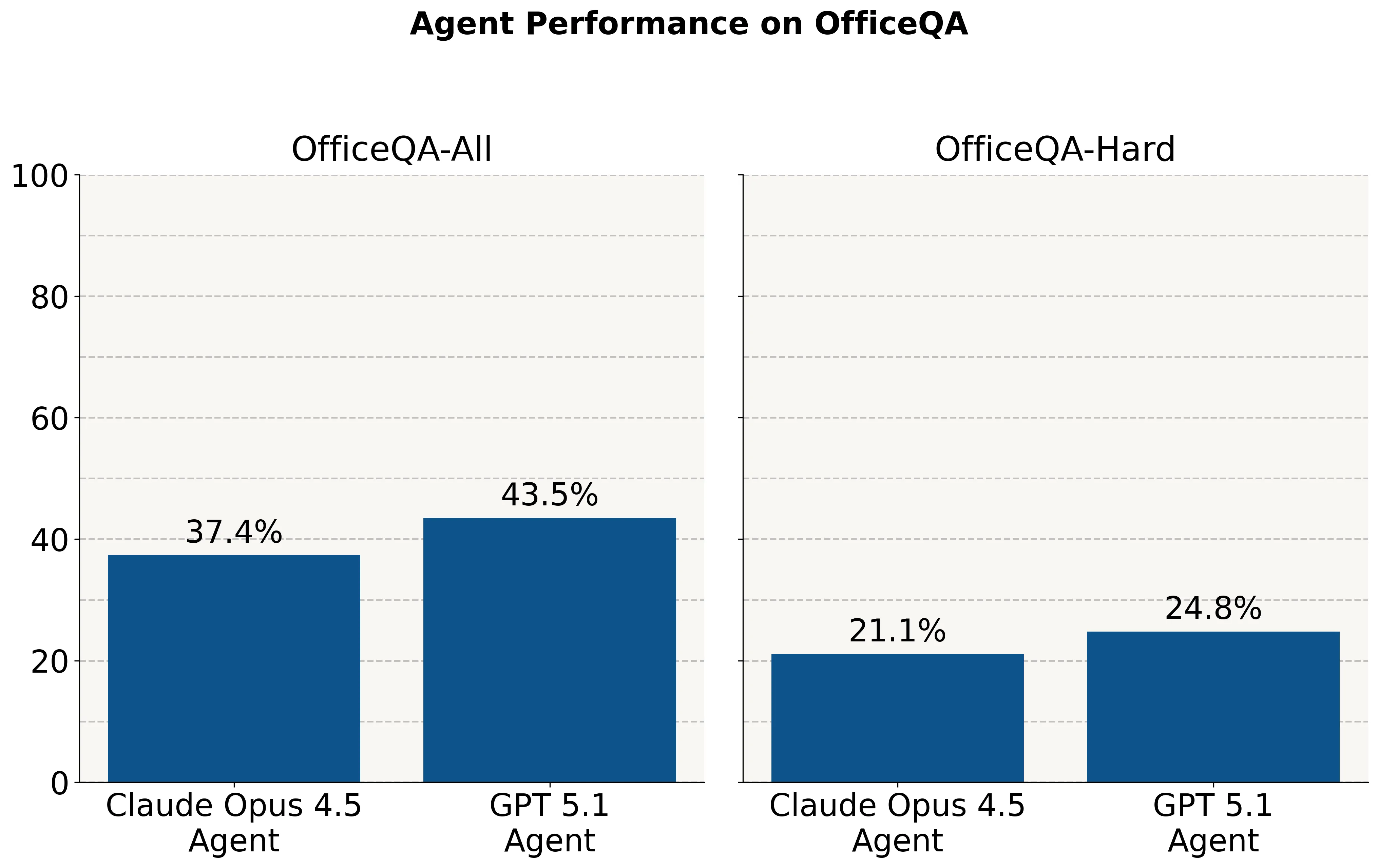
They find that even frontier models struggle on these real world tasks and there is still a lot of room to grow even for easier questions.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!




