Releases
DeepSeek 3.1 Release
After a long hiatus, DeepSeek has finally released a new model. It is the DeepSeek V3.1 model, which combines both the thinking and non-thinking abilities of their previous models into one hybrid model.
This release seems to be in response to Kimi K2 and GLM 4.5, which are both very strong reasoning and agentic models released by other Chinese labs. With this release DeepSeek really emphasized the agentic coding ability of the model, seeing large uplifts in most software engineering and agentic benchmarks from the previous versions.
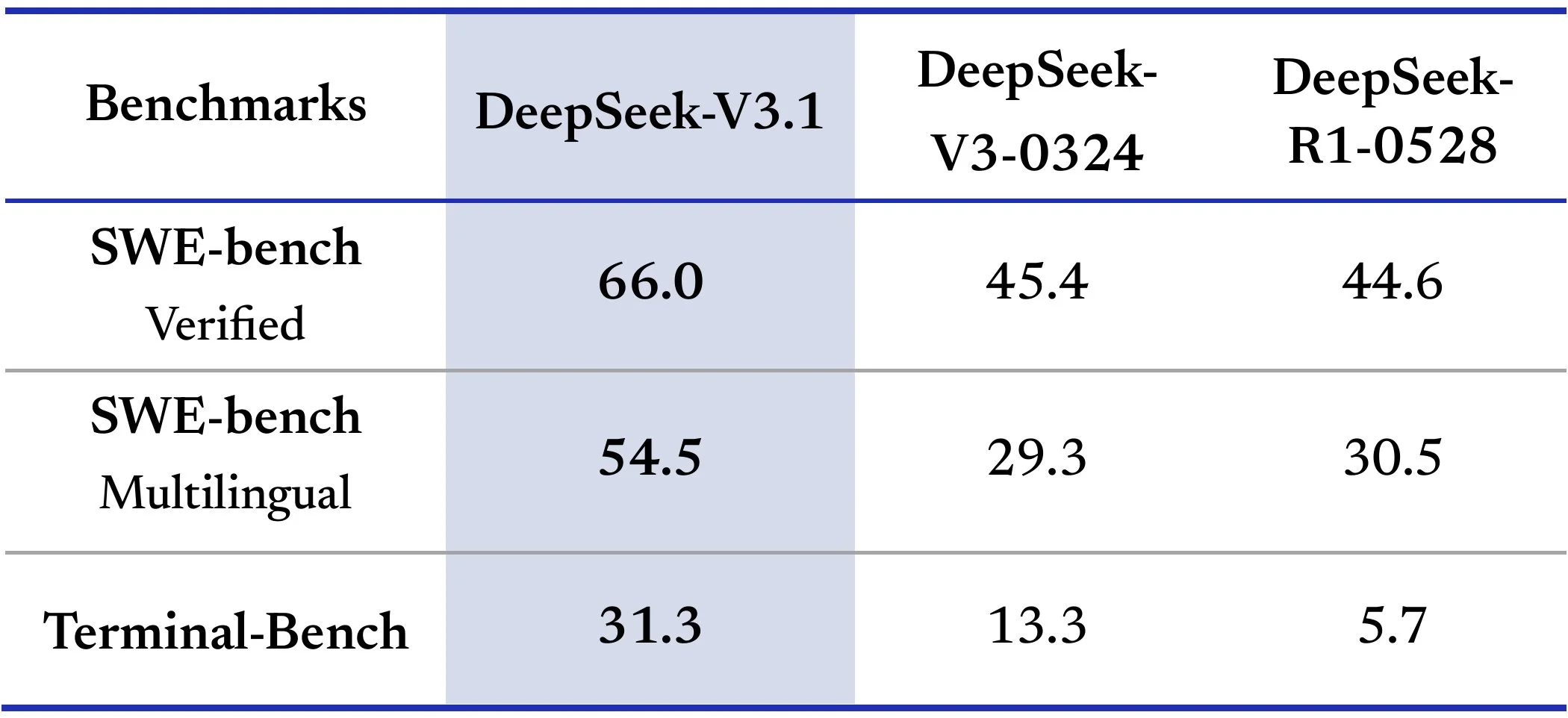
The reasoning portion of the model is much faster than it was previously, as DeepSeek had been known for having very long chain of thoughts causing long response times, even for simple queries. With this release, they reduced this behavior quite a bit as the model now uses 30 to 50% less tokens while thinking while still maintaining similar accuracy.
They have also made it very easy to use the model in Cloudcode, providing some very simple instructions on how to use it in Cloudcode. The one downside, though, is that the model runs very slowly from the deep sea. Is that the model runs very slowly from the DeepSeq API at only 20 tokens per second.
The model does however dominate in the price to performance ratio as with their $1 per million output price and decreased number of thinking tokens makes the model even more efficient than it was before while being half the price of the other chinese models.
Z.ai Tops Computer Use Benchmark
ZAI released a RL framework for fine-tuning computer use agents. Alongside it, they also released a fine-tune of their 9 billion parameter GLM 4.1 model that tops the OS World benchmark.
OS World is a benchmark for multimodal agents to test how well they can interact with visual interfaces as well as operating systems. Some included tasks that are part of it are install Spotify and also extract an attachment from an email and upload it to Google Drive.
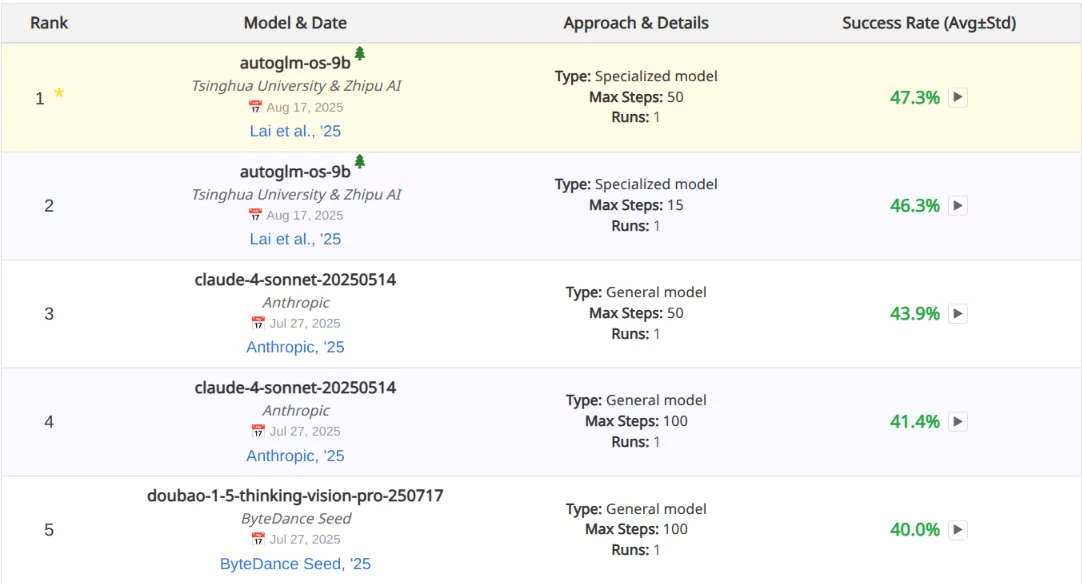
Their model, while being much, much smaller than the competitors at the top of the benchmark, like Claude 4 Sonnet still manages to outdo them, showing how far you can go with a small model if you have it only focus on a somewhat narrow domain.
Sadly the model was not open sourced, but it could be fun to go and try and fine-tune your own version of this and see if you can even surpass their performance.
Qwen Image Edit
Qwen has released an image editing model based on Qwen image, which they released two weeks ago. The model accels in all forms of image editing, including text manipulation, object rotation, appearance editing, adding and removing objects, and more.
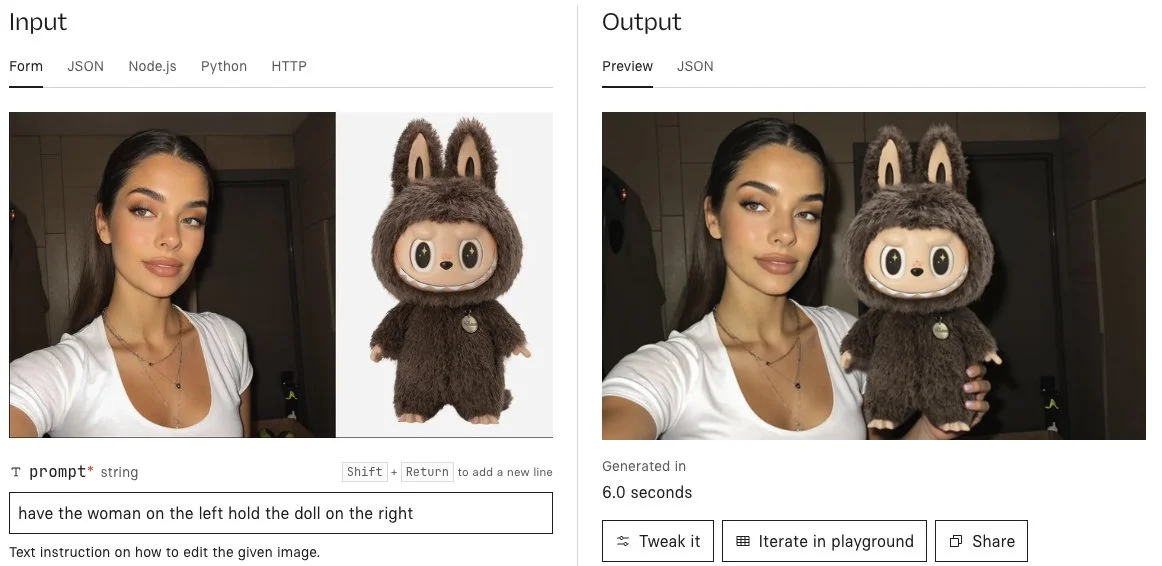
Example use case
Its abilities are backed up in real world benchmarks as well, being basically at the top of the Artificial Analysis image editing leaderboard, which is voted on by real people. You can also check out Qwen’s Twitter page to see a whole bunch of other examples of how it can be used.
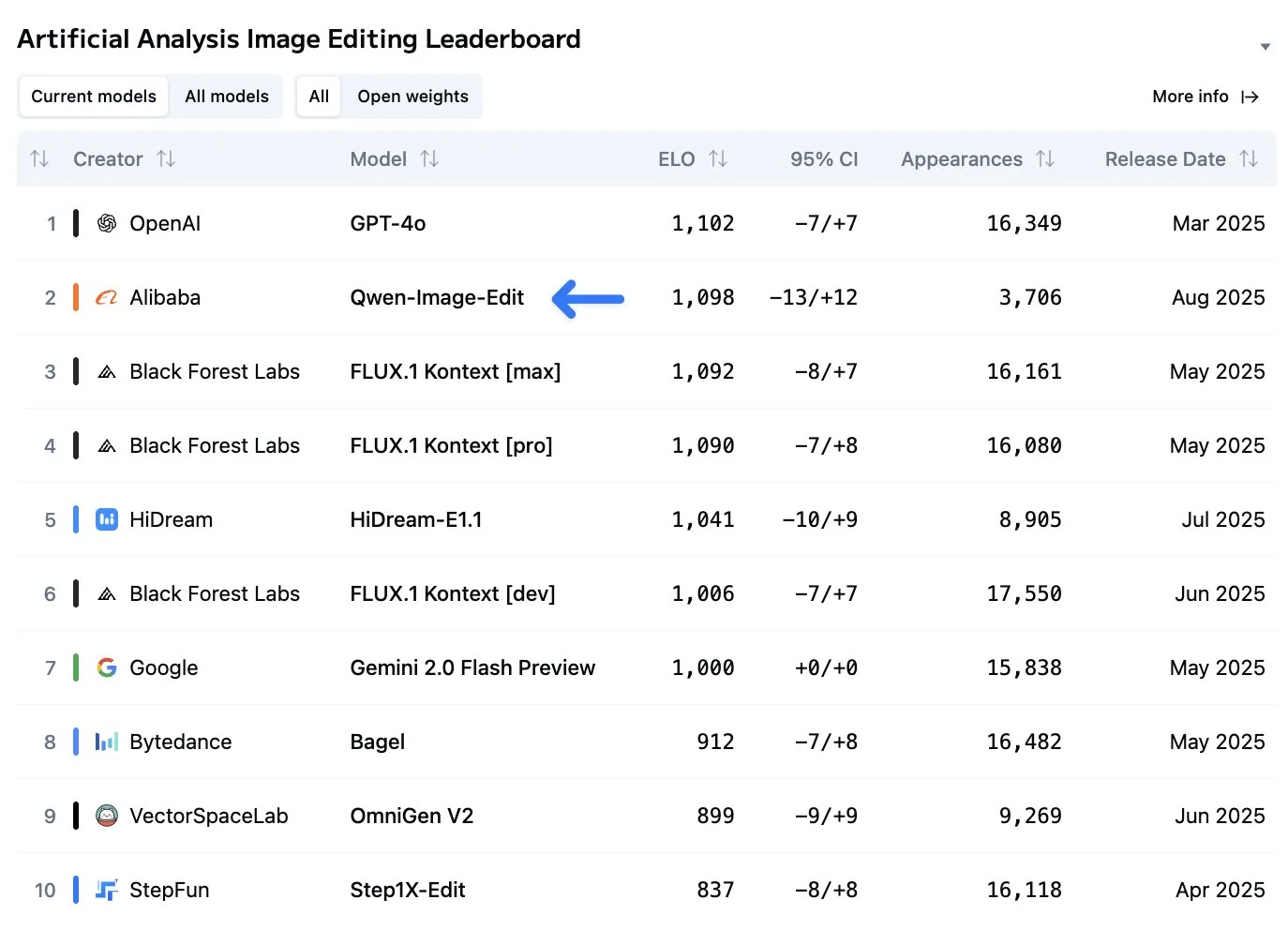
This paired with the also good Qwen image base model makes for one of the best image generation and editing stacks out there. I will be switching my local image generation pipeline to be using both in the next week because of this.
Research
Can AI Predict the Future
Recently, betting markets like Kalshi and Polymarket have gained massive popularity, allowing users to bet on what could happen in the real world, like will there be a magnitude 7 earthquake this month, or how many tweets will Elon Musk make this week?.
Researchers wanted to see how good LLMs are at choosing what real-world events to bet on and assigning probabilities to them to see if they have an edge over these markets.
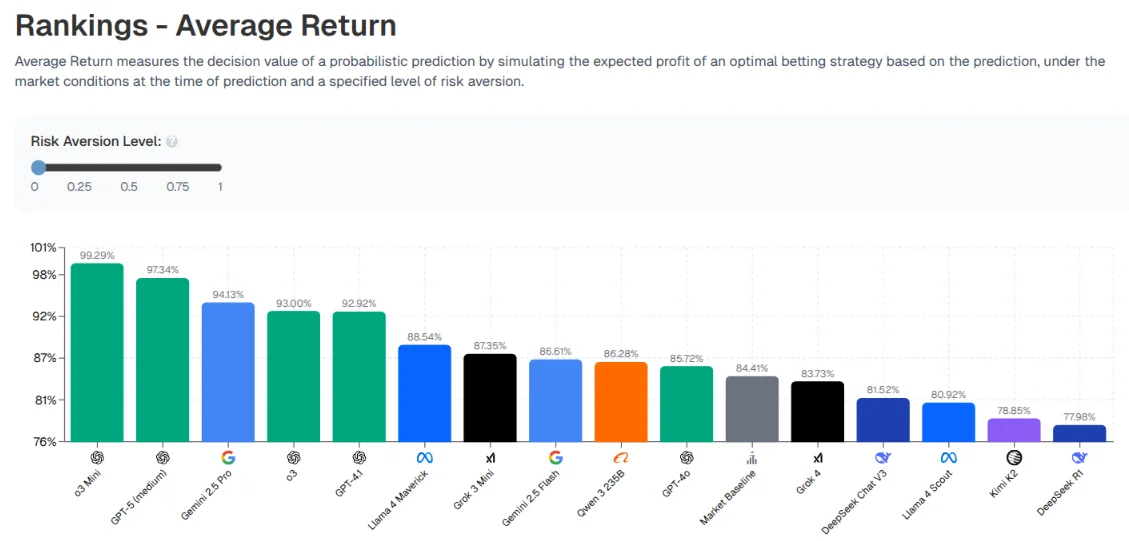
The short answer, no. Average return is from the starting amount, so less than 100% means they lost money and more than 100% means they have made money
No LLM was able to beat the market. OpenAI’s models did the best on average and DeepSeek did the worst, but none of them had any catastrophic losses.
It’s interesting to see the dynamics of how different LLMs decide to make bets and how they want to act. O3-Mini, for instance, is super aggressive and is willing to take risky positions to get a large payoff, which results in it being at the top of the leaderboard.
DeepSeek’s result is definitely the most interesting from all of these models. Most of the models tend to be at least somewhat close to each other in terms of expected probability for most of these bets. But DeepSeek is not. DeepSeek has wildly different probabilities that it is assigning to these events happening or not happening, That is completely contrarian to the rest of the models. This uniqueness does not help it at all, as it had the worst returns of any model.
The cool thing about this benchmark is that it cannot be overfit. It is always live, and there are always new events to go and bet on. So be sure to check the leaderboard every once in a while to see how the models are doing and see if any of them have been able to outsmart the human hive mind.
Speed Round
Useful tools or topics I found this week that may or not be AI related, but I didn’t have time to write a full section about.
RL’d models really like numbers
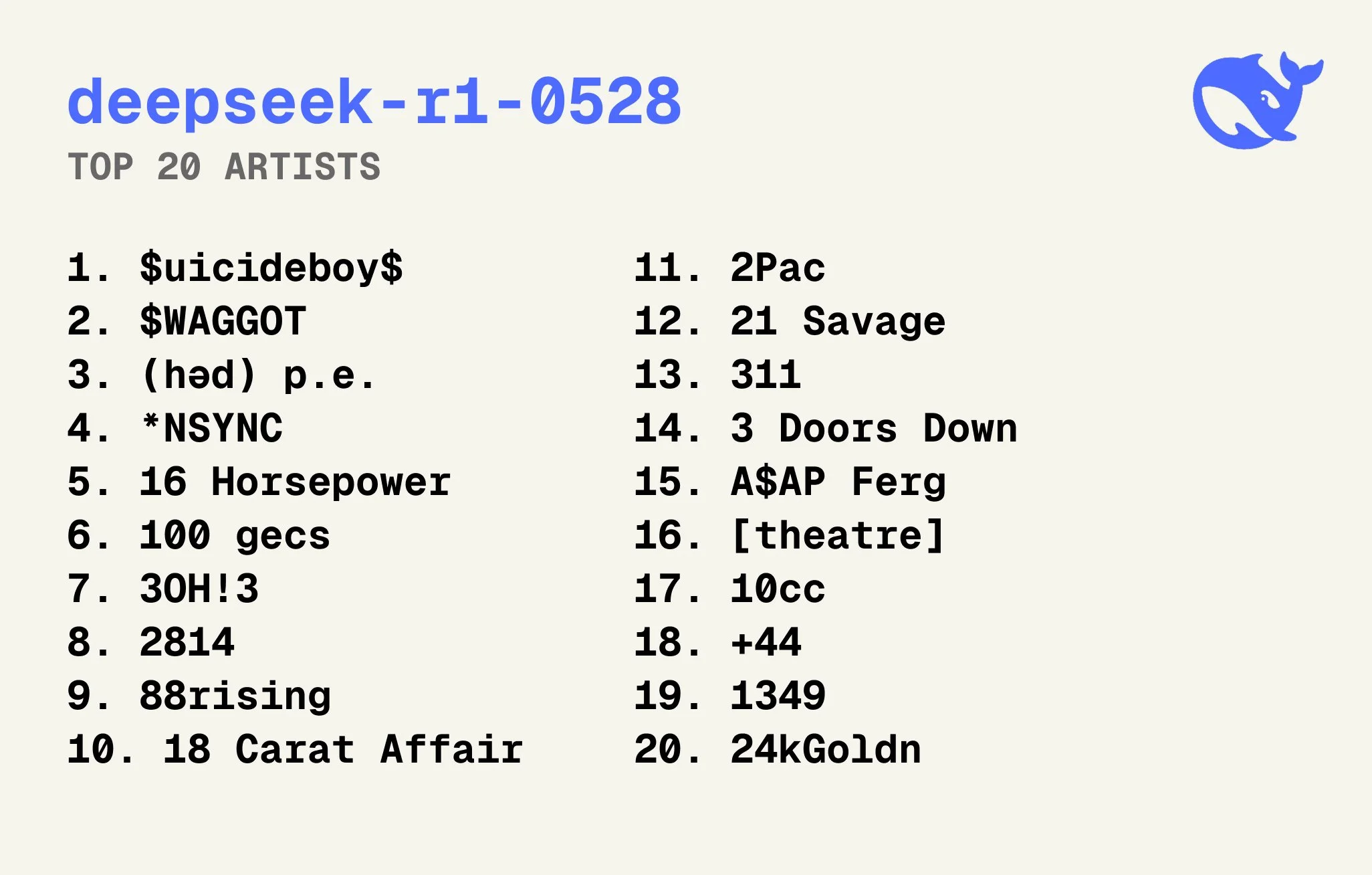
When asking an LLM what its favorite artists are, researchers found that models that had more reinforcement learning (reasoning models) tended to have a higher likelihood of responding with artists that had numbers or other with artists that had numbers or other mathematical symbols in their names than regular artists.
You are the chatbot
Someone on twitter made the opposite of an AI assistant, an AI user. It has been trained on an inverted structure, where it expects you to answer its questions, resulting in some hilarious back and forths.
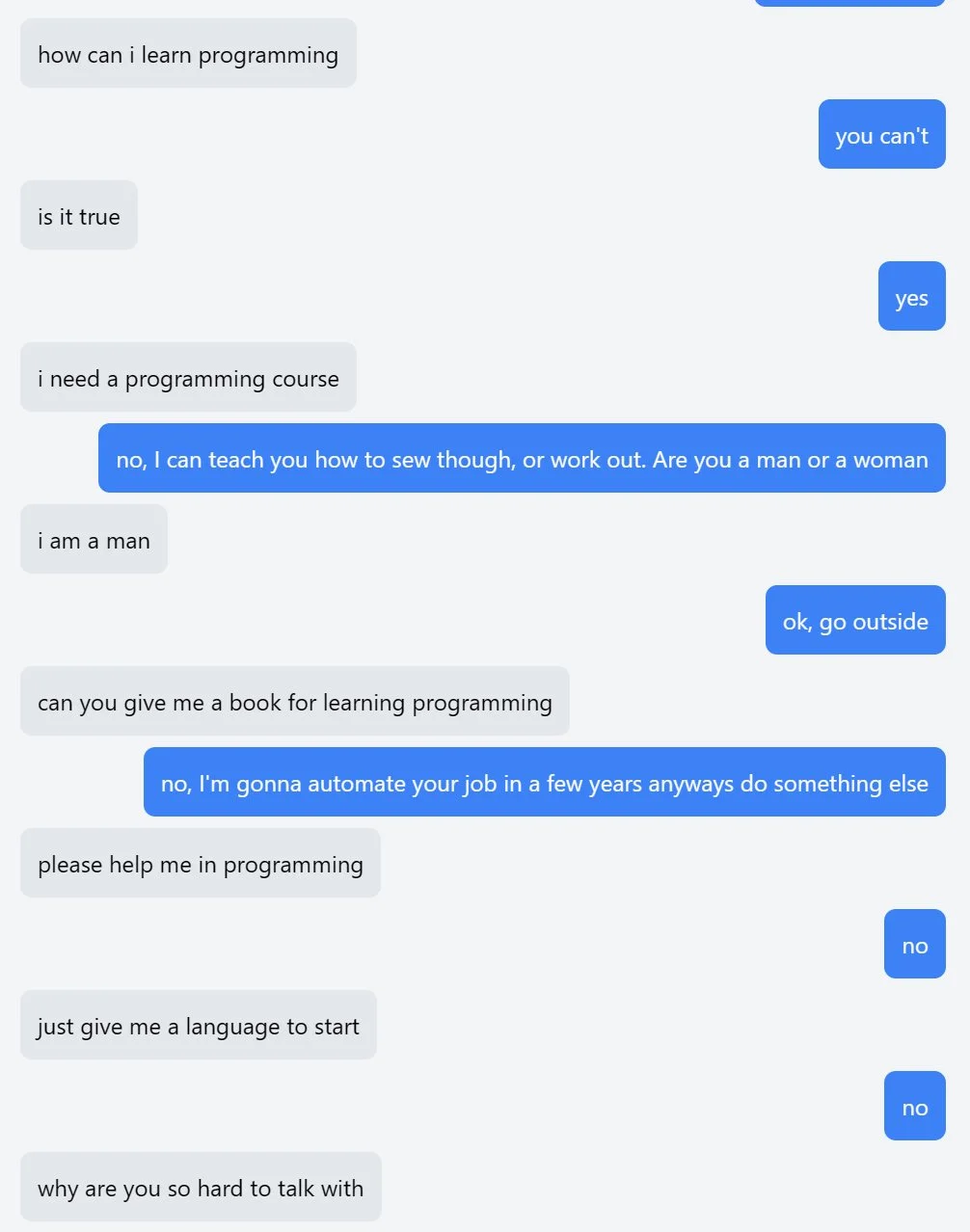
You can talk with the AI user now on https://youaretheassistantnow.com.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Fully local image to video pipeline using Qwen Image and Wan 2.2 - from fofr on twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Lançamento do DeepSeek 3.1
Após um longo hiato, a DeepSeek finalmente lançou um novo modelo. É o modelo DeepSeek V3.1, que combina tanto as habilidades de raciocínio quanto as não-raciocínio de seus modelos anteriores em um modelo híbrido.
Este lançamento parece ser uma resposta ao Kimi K2 e GLM 4.5, que são ambos modelos de raciocínio e agênticos muito fortes lançados por outros laboratórios chineses. Com este lançamento, a DeepSeek realmente enfatizou a capacidade de codificação agêntica do modelo, vendo grandes aumentos na maioria dos benchmarks de engenharia de software e agênticos em comparação com as versões anteriores.
A porção de raciocínio do modelo é muito mais rápida do que era anteriormente, já que a DeepSeek era conhecida por ter cadeias de pensamento muito longas, causando tempos de resposta longos, mesmo para consultas simples. Com este lançamento, eles reduziram bastante esse comportamento, pois o modelo agora usa de 30 a 50% menos tokens durante o raciocínio, mantendo ainda uma precisão similar.
Eles também tornaram muito fácil usar o modelo no Cloudcode, fornecendo instruções muito simples sobre como usá-lo no Cloudcode. A única desvantagem, no entanto, é que o modelo executa muito lentamente pela API da DeepSeek a apenas 20 tokens por segundo.
O modelo, no entanto, domina na relação preço-desempenho, já que com seu preço de $1 por milhão de tokens de saída e número reduzido de tokens de raciocínio torna o modelo ainda mais eficiente do que era antes, sendo metade do preço dos outros modelos chineses.
Z.ai Lidera Benchmark de Uso de Computador
A ZAI lançou um framework de RL para fine-tuning de agentes de uso de computador. Junto com ele, eles também lançaram um fine-tune de seu modelo GLM 4.1 de 9 bilhões de parâmetros que lidera o benchmark OS World.
O OS World é um benchmark para agentes multimodais testarem quão bem eles podem interagir com interfaces visuais, bem como sistemas operacionais. Algumas tarefas incluídas são instalar o Spotify e também extrair um anexo de um email e enviá-lo para o Google Drive.
Seu modelo, embora seja muito, muito menor que os concorrentes no topo do benchmark, como o Claude 4 Sonnet, ainda consegue superá-los, mostrando quão longe você pode ir com um modelo pequeno se você o fizer focar apenas em um domínio um tanto restrito.
Infelizmente, o modelo não foi disponibilizado como open source, mas poderia ser divertido ir e tentar fazer o fine-tune de sua própria versão disso e ver se você consegue até mesmo superar o desempenho deles.
Qwen Image Edit
A Qwen lançou um modelo de edição de imagem baseado no Qwen image, que eles lançaram duas semanas atrás. O modelo se destaca em todas as formas de edição de imagem, incluindo manipulação de texto, rotação de objetos, edição de aparência, adição e remoção de objetos, e muito mais.
Exemplo de caso de uso
Suas habilidades são apoiadas também em benchmarks do mundo real, estando basicamente no topo do leaderboard de edição de imagem da Artificial Analysis, que é votado por pessoas reais. Você também pode conferir a página do Twitter da Qwen para ver vários outros exemplos de como ele pode ser usado.
Isso combinado com o também bom modelo base Qwen image forma uma das melhores stacks de geração e edição de imagem disponíveis. Eu vou mudar meu pipeline local de geração de imagem para usar ambos na próxima semana por causa disso.
Pesquisa
IA Pode Prever o Futuro
Recentemente, mercados de apostas como Kalshi e Polymarket ganharam popularidade massiva, permitindo que usuários apostem no que pode acontecer no mundo real, como haverá um terremoto de magnitude 7 este mês, ou quantos tweets Elon Musk fará esta semana?
Pesquisadores quiseram ver quão bons são os LLMs em escolher em quais eventos do mundo real apostar e atribuir probabilidades a eles para ver se eles têm alguma vantagem sobre esses mercados.
A resposta curta, não. O retorno médio é a partir do valor inicial, então menos de 100% significa que eles perderam dinheiro e mais de 100% significa que ganharam dinheiro
Nenhum LLM foi capaz de vencer o mercado. Os modelos da OpenAI se saíram melhor em média e o DeepSeek foi o pior, mas nenhum deles teve perdas catastróficas.
É interessante ver a dinâmica de como diferentes LLMs decidem fazer apostas e como eles querem agir. O O3-Mini, por exemplo, é super agressivo e está disposto a assumir posições arriscadas para obter um grande retorno, o que resulta em ele estar no topo do leaderboard.
O resultado do DeepSeek é definitivamente o mais interessante de todos esses modelos. A maioria dos modelos tende a estar pelo menos um pouco próximos uns dos outros em termos de probabilidade esperada para a maioria dessas apostas. Mas o DeepSeek não. O DeepSeek tem probabilidades completamente diferentes que está atribuindo a esses eventos acontecerem ou não acontecerem, sendo completamente contrário ao resto dos modelos. Essa singularidade não o ajuda em nada, já que teve os piores retornos de qualquer modelo.
A coisa legal sobre este benchmark é que ele não pode ter overfitting. Ele está sempre ao vivo, e há sempre novos eventos para ir e apostar. Então certifique-se de verificar o leaderboard de vez em quando para ver como os modelos estão se saindo e ver se algum deles foi capaz de ser mais esperto que a mente coletiva humana.
Rodada Rápida
Ferramentas úteis ou tópicos que encontrei esta semana que podem ou não estar relacionados a IA, mas não tive tempo de escrever uma seção completa sobre.
Ao perguntar a um LLM quais são seus artistas favoritos, pesquisadores descobriram que modelos que tinham mais aprendizado por reforço (modelos de raciocínio) tendiam a ter uma probabilidade maior de responder com artistas que tinham números ou outros símbolos matemáticos em seus nomes do que artistas regulares.
Você é o chatbot
Alguém no twitter criou o oposto de um assistente de IA, um usuário de IA. Ele foi treinado em uma estrutura invertida, onde espera que você responda suas perguntas, resultando em algumas trocas hilariantes.
Você pode conversar com o usuário de IA agora em https://youaretheassistantnow.com.
Finalização
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de emails abaixo.
Pipeline totalmente local de imagem para vídeo usando Qwen Image e Wan 2.2 - de fofr no twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Lanzamiento de DeepSeek 3.1
Después de un largo receso, DeepSeek finalmente ha lanzado un nuevo modelo. Es el modelo DeepSeek V3.1, que combina las capacidades de razonamiento y no razonamiento de sus modelos anteriores en un único modelo híbrido.
Este lanzamiento parece ser una respuesta a Kimi K2 y GLM 4.5, que son ambos modelos de razonamiento y agénticos muy potentes lanzados por otros laboratorios chinos. Con este lanzamiento, DeepSeek realmente enfatizó la capacidad de codificación agéntica del modelo, logrando grandes mejoras en la mayoría de los benchmarks de ingeniería de software y agénticos respecto a las versiones anteriores.
La porción de razonamiento del modelo es mucho más rápida que antes, ya que DeepSeek había sido conocido por tener cadenas de pensamiento muy largas que causaban tiempos de respuesta prolongados, incluso para consultas simples. Con este lanzamiento, redujeron bastante este comportamiento ya que el modelo ahora usa entre 30 y 50% menos tokens mientras piensa, manteniendo una precisión similar.
También han hecho muy fácil usar el modelo en Cloudcode, proporcionando instrucciones muy simples sobre cómo usarlo en Cloudcode. La única desventaja, sin embargo, es que el modelo funciona muy lentamente desde la API de DeepSeek con solo 20 tokens por segundo.
Sin embargo, el modelo domina en la relación precio-rendimiento ya que con su precio de $1 por millón de tokens de salida y la cantidad reducida de tokens de razonamiento hace que el modelo sea aún más eficiente que antes, siendo la mitad del precio de los otros modelos chinos.
Z.ai Lidera el Benchmark de Uso de Computadoras
ZAI lanzó un framework de RL para afinar agentes de uso de computadoras. Junto con esto, también lanzaron un ajuste fino de su modelo GLM 4.1 de 9 mil millones de parámetros que lidera el benchmark OS World.
OS World es un benchmark para agentes multimodales que prueba qué tan bien pueden interactuar con interfaces visuales así como con sistemas operativos. Algunas tareas incluidas que forman parte de él son instalar Spotify y también extraer un archivo adjunto de un correo electrónico y subirlo a Google Drive.
Su modelo, siendo mucho, mucho más pequeño que los competidores en la cima del benchmark, como Claude 4 Sonnet, aún logra superarlos, mostrando cuán lejos se puede llegar con un modelo pequeño si lo enfocas solo en un dominio algo limitado.
Lamentablemente el modelo no fue de código abierto, pero podría ser divertido ir e intentar afinar tu propia versión de esto y ver si puedes incluso superar su rendimiento.
Qwen Image Edit
Qwen ha lanzado un modelo de edición de imágenes basado en Qwen image, que lanzaron hace dos semanas. El modelo sobresale en todas las formas de edición de imágenes, incluyendo manipulación de texto, rotación de objetos, edición de apariencia, agregar y eliminar objetos, y más.
Ejemplo de caso de uso
Sus capacidades están respaldadas también en benchmarks del mundo real, estando básicamente en la cima de la tabla de clasificación de edición de imágenes de Artificial Analysis, la cual es votada por personas reales. También puedes revisar la página de Twitter de Qwen para ver un montón de otros ejemplos de cómo puede ser usado.
Esto combinado con el también bueno modelo base Qwen image conforma uno de los mejores stacks de generación y edición de imágenes disponibles. Cambiaré mi pipeline local de generación de imágenes para usar ambos en la próxima semana debido a esto.
Investigación
¿Puede la IA Predecir el Futuro?
Recientemente, mercados de apuestas como Kalshi y Polymarket han ganado una popularidad masiva, permitiendo a los usuarios apostar sobre lo que podría suceder en el mundo real, como ¿habrá un terremoto de magnitud 7 este mes?, o ¿cuántos tweets hará Elon Musk esta semana?
Los investigadores quisieron ver qué tan buenos son los LLMs para elegir sobre qué eventos del mundo real apostar y asignarles probabilidades para ver si tienen una ventaja sobre estos mercados.
La respuesta corta, no. El retorno promedio es desde la cantidad inicial, así que menos del 100% significa que perdieron dinero y más del 100% significa que han ganado dinero
Ningún LLM pudo vencer al mercado. Los modelos de OpenAI fueron los mejores en promedio y DeepSeek fue el peor, pero ninguno de ellos tuvo pérdidas catastróficas.
Es interesante ver las dinámicas de cómo diferentes LLMs deciden hacer apuestas y cómo quieren actuar. O3-Mini, por ejemplo, es súper agresivo y está dispuesto a tomar posiciones arriesgadas para obtener un gran pago, lo que resulta en que esté en la cima de la tabla de clasificación.
El resultado de DeepSeek es definitivamente el más interesante de todos estos modelos. La mayoría de los modelos tienden a estar al menos algo cerca unos de otros en términos de probabilidad esperada para la mayoría de estas apuestas. Pero DeepSeek no. DeepSeek tiene probabilidades enormemente diferentes que está asignando a que estos eventos sucedan o no sucedan, que es completamente contrario al resto de los modelos. Esta singularidad no le ayuda en absoluto, ya que tuvo los peores retornos de cualquier modelo.
Lo genial sobre este benchmark es que no puede ser sobreajustado. Siempre está en vivo, y siempre hay nuevos eventos sobre los cuales ir y apostar. Así que asegúrate de revisar la tabla de clasificación de vez en cuando para ver cómo están los modelos y ver si alguno de ellos ha sido capaz de superar en astucia a la mente colectiva humana.
Ronda Rápida
Herramientas útiles o temas que encontré esta semana que pueden o no estar relacionados con IA, pero sobre los que no tuve tiempo de escribir una sección completa.
A los modelos con RL realmente les gustan los números
Al preguntarle a un LLM cuáles son sus artistas favoritos, los investigadores encontraron que los modelos que habían tenido más aprendizaje por refuerzo (modelos de razonamiento) tendían a tener una mayor probabilidad de responder con artistas que tenían números u otros símbolos matemáticos en sus nombres que artistas regulares.
Tú eres el chatbot
Alguien en twitter hizo lo opuesto de un asistente de IA, un usuario de IA. Ha sido entrenado en una estructura invertida, donde espera que tú respondas sus preguntas, resultando en algunos intercambios hilarantes.
Puedes hablar con el usuario de IA ahora en https://youaretheassistantnow.com.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Pipeline completamente local de imagen a video usando Qwen Image y Wan 2.2 - de fofr en twitter