Releases
Nano Banana
The previously stealth Nano Banana model has finally been claimed by an organization, with Google DeepMind announcing the release of their Gemini Flash 2.5 Image model, which they revealed had been Nano Banana this entire time.
Nano banana has been making waves as its been deployed in various image editing arenas, completely outshining its competitors, and driving record numbers of people to go and try it on these sites like LMArena and Artificial Analysis.
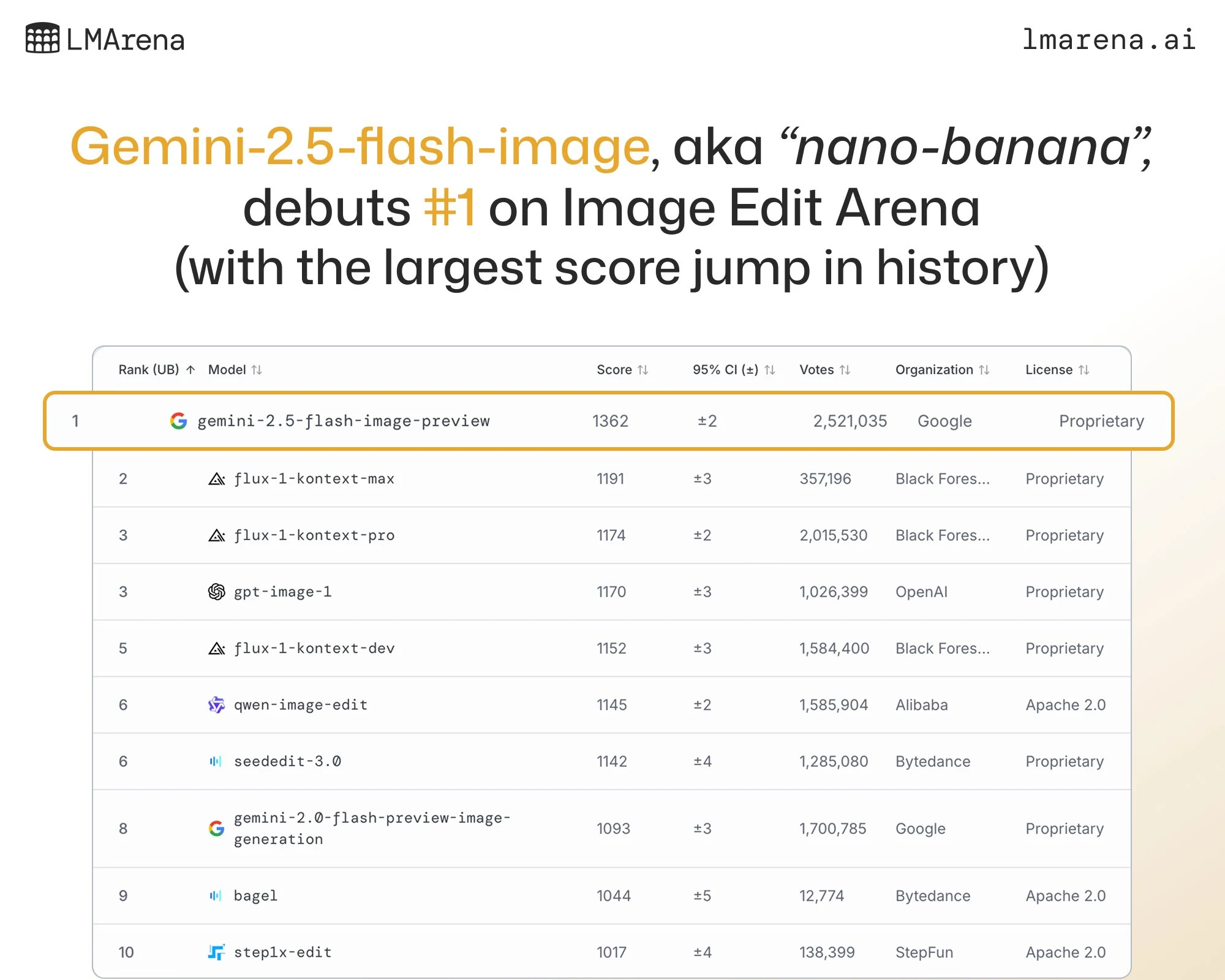
The model is available now to use for free on Google’s AIStudio and also via the API for $0.039 per image.
Qwen Audio to Video
It wouldn’t be a week of AI News without a Qwen release.
This week Qwen dropped a fine tune to their WAN 2.2 video generation model, adding the ability for you to pass in audio along with a reference image, and then the model would generate a video of your character speaking that audio.
The model is good at getting the high level body movement, but it still struggles to get the actual lip syncing down.
However I expect the open source community to have a much better finetune of this model in a few months, so I’ll be on the lookout for when and what that model is.
Marvis-TTS
A new challenger has arrived in the efficient TTS space, and its called Marvin TTS.
It is a 300 million parameter model with audio streaming capabilities, making it great for low resource, yet fast response time applications.
Its audio quality is definitely a step up from the current champion Kokoro TTS, but it is 5x larger, although it will have equivalent response times due to the streaming functionality that it has.
These extra parameters do get you some very welcome features, like voice cloning from just a 10 second audio clip.
The quality is definitely not the very best when compared to models 5-10x its size, but it still punches far above its weight.
You can try the model now on Mac using the mlx-audio library, or on gpu (and cpu) based systems using transformers.
Research
Environments Hub
Prime Intellect, an upstart AI lab here in the US, has released the Github for reinforcement learning environments for LLMs.
If you haven’t heard, the current big approach for RL for LLM’s has been reinforcement learning with verifiable rewards (RLVF).
In RLVF, we are able to explicitly define in code what the rewards for the model should be instead of using a separate reward model.
One common example is math, where we know for a given question what the answer is supposed to be, so we can just check the model’s output (also rewarding it for formatting correctly) to see if it got it correct or not, and rewarding it accordingly.
This makes RL training much simpler and easier to scale, notable being what XAi used to train Grok 4.
One issue the community had however was that there was no common place to see what environments other people had made or shared their own.
That is where Prime Intellect comes in, as they have made a hub where you can share and see what everyone else has made.
This is great for other researchers and model trainers, since they now have access to a large number of environments without needing to make it themselves from scratch.
Finish
I hope you enjoyed the news this week.
I have been in the process of moving this week, so I haven’t been able to work on the news very much at all, so if it seemed a bit sparse that’s why.
If you want to get the news every week, be sure to join our mailing list below.
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Nano Banana
O modelo Nano Banana, que estava em modo stealth, finalmente foi reivindicado por uma organização, com o Google DeepMind anunciando o lançamento de seu modelo Gemini Flash 2.5 Image, revelando que este era o Nano Banana o tempo todo.
O Nano banana tem causado furor ao ser implantado em várias arenas de edição de imagens, ofuscando completamente seus concorrentes e levando um número recorde de pessoas a experimentá-lo em sites como LMArena e Artificial Analysis.
O modelo está disponível agora para uso gratuito no AIStudio do Google e também via API por $0,039 por imagem.
Qwen Audio para Vídeo
Não seria uma semana de notícias de IA sem um lançamento da Qwen.
Esta semana a Qwen lançou um ajuste fino para seu modelo de geração de vídeo WAN 2.2, adicionando a capacidade de você passar áudio junto com uma imagem de referência, e então o modelo geraria um vídeo do seu personagem falando esse áudio.
O modelo é bom em capturar o movimento corporal de alto nível, mas ainda tem dificuldades para acertar a sincronização labial real.
No entanto, espero que a comunidade de código aberto tenha um ajuste fino muito melhor deste modelo em alguns meses, então estarei de olho para quando e qual será esse modelo.
Marvis-TTS
Um novo desafiante chegou no espaço de TTS eficiente, e se chama Marvin TTS.
É um modelo de 300 milhões de parâmetros com capacidades de streaming de áudio, tornando-o ótimo para aplicações de baixo recurso, mas com tempo de resposta rápido.
Sua qualidade de áudio é definitivamente um passo à frente do atual campeão Kokoro TTS, mas é 5x maior, embora tenha tempos de resposta equivalentes devido à funcionalidade de streaming que possui.
Esses parâmetros extras trazem alguns recursos muito bem-vindos, como clonagem de voz a partir de apenas um clipe de áudio de 10 segundos.
A qualidade definitivamente não é a melhor quando comparada a modelos 5-10x maiores, mas ainda assim tem um desempenho muito acima do seu peso.
Você pode experimentar o modelo agora no Mac usando a biblioteca mlx-audio, ou em sistemas baseados em GPU (e CPU) usando transformers.
Pesquisa
Environments Hub
A Prime Intellect, um laboratório de IA emergente aqui nos EUA, lançou o Github para ambientes de aprendizado por reforço para LLMs.
Se você não ouviu falar, a grande abordagem atual para RL para LLMs tem sido o aprendizado por reforço com recompensas verificáveis (RLVF).
No RLVF, somos capazes de definir explicitamente em código quais devem ser as recompensas para o modelo, em vez de usar um modelo de recompensa separado.
Um exemplo comum é matemática, onde sabemos para uma determinada questão qual deve ser a resposta, então podemos simplesmente verificar a saída do modelo (também recompensando-o por formatar corretamente) para ver se ele acertou ou não, e recompensá-lo adequadamente.
Isso torna o treinamento de RL muito mais simples e fácil de escalar, sendo notavelmente o que a XAi usou para treinar o Grok 4.
Um problema que a comunidade tinha, no entanto, era que não havia um lugar comum para ver quais ambientes outras pessoas fizeram ou compartilhar os seus próprios.
É aí que entra a Prime Intellect, pois eles criaram um hub onde você pode compartilhar e ver o que todos os outros fizeram.
Isso é ótimo para outros pesquisadores e treinadores de modelos, já que agora eles têm acesso a um grande número de ambientes sem precisar fazê-los do zero.
Conclusão
Espero que você tenha gostado das notícias desta semana.
Estive no processo de mudança esta semana, então não consegui trabalhar muito nas notícias, então se pareceu um pouco escasso, é por isso.
Se você quiser receber as notícias toda semana, não deixe de se juntar à nossa lista de e-mails abaixo.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Nano Banana
El modelo Nano Banana, que anteriormente estaba en modo sigiloso, finalmente ha sido reclamado por una organización, con Google DeepMind anunciando el lanzamiento de su modelo Gemini Flash 2.5 Image, que revelaron había sido Nano Banana todo este tiempo.
Nano banana ha estado causando sensación ya que se ha implementado en varios espacios de edición de imágenes, superando completamente a sus competidores e impulsando cifras récord de personas a probarlo en estos sitios como LMArena y Artificial Analysis.
El modelo está disponible ahora para usar gratis en AIStudio de Google y también a través de la API por $0.039 por imagen.
Qwen Audio to Video
No sería una semana de noticias de IA sin un lanzamiento de Qwen.
Esta semana Qwen lanzó un ajuste fino a su modelo de generación de video WAN 2.2, agregando la capacidad de pasar audio junto con una imagen de referencia, y luego el modelo generaría un video de tu personaje hablando ese audio.
El modelo es bueno obteniendo el movimiento corporal de alto nivel, pero aún tiene dificultades para lograr la sincronización labial real.
Sin embargo, espero que la comunidad de código abierto tenga un ajuste fino mucho mejor de este modelo en unos meses, así que estaré atento a cuándo y cuál será ese modelo.
Marvis-TTS
Un nuevo contendiente ha llegado al espacio de TTS eficiente, y se llama Marvin TTS.
Es un modelo de 300 millones de parámetros con capacidades de transmisión de audio, lo que lo hace excelente para aplicaciones de bajos recursos pero con tiempos de respuesta rápidos.
Su calidad de audio es definitivamente un paso adelante del actual campeón Kokoro TTS, pero es 5 veces más grande, aunque tendrá tiempos de respuesta equivalentes debido a la funcionalidad de transmisión que tiene.
Estos parámetros adicionales te brindan algunas características muy bienvenidas, como la clonación de voz a partir de solo un clip de audio de 10 segundos.
La calidad definitivamente no es la mejor cuando se compara con modelos de 5-10 veces su tamaño, pero aún así rinde muy por encima de su peso.
Puedes probar el modelo ahora en Mac usando la biblioteca mlx-audio, o en sistemas basados en gpu (y cpu) usando transformers.
Investigación
Environments Hub
Prime Intellect, un laboratorio de IA emergente aquí en Estados Unidos, ha lanzado el Github para entornos de aprendizaje por refuerzo para LLMs.
Si no has escuchado, el gran enfoque actual para RL para LLMs ha sido el aprendizaje por refuerzo con recompensas verificables (RLVF).
En RLVF, podemos definir explícitamente en código cuáles deberían ser las recompensas para el modelo en lugar de usar un modelo de recompensa separado.
Un ejemplo común son las matemáticas, donde sabemos para una pregunta dada cuál se supone que es la respuesta, así que simplemente podemos verificar la salida del modelo (también recompensándolo por formatear correctamente) para ver si lo hizo correctamente o no, y recompensarlo en consecuencia.
Esto hace que el entrenamiento de RL sea mucho más simple y más fácil de escalar, siendo notablemente lo que XAi usó para entrenar Grok 4.
Sin embargo, un problema que tenía la comunidad era que no había un lugar común para ver qué entornos habían hecho otras personas o compartir los suyos propios.
Ahí es donde entra Prime Intellect, ya que han hecho un hub donde puedes compartir y ver lo que todos los demás han hecho.
Esto es excelente para otros investigadores y entrenadores de modelos, ya que ahora tienen acceso a un gran número de entornos sin necesidad de hacerlo ellos mismos desde cero.
Fin
Espero que hayas disfrutado las noticias de esta semana.
He estado en proceso de mudarme esta semana, así que no he podido trabajar mucho en las noticias, así que si parecía un poco escasa, esa es la razón.
Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.