News
Be careful who you get your inference from
It has been reported recently that different inference providers of gpt-oss provide endpoints with differing levels of quality.
In a report released by Artificial Analysis this week, these reports have been formally verified, as they find that there is a >10% gap in benchmark scores depending on what provider you are using.
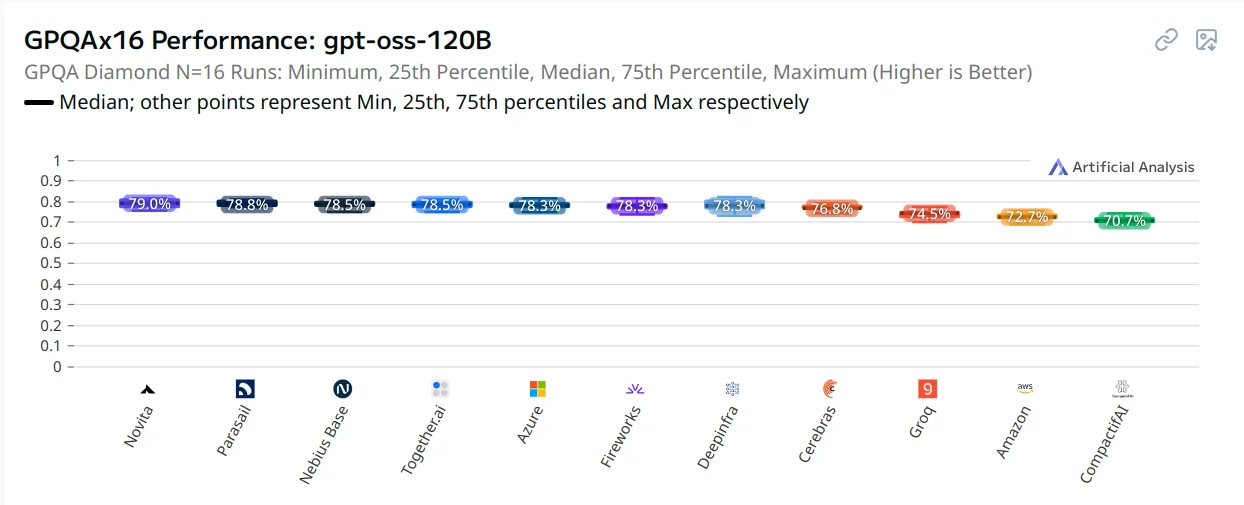
The 10% difference in GPQA scores is equivalent to going from Qwen3 235B to Qwen3 30B
This report has caused some action, as previously Azure had been one of the worst available endpoints, but because of the report, they have updated their endpoint to serve the correct version.
They say the issue was that the version of vLLM they were using did not respect the reasoning effort parameter, causing the model to be on medium reasoning effort instead of high.
This also highlights how important reasoning is for the new OpenAI models (gpt-oss and GPT5).
Many users have been reporting that the difference between GPT5 and GPT5-high is night and day, with regular GPT5 being borderline unusable (for coding tasks) while GPT5-high works fairly well.
Claude 3.5 and 3.6 Deprecation
Anthropic recently announced that two of their most influential models, Claude Sonnet 3.5 and 3.6, are going to be deprecated in 2 months (October 22, 2025).
These models are formative for Anthropic, as they started the death grip Anthropic has had on agentic coding models over the last year.
Sonnet 3.5 specifically is potentially the last “pure” LLM we will see for a while, that was tastefully trained and not benchmaxxed with an egregious amount of reinforcement learning.
This sudden deprivation has caught a lot of people off guard and has caused an outcry from many in the technical community, as these models have much more “soul” and “feeling” than the likes of GPT-4o, which also caused a lot of controversy when OpenAI announced they were getting rid of it last week, causing OpenAI to reinstate the model for the time being.
We will see if Anthropic sets up any “research” endpoints that users can access these models from still, similar to what the did for Opus 3. If not, I will miss the models, they were the first “good enough” agentic coders that could be used every day. Expect a funeral for these models similar to that of Sonnet 3.
Releases
GLM 4.5 Vision
The Z.ai team has released a new, multimodal variant of their text-exclusive LLM GLM 4.5.
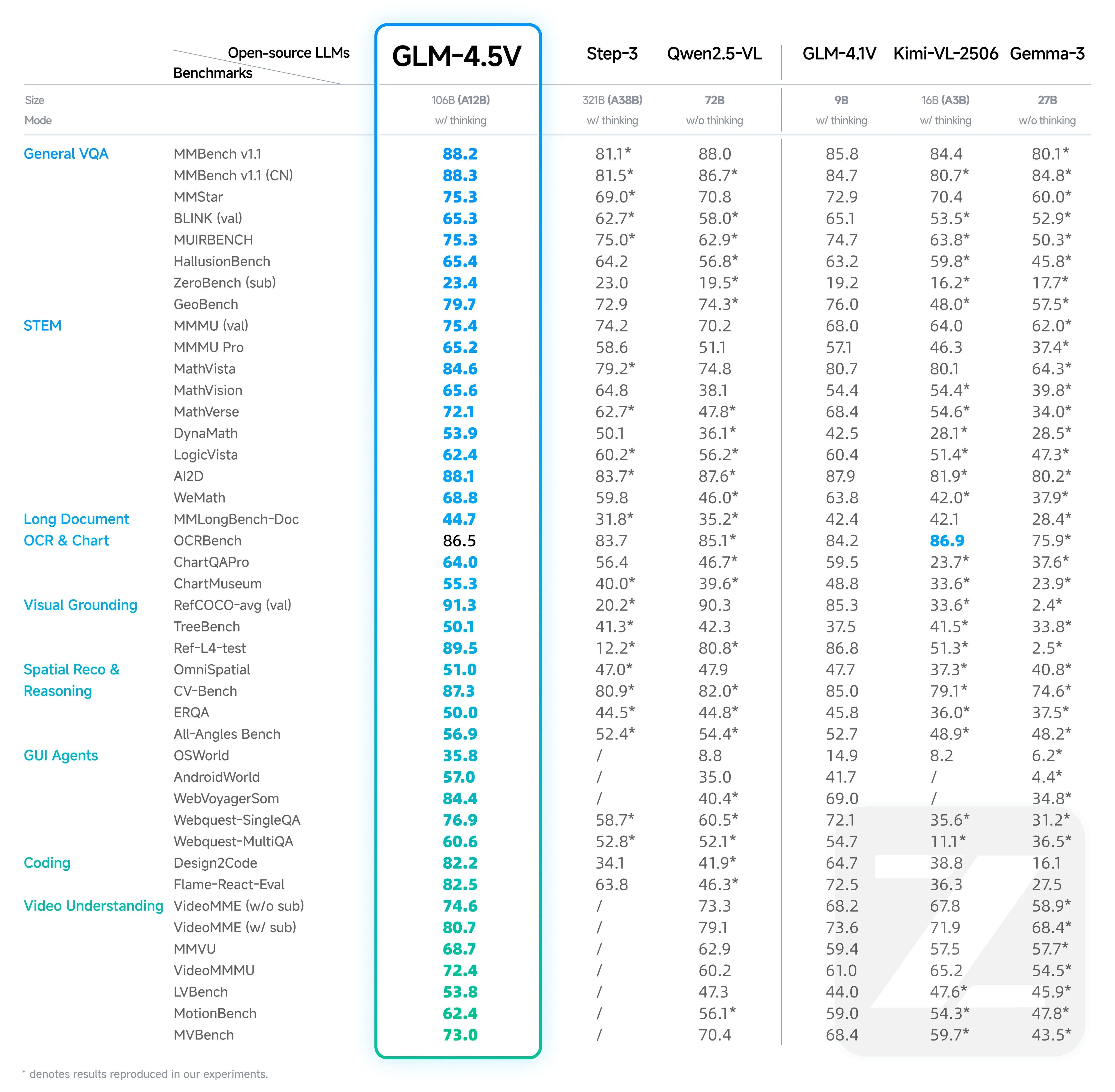
The new model, like the model it is built from, it is state of the art across all open source vision models.
It is based on the smaller GLM 4.5 Air model, allowing it to feasibly be run at home.
 Da Benchies
Da Benchies
Despite the good benchmarks, it is a bit unpolished, as there have been numerous issues, including overthinking and output formatting.
Z.ai has remedied some of them since the release, but other issues still persist.
I would not recommend using the model at this point because of the above issues, and would instead use the GLM 4.1 model, which performs closely to the 4.5 model while being 9B params instead of 120B.
VLM’s in general are still rather lack luster in comparison to their text only brethren, as there are many, many instances of them exhibiting overfitting, bias, or behaviour that makes you think they cannot see anything at all, as highlighted by this research paper that came out this week.
Also along side this they also released research reports for the vision models (GLM 4.1 and 4.5) and also for the text based models.
If you are a RL researcher, I would also go and check out their RL training framework SLIME, word on the street is that it is very nice to use.
DINO V3
Changing it up from the usual LLM and image generation models, Meta FAIR has released the latest in their DINO series of computer vision models.
These models are used for extracting features from images, so if you wanted to make an image dedupe model, a rare bird classifier, or make a custom segmentation model, DINO is the model to use. It excels in low data regimes, given its strong base understanding of images.

How different CV models “see” the world
The model, unlike previous, has been scaled to billions of parameters, something which has previously been difficult for CV researchers to do. It also does very well on high resolution images, and has set new SOTA on pretty much every CV benchmark it can be applied to.
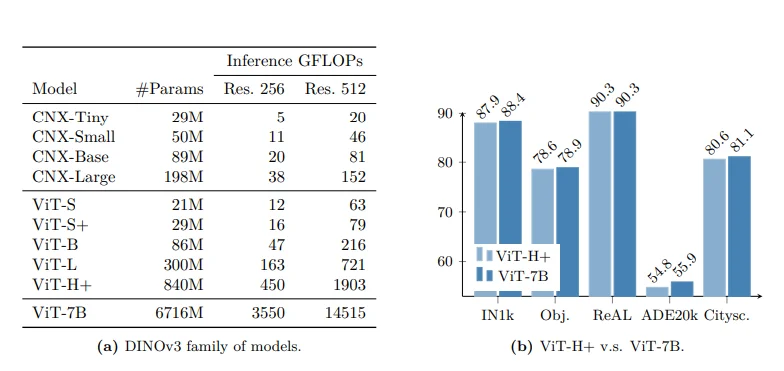
The DINO v3 model family and comparison between the 7B and 800M param models
The model comes in a wide variety of sizes, ranging from 29 million parameters all the way up to 7 billion. The 7B param model is the “base” model that all the others are distilled from.
The distilled models are what you will probably want to use in the real world, as they have comparable performance while being 10x smaller (or more)!
There are two different flavors of small models, ViT and ConvNext.
The ViT models will be higher quality and should be used for most production workloads, while the ConvNext models are super lightweight so they can be used for on device deployments.
Research
When learning about a new field or topic, you probably often spend a large amount of time going through a phase of repetitive research to try and find what is currently relevant for the field, something that you would hope could be automated by AI.
A group of researchers from the ByteDance research lab also thought this, so they put togther a benchmark to measure how good different LLMs were at this task.
Some examples from the benchmark:
Could you list every single concert on Taylor Swift’s official tour from January 1, 2010, to May 1, 2025, including the specific date, the concert’s English name, the country, the city, and the venue. Each show should be on its own line, in chronological order from earliest to latest.
Could you provide a detailed list of Michelin three-star restaurants in Paris, France as of December 31, 2024? I especially want to know the name, main cuisine style and exact address of each restaurant.
Note: Formatting rules omitted for brevity

Uh oh thats not good
What they found is that all models suck at this, with no model scoring over 6%. They tested single agent, multi agent, and also end to end browser use systems.
The agents struggled not due to search errors, but fundamental cognitive errors.
They failed at the planning stage to break down questions into simple enough sub queries.
If they failed to find an answer after a single query, they would give up instead of trying others.
When they did find the correct source, they would misinterpret or ignore its content, or hallucinate content that was not there.
That being said, this dataset is hard even for humans, as normal human experts only score around 20% on these tasks, although this is still almost 3x better than the AI.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

A satelite image seen through the eyes of DINO V3 Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Foi relatado recentemente que diferentes provedores de inferência do gpt-oss fornecem endpoints com níveis de qualidade diferentes.
Em um relatório divulgado pela Artificial Analysis esta semana, esses relatos foram formalmente verificados, pois descobriram que há uma diferença de >10% nas pontuações de benchmark dependendo do provedor que você está usando.
A diferença de 10% nas pontuações GPQA é equivalente a passar do Qwen3 235B para o Qwen3 30B
Este relatório causou alguma ação, pois anteriormente o Azure tinha sido um dos piores endpoints disponíveis, mas por causa do relatório, eles atualizaram seu endpoint para servir a versão correta.
Eles dizem que o problema era que a versão do vLLM que estavam usando não respeitava o parâmetro de esforço de raciocínio, fazendo com que o modelo ficasse em esforço de raciocínio médio em vez de alto.
Isso também destaca quão importante é o raciocínio para os novos modelos OpenAI (gpt-oss e GPT5).
Muitos usuários têm relatado que a diferença entre GPT5 e GPT5-high é como dia e noite, com o GPT5 regular sendo quase inutilizável (para tarefas de codificação) enquanto o GPT5-high funciona razoavelmente bem.
Descontinuação do Claude 3.5 e 3.6
A Anthropic anunciou recentemente que dois de seus modelos mais influentes, Claude Sonnet 3.5 e 3.6, serão descontinuados em 2 meses (22 de outubro de 2025).
Esses modelos são fundamentais para a Anthropic, pois iniciaram o domínio absoluto que a Anthropic teve sobre modelos de codificação agêntica no último ano.
O Sonnet 3.5 especificamente é potencialmente a última LLM “pura” que veremos por um tempo, que foi treinada com bom gosto e não foi otimizada excessivamente para benchmarks com uma quantidade exagerada de aprendizado por reforço.
Esta descontinuação repentina pegou muitas pessoas desprevenidas e causou protestos de muitos na comunidade técnica, pois esses modelos têm muito mais “alma” e “sentimento” do que modelos como o GPT-4o, que também causou muita controvérsia quando a OpenAI anunciou que iria se livrar dele na semana passada, fazendo com que a OpenAI reinstaurasse o modelo por enquanto.
Veremos se a Anthropic configura algum endpoint de “pesquisa” do qual os usuários ainda podem acessar esses modelos, similar ao que fizeram com o Opus 3. Se não, vou sentir falta dos modelos, eles foram os primeiros codificadores agênticos “bons o suficiente” que podiam ser usados todos os dias. Espere um funeral para esses modelos similar ao do Sonnet 3.
Lançamentos
GLM 4.5 Vision
A equipe Z.ai lançou uma nova variante multimodal de sua LLM exclusiva para texto GLM 4.5.
O novo modelo, como o modelo do qual é construído, é estado da arte entre todos os modelos de visão de código aberto.
É baseado no modelo menor GLM 4.5 Air, permitindo que seja executado de forma viável em casa.
Os Benchmarks
Apesar dos bons benchmarks, está um pouco inacabado, pois houve vários problemas, incluindo excesso de raciocínio e formatação de saída.
A Z.ai corrigiu alguns deles desde o lançamento, mas outros problemas ainda persistem.
Eu não recomendaria usar o modelo neste momento por causa dos problemas acima, e em vez disso usaria o modelo GLM 4.1, que tem desempenho próximo ao modelo 4.5 enquanto tem 9B de parâmetros em vez de 120B.
VLMs em geral ainda são bastante medíocres em comparação com seus irmãos exclusivos para texto, pois há muitos, muitos casos deles exibindo overfitting, viés, ou comportamento que faz você pensar que eles não conseguem ver nada, como destacado por este artigo de pesquisa que saiu esta semana.
Além disso, eles também lançaram relatórios de pesquisa para os modelos de visão (GLM 4.1 e 4.5) e também para os modelos baseados em texto.
Se você é um pesquisador de RL, também recomendo verificar seu framework de treinamento RL SLIME, dizem por aí que é muito bom de usar.
DINO V3
Mudando um pouco dos modelos usuais de LLM e geração de imagens, o Meta FAIR lançou a versão mais recente de sua série DINO de modelos de visão computacional.
Esses modelos são usados para extrair características de imagens, então se você quiser fazer um modelo de deduplicação de imagens, um classificador de pássaros raros, ou fazer um modelo de segmentação personalizado, DINO é o modelo a ser usado. Ele se destaca em regimes de poucos dados, dado seu forte entendimento base de imagens.
Como diferentes modelos de CV “veem” o mundo
O modelo, diferentemente dos anteriores, foi escalado para bilhões de parâmetros, algo que anteriormente era difícil para pesquisadores de CV fazerem. Ele também funciona muito bem em imagens de alta resolução, e estabeleceu novo SOTA em praticamente todos os benchmarks de CV aos quais pode ser aplicado.
A família de modelos DINO v3 e comparação entre os modelos de 7B e 800M de parâmetros
O modelo vem em uma ampla variedade de tamanhos, variando de 29 milhões de parâmetros até 7 bilhões. O modelo de 7B de parâmetros é o modelo “base” do qual todos os outros são destilados.
Os modelos destilados são os que você provavelmente vai querer usar no mundo real, pois têm desempenho comparável enquanto são 10x menores (ou mais)!
Existem dois sabores diferentes de modelos pequenos, ViT e ConvNext.
Os modelos ViT terão maior qualidade e devem ser usados para a maioria das cargas de trabalho de produção, enquanto os modelos ConvNext são super leves, então podem ser usados para implantações em dispositivos.
Pesquisa
Ao aprender sobre um novo campo ou tópico, você provavelmente frequentemente passa muito tempo passando por uma fase de pesquisa repetitiva para tentar encontrar o que é atualmente relevante para o campo, algo que você esperaria que pudesse ser automatizado por IA.
Um grupo de pesquisadores do laboratório de pesquisa ByteDance também pensou nisso, então eles montaram um benchmark para medir quão boas diferentes LLMs eram nesta tarefa.
Alguns exemplos do benchmark:
Você poderia listar todos os shows na turnê oficial de Taylor Swift de 1º de janeiro de 2010 a 1º de maio de 2025, incluindo a data específica, o nome do show em inglês, o país, a cidade e o local. Cada show deve estar em sua própria linha, em ordem cronológica do mais antigo ao mais recente.
Você poderia fornecer uma lista detalhada de restaurantes três estrelas Michelin em Paris, França, em 31 de dezembro de 2024? Eu especialmente quero saber o nome, o estilo de culinária principal e o endereço exato de cada restaurante.
Nota: Regras de formatação omitidas por brevidade
Opa, isso não é bom
O que eles descobriram é que todos os modelos são ruins nisso, sem nenhum modelo pontuando acima de 6%. Eles testaram agente único, múltiplos agentes, e também sistemas de uso de navegador de ponta a ponta.
Os agentes tiveram dificuldades não devido a erros de busca, mas a erros cognitivos fundamentais.
Eles falharam na fase de planejamento ao decompor questões em subconsultas simples o suficiente.
Se eles falhassem em encontrar uma resposta após uma única consulta, desistiam em vez de tentar outras.
Quando encontravam a fonte correta, interpretavam mal ou ignoravam seu conteúdo, ou alucinavam conteúdo que não estava lá.
Dito isso, este conjunto de dados é difícil até para humanos, pois especialistas humanos normais pontuam apenas cerca de 20% nessas tarefas, embora isso ainda seja quase 3x melhor que a IA.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, não deixe de se juntar à nossa lista de e-mails abaixo.
Uma imagem de satélite vista através dos olhos do DINO V3 Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
Ten cuidado de quién obtienes tu inferencia
Se ha informado recientemente que diferentes proveedores de inferencia de gpt-oss proporcionan endpoints con diferentes niveles de calidad.
En un informe publicado por Artificial Analysis esta semana, estos reportes han sido formalmente verificados, ya que encuentran que hay una brecha de >10% en las puntuaciones de benchmarks dependiendo del proveedor que estés utilizando.
La diferencia del 10% en las puntuaciones GPQA es equivalente a pasar de Qwen3 235B a Qwen3 30B
Este informe ha causado algunas acciones, ya que anteriormente Azure había sido uno de los peores endpoints disponibles, pero debido al informe, han actualizado su endpoint para servir la versión correcta.
Dicen que el problema era que la versión de vLLM que estaban utilizando no respetaba el parámetro de esfuerzo de razonamiento, causando que el modelo estuviera en esfuerzo de razonamiento medio en lugar de alto.
Esto también resalta cuán importante es el razonamiento para los nuevos modelos de OpenAI (gpt-oss y GPT5).
Muchos usuarios han estado reportando que la diferencia entre GPT5 y GPT5-high es como la noche y el día, con el GPT5 regular siendo prácticamente inutilizable (para tareas de programación) mientras que GPT5-high funciona bastante bien.
Deprecación de Claude 3.5 y 3.6
Anthropic anunció recientemente que dos de sus modelos más influyentes, Claude Sonnet 3.5 y 3.6, van a ser deprecados en 2 meses (22 de octubre de 2025).
Estos modelos son fundamentales para Anthropic, ya que iniciaron el dominio absoluto que Anthropic ha tenido sobre los modelos de codificación agéntica durante el último año.
Sonnet 3.5 específicamente es potencialmente el último LLM “puro” que veremos por un tiempo, que fue entrenado con buen gusto y no optimizado excesivamente para benchmarks con una cantidad atroz de aprendizaje por refuerzo.
Esta repentina privación ha tomado a mucha gente desprevenida y ha causado un clamor de muchos en la comunidad técnica, ya que estos modelos tienen mucho más “alma” y “sentimiento” que modelos como GPT-4o, que también causó mucha controversia cuando OpenAI anunció que se desharían de él la semana pasada, causando que OpenAI reinstalara el modelo por el momento.
Veremos si Anthropic configura algunos endpoints de “investigación” desde los cuales los usuarios puedan acceder a estos modelos todavía, similar a lo que hicieron para Opus 3. Si no, extrañaré los modelos, fueron los primeros codificadores agénticos “suficientemente buenos” que podían usarse todos los días. Espera un funeral para estos modelos similar al de Sonnet 3.
Lanzamientos
GLM 4.5 Vision
El equipo de Z.ai ha lanzado una nueva variante multimodal de su LLM exclusivo de texto GLM 4.5.
El nuevo modelo, al igual que el modelo del que se construye, es estado del arte en todos los modelos de visión de código abierto.
Está basado en el modelo más pequeño GLM 4.5 Air, permitiendo que sea factible ejecutarlo en casa.
Los Benchmarks
A pesar de los buenos benchmarks, está un poco sin pulir, ya que ha habido numerosos problemas, incluyendo sobrepensamiento y formato de salida.
Z.ai ha remediado algunos de ellos desde el lanzamiento, pero otros problemas aún persisten.
No recomendaría usar el modelo en este momento debido a los problemas anteriores, y en su lugar usaría el modelo GLM 4.1, que tiene un rendimiento cercano al modelo 4.5 mientras que tiene 9B parámetros en lugar de 120B.
Los VLM en general todavía son bastante deficientes en comparación con sus hermanos de solo texto, ya que hay muchas, muchas instancias de ellos exhibiendo sobreajuste, sesgo, o comportamiento que te hace pensar que no pueden ver nada en absoluto, como lo destaca este artículo de investigación que salió esta semana.
También junto con esto, lanzaron informes de investigación para los modelos de visión (GLM 4.1 y 4.5) y también para los modelos basados en texto.
Si eres un investigador de RL, también deberías ir a ver su framework de entrenamiento RL SLIME, se dice que es muy agradable de usar.
DINO V3
Cambiando un poco de los habituales modelos LLM y de generación de imágenes, Meta FAIR ha lanzado la última versión de su serie DINO de modelos de visión por computadora.
Estos modelos se usan para extraer características de imágenes, así que si quisieras hacer un modelo de deduplicación de imágenes, un clasificador de aves raras, o hacer un modelo de segmentación personalizado, DINO es el modelo a usar. Destaca en regímenes de pocos datos, dada su sólida comprensión base de imágenes.
Cómo diferentes modelos CV “ven” el mundo
El modelo, a diferencia de los anteriores, ha sido escalado a miles de millones de parámetros, algo que previamente había sido difícil para los investigadores de CV hacer. También funciona muy bien en imágenes de alta resolución, y ha establecido un nuevo SOTA en prácticamente todos los benchmarks de CV a los que puede aplicarse.
La familia de modelos DINO v3 y comparación entre los modelos de 7B y 800M parámetros
El modelo viene en una amplia variedad de tamaños, que van desde 29 millones de parámetros hasta 7 mil millones. El modelo de 7B parámetros es el modelo “base” del cual todos los demás son destilados.
Los modelos destilados son los que probablemente querrás usar en el mundo real, ya que tienen un rendimiento comparable mientras son 10x más pequeños (¡o más)!
Hay dos sabores diferentes de modelos pequeños, ViT y ConvNext.
Los modelos ViT serán de mayor calidad y deberían usarse para la mayoría de las cargas de trabajo de producción, mientras que los modelos ConvNext son súper ligeros para que puedan usarse en despliegues en dispositivo.
Investigación
Cuando aprendes sobre un nuevo campo o tema, probablemente a menudo pasas una gran cantidad de tiempo atravesando una fase de investigación repetitiva para tratar de encontrar lo que es actualmente relevante para el campo, algo que esperarías pudiera ser automatizado por IA.
Un grupo de investigadores del laboratorio de investigación de ByteDance también pensó esto, así que armaron un benchmark para medir qué tan buenos eran diferentes LLMs en esta tarea.
Algunos ejemplos del benchmark:
¿Podrías listar todos y cada uno de los conciertos en la gira oficial de Taylor Swift desde el 1 de enero de 2010 hasta el 1 de mayo de 2025, incluyendo la fecha específica, el nombre del concierto en inglés, el país, la ciudad y el lugar. Cada show debe estar en su propia línea, en orden cronológico de más antiguo a más reciente.
¿Podrías proporcionar una lista detallada de restaurantes de tres estrellas Michelin en París, Francia al 31 de diciembre de 2024? Quiero saber especialmente el nombre, el estilo de cocina principal y la dirección exacta de cada restaurante.
Nota: Reglas de formato omitidas por brevedad
Uh oh eso no es bueno
Lo que encontraron es que todos los modelos son malos en esto, sin que ningún modelo obtenga más del 6%. Probaron sistemas de agente único, multi-agente, y también sistemas de uso de navegador de extremo a extremo.
Los agentes tuvieron dificultades no debido a errores de búsqueda, sino a errores cognitivos fundamentales.
Fallaron en la etapa de planificación al descomponer preguntas en subconsultas lo suficientemente simples.
Si no lograban encontrar una respuesta después de una sola consulta, se rendían en lugar de probar otras.
Cuando encontraban la fuente correcta, malinterpretaban o ignoraban su contenido, o alucinaban contenido que no estaba allí.
Dicho esto, este conjunto de datos es difícil incluso para humanos, ya que los expertos humanos normales solo obtienen alrededor del 20% en estas tareas, aunque esto sigue siendo casi 3 veces mejor que la IA.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Una imagen satelital vista a través de los ojos de DINO V3