News
Anthropic partners with SpaceX
As many of you have probably been aware, Anthropic has been struggling to get enough compute to serve their models.
This has caused rate limits to decrease, and also for more credits to be used during peak hours (they are billed at 2x more than normal).
All of a sudden, Anthropic has found an unlikely partner to help them out: Elon Musk.
xAI is renting out their 220k GPU datacenter Colossus 1 to Anthropic, allowing them to double their rate limit and remove the peak hours usage reduction for the Claude Code subscription plans, and also increase API rate limits drastically as well.
Anthropic has been heavily GPU constrained, as they only had planned for 10x growth this year, but are already on pace for 80x.
Getting access to a 5+ billion dollar datacenter helps them catch back up to meet this demand.
It is also interesting for xAI, as they are giving up a large chunk of their compute, to a company that historically Elon Musk has not been a fan of.
Many people have been calling this a Kingmaker scenario, as Elon’s dislike of Anthropic is less than his hatred of Sam Altman and OpenAI, who he has an open lawsuit against.
For me this changes little, as I have canceled my Anthropic subscription in favor of an OpenAI one instead, since GPT 5.5 is a far better model for coding than Opus (outside of the minimal amount of frontend work that I do).
Releases
SubQ
Many people have been talking about the new startup Subquadratic and their model SubQ.
The model claims a lot in terms of architectural advancements: 12 million context window, 52x faster than FlashAttention, and 5% the cost of Opus.

To say I am extremely skeptical of this model would be an understatement.
To understand why, let’s look at the benchmarks they released.
SWE Bench Verified has been denounced by its maker OpenAI, as many of the tests are incorrect, and also that it is probably one of the most overfit datasets out there, with any progress that we see from models coming from the fact that they have been trained on the answers, as that is the only way for models to pass the incorrect tests.
For the RULER benchmark, it was good, but has become saturated and outdated, and is also a public benchmark allowing for easy overfitting.
MRCR v2 is another public benchmark, and has recently been called out by Anthropic for not being correlated with long context capabilities, and are focusing on other benchmarks like GraphWalks instead as they are a better indicator of performance.
This is why you see a large drop in scores for Opus 4.6 and Opus 4.7 for the scores.
So the benchmarks they released are meaningless, what about the 12 million context length claim?
This is also bogus.
I have talked before about long context windows, and the main issue is that we just don’t have any meaningful long context data to train the models on.
From a hardware perspective, architectures like DeepSeek V4 could easily handle 10+ million context windows already, the issue is that you would see massive performance degradation since the model hasn’t actually seen any 1 million+ data before.
It hasn’t been until the last 3-6 months where frontier labs like Anthropic and OpenAI have been able to get consistent results up to 256k, let alone the 1 million token max context window that they claim to have (I always use the 256k context window versions when I can to avoid this).
We have had “1 million” context windows since 2023, the reason you never heard of them or used them before is because they aren’t actually useful above 100k tokens usually.
The issue with long context models has not been architecture, it has been data, which I can fairly confidently say that these guys have not solved.
In their release they seem to be claiming to have trained the whole thing from scratch, which cannot be the case.
Their score (which is higher than DeepSeek V4’s btw) means that they have been able to train a frontier model (better than all the Chinese labs) for less than $30 million (the total amount of funding that Subquadratic has raised so far) from scratch.
If they were really able to do that, that would be the headline instead of their sparse attention architecture.
In reality this is most likely a Qwen (or Kimi or DeepSeek) model. They replaced the attention architecture with their custom variant, and then trained it on the benchmarks that they wanted it to do well on.
If they really made a sparse attention model, then the fact that its only 12x the context window of a normal transformer is kinda sad.
A sparse attention arch should be able to handle 100M context window, also it would be fairly easy to serve, and not need a waitlist like they have right now (from what I can tell nobody has gotten off the waitlist and actually used the model yet).
Overall, this model is a bunch of hype marketing, and they have not actually demonstrated any unique capabilities to deserve the fanfare they have gotten.
Research
How big are closed source LLMs?
A question many people have is how big are the closed source models from OpenAI, Anthropic, and Google?
A researcher wanted to figure this out so they devised a way of measuring it.
We know from observing open source models on factual benchmarks like AA Omniscience that a model’s world knowledge directly scales with the number of parameters it has.
Because of this, we can make a linear regression based on open source model’s sizes and their scores on factual question benchmarks and then use the scores of the closed scores models to estimate their size.
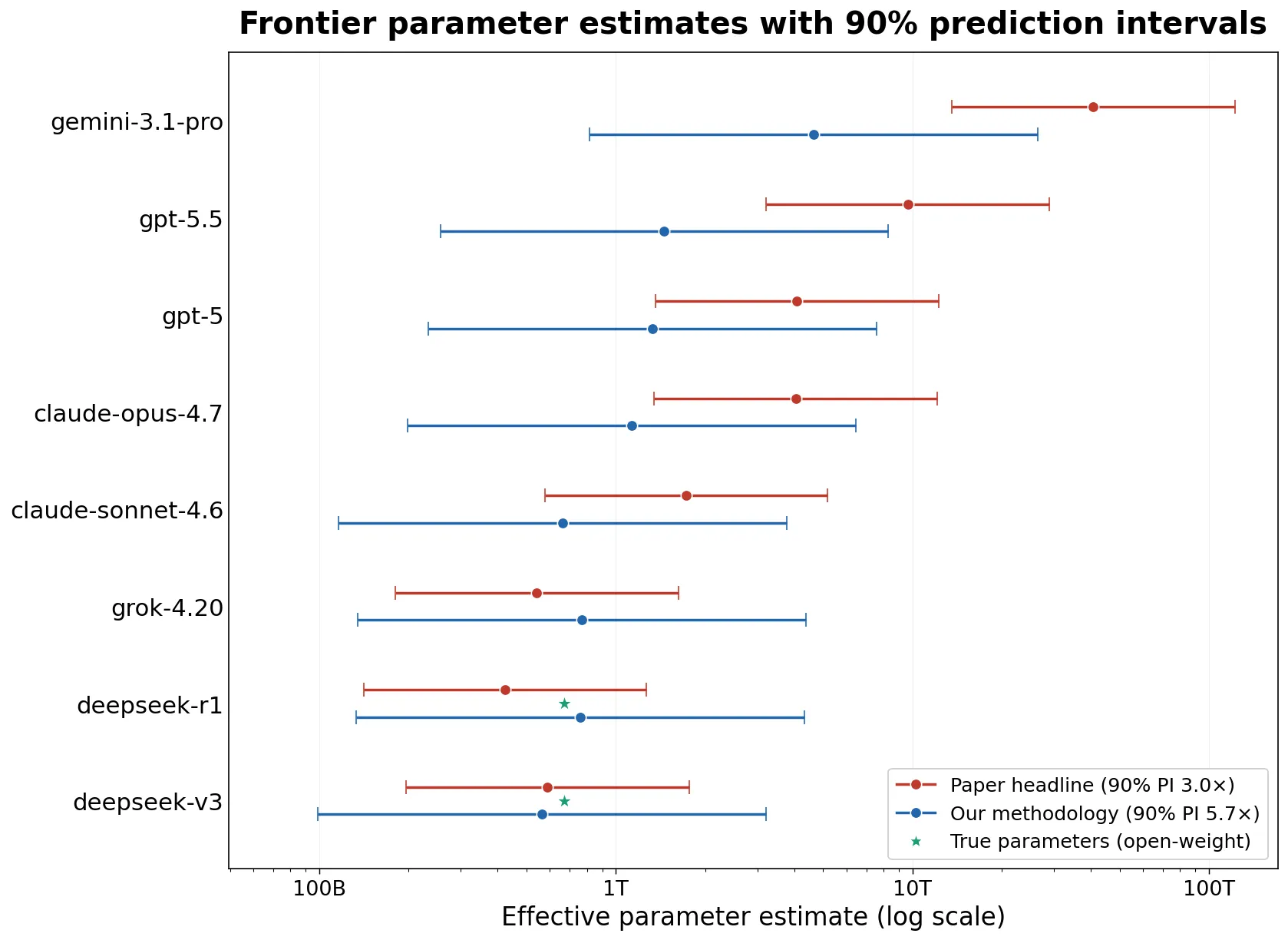
The original paper had the right methodology, but was lacking some implementation details, which was fixed by some guys on Twitter. The “Our methodology” scores are the ones you want to look at.
From the results we find that Sonnet is around 650 billion parameters, Opus 1 trillion, GPT 5.5 1.5 trillion, and Gemini 3.1 Pro 4.6 trillion.
These predictions have large error bars, but give us a good ballpark, and tell us that frontier open source models are not falling behind from the top labs in terms of size.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Realtime anamorphosis by Joanie Lemercier Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Como muitos de vocês provavelmente já sabem, a Anthropic tem enfrentado dificuldades para obter capacidade computacional suficiente para servir seus modelos.
Isso causou a redução dos limites de taxa e também o consumo de mais créditos durante os horários de pico (cobrados com 2x mais do que o normal).
De repente, a Anthropic encontrou um parceiro improvável para ajudá-la: Elon Musk.
A xAI está alugando seu datacenter Colossus 1, com 220 mil GPUs, para a Anthropic, permitindo que ela dobre seu limite de taxa e remova a redução de uso nos horários de pico para os planos de assinatura do Claude Code, além de aumentar drasticamente os limites de taxa da API.
A Anthropic tem sofrido muito com restrições de GPUs, pois havia planejado apenas um crescimento de 10x este ano, mas já está no ritmo de 80x.
Ter acesso a um datacenter de mais de 5 bilhões de dólares ajuda a empresa a recuperar o terreno perdido para atender a essa demanda.
É também uma situação interessante para a xAI, que está abrindo mão de uma grande fatia de sua capacidade computacional para uma empresa pela qual Elon Musk historicamente não tem simpatia.
Muitas pessoas têm chamado isso de cenário do Fazedor de Reis, já que a antipatia de Elon pela Anthropic é menor do que seu ódio por Sam Altman e pela OpenAI, contra quem ele tem um processo judicial aberto.
Para mim, isso muda pouco, pois cancelei minha assinatura da Anthropic em favor de uma da OpenAI, já que o GPT 5.5 é um modelo muito melhor para programação do que o Opus (fora a quantidade mínima de trabalho de frontend que faço).
Lançamentos
SubQ
Muitas pessoas têm falado sobre a nova startup Subquadratic e seu modelo SubQ.
O modelo faz grandes afirmações em termos de avanços arquiteturais: janela de contexto de 12 milhões de tokens, 52x mais rápido que o FlashAttention e 5% do custo do Opus.
Dizer que sou extremamente cético em relação a esse modelo seria um eufemismo.
Para entender o porquê, vamos analisar os benchmarks que eles divulgaram.
O SWE Bench Verified foi desacreditado por seu criador, a OpenAI, pois muitos dos testes estão incorretos, e também por ser provavelmente um dos conjuntos de dados mais sobreajustados que existem — qualquer progresso que vemos nos modelos vem do fato de que eles foram treinados nas respostas, já que essa é a única forma de os modelos passarem nos testes incorretos.
Quanto ao benchmark RULER, os resultados foram bons, mas ele se tornou saturado e desatualizado, sendo também um benchmark público que permite sobreajuste com facilidade.
O MRCR v2 é outro benchmark público e foi recentemente criticado pela Anthropic por não ter correlação com capacidades de contexto longo; a empresa está se concentrando em outros benchmarks, como o GraphWalks, por serem melhores indicadores de desempenho.
É por isso que se observa uma grande queda nas pontuações do Opus 4.6 e Opus 4.7 nesses resultados.
Então os benchmarks divulgados são sem sentido — e quanto à afirmação de janela de contexto de 12 milhões de tokens?
Isso também é enganoso.
Já falei antes sobre janelas de contexto longo, e o principal problema é que simplesmente não temos dados de contexto longo significativos suficientes para treinar os modelos.
Do ponto de vista de hardware, arquiteturas como a DeepSeek V4 já poderiam facilmente lidar com janelas de contexto de 10+ milhões de tokens; o problema é que haveria uma degradação massiva de desempenho, pois o modelo nunca foi exposto a dados com mais de 1 milhão de tokens durante o treinamento.
Só nos últimos 3 a 6 meses os laboratórios de ponta como Anthropic e OpenAI conseguiram obter resultados consistentes com até 256k tokens, quanto mais a janela de contexto máxima de 1 milhão de tokens que afirmam ter (eu sempre uso as versões com janela de contexto de 256k quando possível para evitar esse problema).
Temos tido janelas de contexto de “1 milhão” de tokens desde 2023; o motivo pelo qual você nunca ouviu falar delas ou as usou antes é porque geralmente não são realmente úteis acima de 100 mil tokens.
O problema com os modelos de contexto longo não tem sido a arquitetura, mas os dados — e posso afirmar com bastante confiança que esse pessoal não resolveu isso.
No lançamento deles, parecem afirmar ter treinado tudo do zero, o que não pode ser verdade.
A pontuação deles (que é maior que a do DeepSeek V4, aliás) significa que conseguiram treinar um modelo de ponta (melhor do que todos os laboratórios chineses) por menos de 30 milhões de dólares (o total de financiamento levantado pela Subquadratic até agora) do zero.
Se realmente fossem capazes disso, esse seria o grande destaque, e não a arquitetura de atenção esparsa.
Na realidade, isso é muito provavelmente um modelo Qwen (ou Kimi ou DeepSeek). Eles substituíram a arquitetura de atenção por sua variante personalizada e depois o treinaram nos benchmarks em que queriam que ele se saísse bem.
Se realmente criaram um modelo de atenção esparsa, o fato de ter apenas 12x a janela de contexto de um transformer normal é um tanto decepcionante.
Uma arquitetura de atenção esparsa deveria ser capaz de lidar com janelas de contexto de 100 milhões de tokens, além de ser relativamente fácil de servir e não precisar de uma lista de espera como a que têm agora (pelo que posso dizer, ninguém ainda conseguiu sair da lista de espera e usar o modelo de verdade).
No geral, esse modelo é pura propaganda de marketing e eles não demonstraram nenhuma capacidade única que justifique o alvoroço que geraram.
Pesquisa
Qual o tamanho dos LLMs de código fechado?
Uma pergunta que muita gente faz é: qual o tamanho dos modelos de código fechado da OpenAI, Anthropic e Google?
Um pesquisador quis descobrir isso e criou uma forma de medi-lo.
Sabemos, ao observar modelos de código aberto em benchmarks factuais como o AA Omniscience, que o conhecimento de mundo de um modelo escala diretamente com o número de parâmetros que ele possui.
Por causa disso, podemos fazer uma regressão linear baseada no tamanho dos modelos de código aberto e suas pontuações em benchmarks de perguntas factuais, e então usar as pontuações dos modelos de código fechado para estimar seu tamanho.
O artigo original tinha a metodologia correta, mas faltavam alguns detalhes de implementação, que foram corrigidos por alguns caras no Twitter. As pontuações de “Nossa metodologia” são as que você deve observar.
Com os resultados, descobrimos que o Sonnet tem em torno de 650 bilhões de parâmetros, o Opus 1 trilhão, o GPT 5.5 1,5 trilhão e o Gemini 3.1 Pro 4,6 trilhões.
Essas estimativas têm grandes margens de erro, mas nos dão uma boa aproximação e mostram que os modelos de código aberto de ponta não estão ficando para trás dos principais laboratórios em termos de tamanho.
Encerramento
Espero que tenham gostado das notícias desta semana. Se quiserem receber as novidades toda semana, não deixem de se inscrever em nossa lista de e-mails abaixo.
Anamorfose em tempo real por Joanie Lemercier Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
Anthropic se asocia con SpaceX
Como muchos de ustedes probablemente ya saben, Anthropic ha tenido dificultades para obtener suficiente capacidad de cómputo para servir sus modelos.
Esto ha provocado que los límites de velocidad disminuyan, y también que se consuman más créditos durante las horas pico (se facturan al doble de lo normal).
De repente, Anthropic ha encontrado un socio inesperado para ayudarles: Elon Musk.
xAI está alquilando su centro de datos Colossus 1 con 220k GPUs a Anthropic, lo que les permite duplicar su límite de velocidad y eliminar la reducción de uso en horas pico para los planes de suscripción de Claude Code, además de incrementar drásticamente los límites de velocidad de la API.
Anthropic ha tenido una fuerte restricción de GPUs, ya que solo habían planificado un crecimiento de 10x este año, pero ya van camino a un 80x.
Obtener acceso a un centro de datos valorado en más de 5 mil millones de dólares les ayuda a ponerse al día para satisfacer esta demanda.
También resulta interesante para xAI, ya que están cediendo una gran parte de su capacidad de cómputo a una empresa de la que históricamente Elon Musk no ha sido fan.
Mucha gente ha calificado esto como un escenario de “Kingmaker” (hacedor de reyes), ya que el desagrado de Elon hacia Anthropic es menor que su odio hacia Sam Altman y OpenAI, contra quienes tiene una demanda abierta.
Para mí esto cambia poco, ya que he cancelado mi suscripción a Anthropic a favor de una de OpenAI, dado que GPT 5.5 es un modelo mucho mejor para programar que Opus (fuera de la mínima cantidad de trabajo de frontend que hago).
Lanzamientos
SubQ
Mucha gente ha estado hablando de la nueva startup Subquadratic y su modelo SubQ.
El modelo hace grandes afirmaciones en cuanto a avances arquitectónicos: una ventana de contexto de 12 millones de tokens, 52x más rápido que FlashAttention, y con un costo del 5% respecto a Opus.
Decir que soy extremadamente escéptico respecto a este modelo sería quedarse corto.
Para entender por qué, veamos los benchmarks que publicaron.
SWE Bench Verified ha sido desacreditado por su creador OpenAI, ya que muchas de las pruebas son incorrectas, y además es probablemente uno de los conjuntos de datos más sobreajustados que existen, siendo cualquier progreso que veamos en los modelos resultado del hecho de que han sido entrenados con las respuestas, pues esa es la única forma de que los modelos superen las pruebas incorrectas.
En cuanto al benchmark RULER, los resultados eran buenos, pero se ha vuelto saturado y obsoleto, y al ser un benchmark público permite el sobreajuste con facilidad.
MRCR v2 es otro benchmark público, y recientemente ha sido señalado por Anthropic por no estar correlacionado con las capacidades de contexto largo, centrándose en cambio en otros benchmarks como GraphWalks, ya que son un mejor indicador del rendimiento.
Por eso se observa una gran caída en las puntuaciones de Opus 4.6 y Opus 4.7.
Entonces, los benchmarks que publicaron carecen de sentido. ¿Qué hay de la afirmación de la ventana de contexto de 12 millones de tokens?
Esto también es falso.
He hablado antes sobre las ventanas de contexto largo, y el principal problema es que simplemente no tenemos datos de contexto largo suficientemente significativos para entrenar los modelos.
Desde una perspectiva de hardware, arquitecturas como DeepSeek V4 ya podrían manejar fácilmente ventanas de contexto de 10+ millones de tokens; el problema es que se vería una degradación masiva del rendimiento, ya que el modelo en realidad nunca ha procesado datos de más de 1 millón de tokens.
No ha sido hasta los últimos 3-6 meses cuando los laboratorios de frontera como Anthropic y OpenAI han podido obtener resultados consistentes hasta los 256k tokens, y mucho menos con la ventana de contexto máxima de 1 millón de tokens que afirman tener (yo siempre uso las versiones con ventana de contexto de 256k cuando puedo para evitar esto).
Hemos tenido ventanas de contexto de “1 millón” desde 2023; la razón por la que nunca las escucharon o usaron antes es porque generalmente no son útiles por encima de los 100k tokens.
El problema con los modelos de contexto largo no ha sido la arquitectura, sino los datos, y puedo decir con bastante confianza que estos chicos no lo han resuelto.
En su lanzamiento parecen afirmar haber entrenado todo desde cero, lo cual no puede ser cierto.
Su puntuación (que, por cierto, supera a la de DeepSeek V4) significa que habrían sido capaces de entrenar un modelo de frontera (mejor que todos los laboratorios chinos) por menos de 30 millones de dólares (el monto total de financiamiento que Subquadratic ha recaudado hasta ahora) desde cero.
Si realmente hubieran podido hacer eso, ese sería el titular, no su arquitectura de atención dispersa.
En realidad, lo más probable es que sea un modelo Qwen (o Kimi o DeepSeek). Reemplazaron la arquitectura de atención con su variante personalizada, y luego lo entrenaron en los benchmarks en los que querían que se desempeñara bien.
Si realmente crearon un modelo de atención dispersa, el hecho de que su ventana de contexto sea solo 12x la de un transformer normal es bastante decepcionante.
Una arquitectura de atención dispersa debería poder manejar una ventana de contexto de 100M de tokens, y además sería bastante fácil de servir, sin necesitar una lista de espera como la que tienen ahora (por lo que puedo ver, nadie ha salido de la lista de espera y usado el modelo todavía).
En general, este modelo es puro marketing de hype, y no han demostrado ninguna capacidad única que justifique la fanfarria que han recibido.
Investigación
¿Qué tan grandes son los LLMs propietarios?
Una pregunta que mucha gente se hace es: ¿qué tan grandes son los modelos propietarios de OpenAI, Anthropic y Google?
Un investigador quiso averiguarlo y desarrolló un método para medirlo.
Sabemos, a partir de la observación de modelos de código abierto en benchmarks de conocimiento factual como AA Omniscience, que el conocimiento del mundo de un modelo escala directamente con el número de parámetros que tiene.
Gracias a esto, podemos hacer una regresión lineal basada en los tamaños de los modelos de código abierto y sus puntuaciones en benchmarks de preguntas factuales, y luego usar las puntuaciones de los modelos propietarios para estimar su tamaño.
El artículo original tenía la metodología correcta, pero carecía de algunos detalles de implementación, que fueron corregidos por algunos usuarios en Twitter. Las puntuaciones de “Nuestra metodología” son las que deben tener en cuenta.
A partir de los resultados encontramos que Sonnet tiene alrededor de 650 mil millones de parámetros, Opus 1 billón, GPT 5.5 1,5 billones, y Gemini 3.1 Pro 4,6 billones.
Estas predicciones tienen grandes márgenes de error, pero nos dan una buena estimación y nos dicen que los modelos de código abierto de frontera no están quedando atrás respecto a los principales laboratorios en términos de tamaño.
Cierre
Espero que hayan disfrutado las noticias de esta semana. Si quieren recibir las noticias cada semana, asegúrense de unirse a nuestra lista de correo a continuación.
Anamorfosis en tiempo real by Joanie Lemercier