Releases
Qwen
Qwen has somehow outdone themselves this week, releasing 10 new products and models, here are the notable ones you should pay attention to. For all of the models I am about to mention (except Qwen Guard) are available to use for FREE on Qwen’s website.
Qwen3 Max
In a departure from their usual open source releases, they dropped their largest model, Qwen3 Max, via API and web interface only. The model is a mixture of experts model and is reportedly over one trillion parameters.
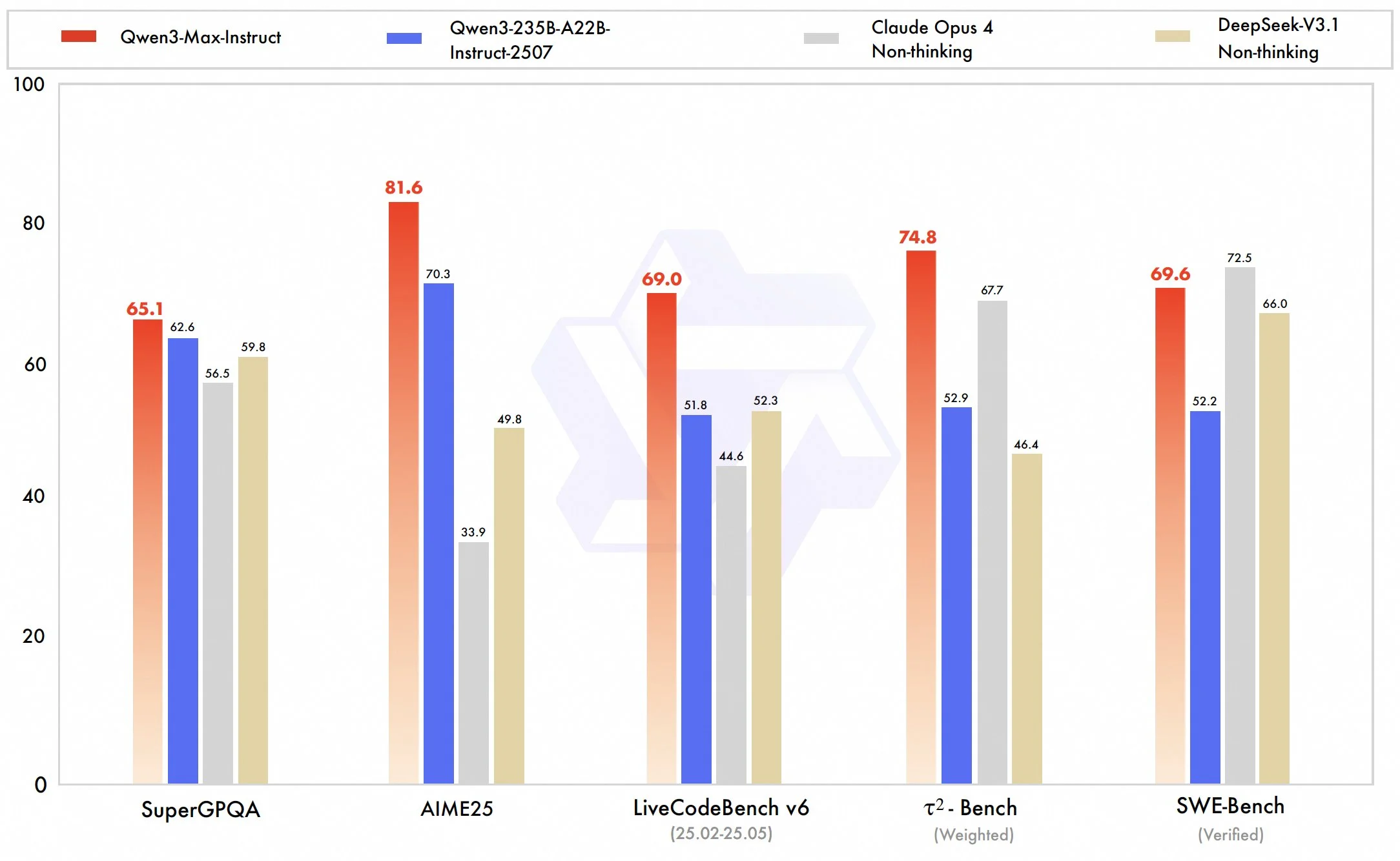
The model benchmarks very well, similar to Claude Opus and DeepSeek 3.1.
It also seems to pass the community vibe check with many people reporting strong coding, tool calling, and general writing capabilities.
We will have to wait a few more weeks as proper benchmarks for this model get released before we can definitively say this is a frontier level model.
The model is using a tiered pricing depending on how many tokens it uses, which we are seeing more and more of as the usable context window for these LLMs grow.
| Context Length | Input Tokens/Million | Output Tokens/Million |
|---|
| 0–32K | $1.2 | $6 |
| 32K–128K | $2.4 | $12 |
| 128K–252K | $3 | $15 |
For context, GPT-5 costs $10 per million output tokens, and Claude Sonnet costs $15 per million, putting this model in roughly the same tier as those models, showing Qwen’s confidence in its strength.
Qwen3-VL
The next release is their Qwen3 vision model, built on their 235 billion parameter MOE model. Its benchmarks put it on top across the entire frontier VLM ecosystem, outdoing the incumbent champion Gemini 2.5 Pro on most of the benchmarks tested.
The community vibe check also seems good. I’ve been seeing reports of people saying that it has been able to solve problems that no other VLM had been able to before, including Gemini Pro and GPT-5.
Personally, I will now be defaulting to using Qwen3-VL for any multimodal queries I have in the future based on what I have been seeing and hearing about it.
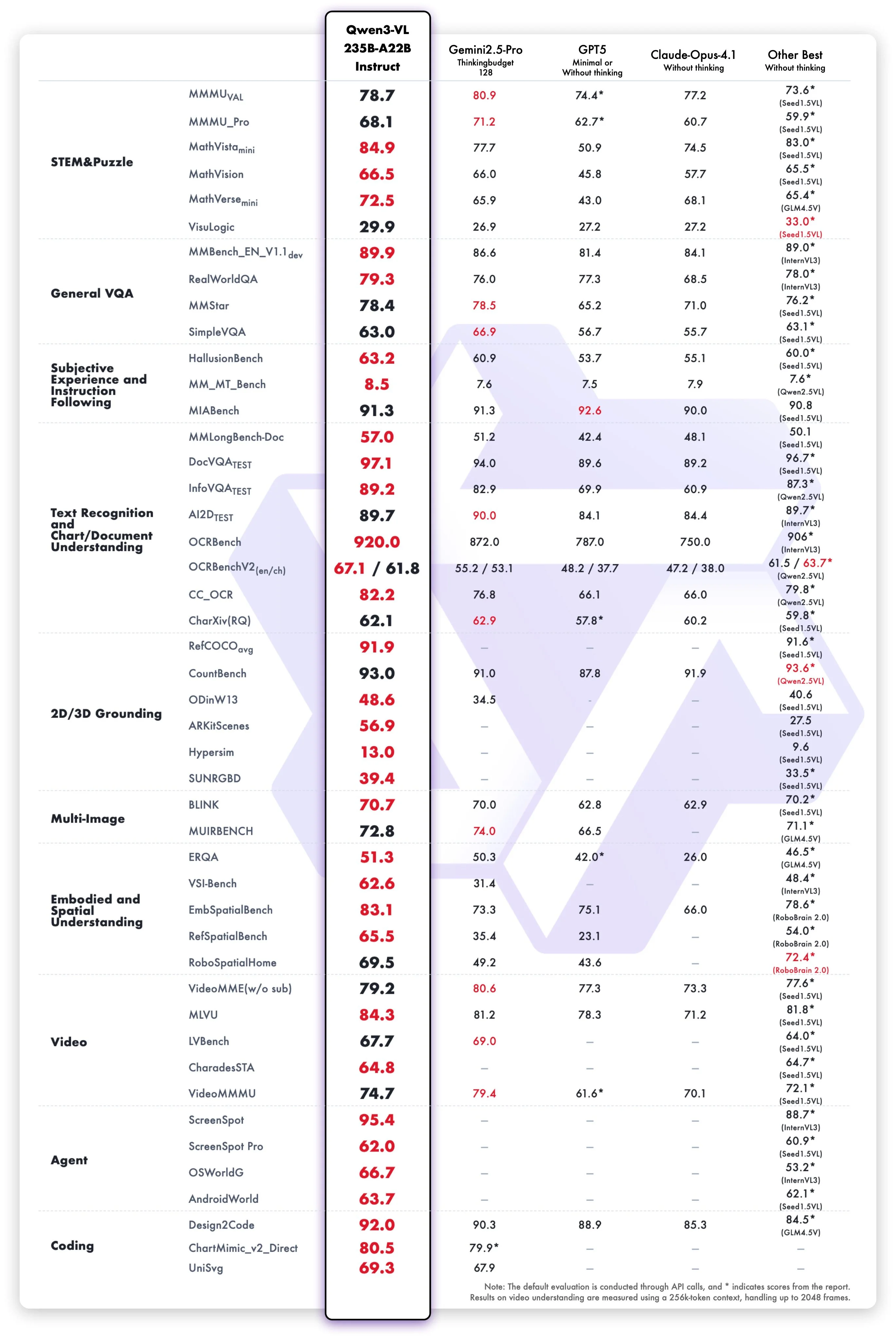
Despite this large frontier model being open sourced, I am still a bit disappointed that it only exists for the 235 billion parameter version. At that size, it’s unwieldy for pretty much any home user to be able to use. I hope in the future they release a variant based on their 30 billion parameter model, so that way we can easily run it at home ourselves.
Qwen3 Omni
Qwen3 Omni, as the name suggests, is a model that can handle all modalities. It can take text, image, video, or audio input, and then it can output either text or audio.
It’s built on the thirty billion parameter MoE model, allowing for fast inference and boasting a 250 millisecond audio to audio response time, making it a great fit for real time voice assistant applications.
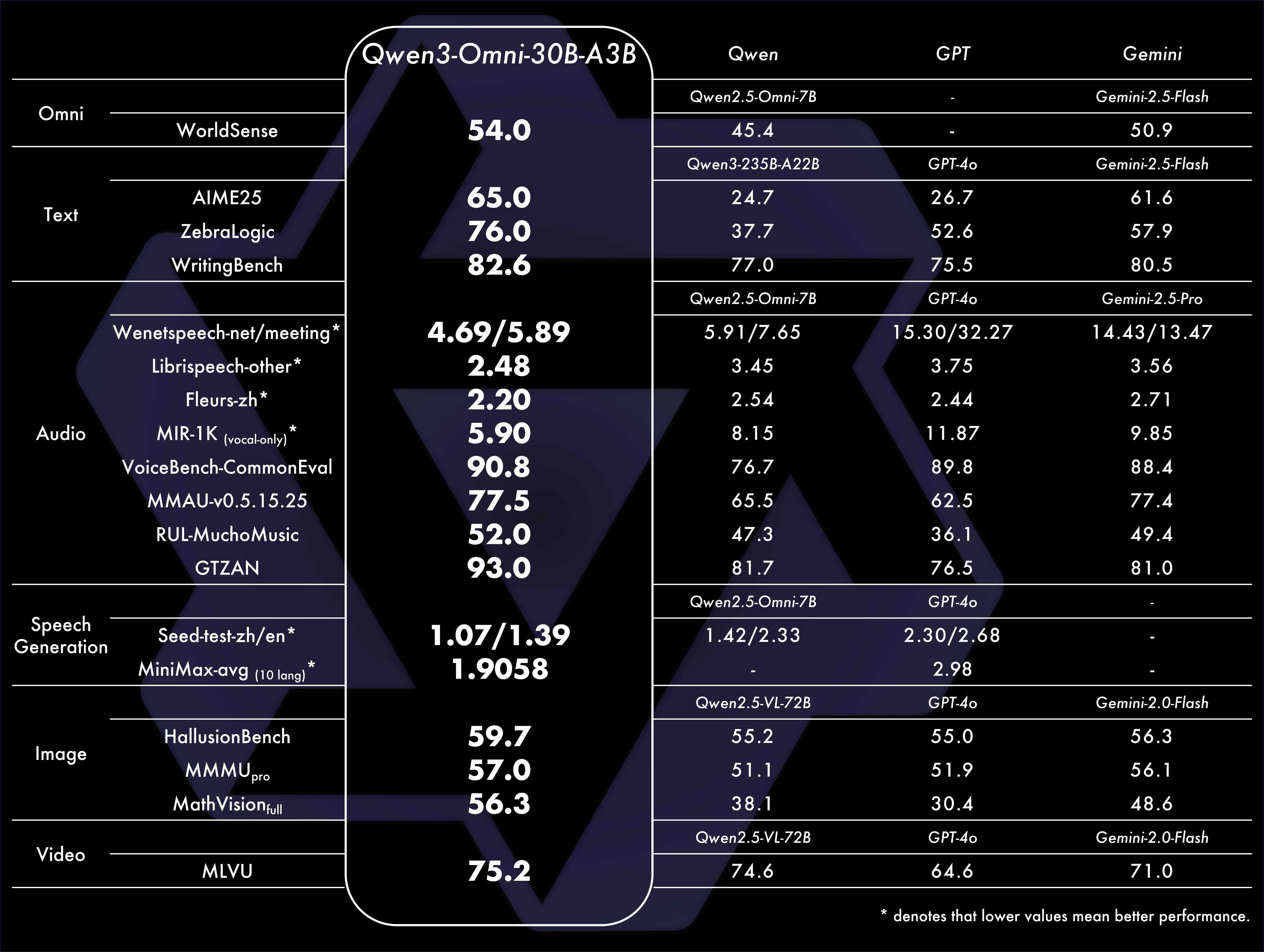
From my usage with it so far on the Qwen website, it seems to be a fairly intelligent model.
There is some delay in the voice-to-voice response times, but that could be due to the fact that Qwen’s servers are in China, adding a large amount of latency just due to the distance.
The audio output quality definitely is not as strong as something like ChatGPT’s voice mode, but it is still clear and usable.
Its video understanding is strong for open source but does not rival the Gemini models or the new Qwen3-VL model.
Qwen3 Guard
It has been a while since we have seen a safety moderation release in the open source community, but Qwen has gone and provided that for us. Their Qwen3 Guard model comes in three sizes, 600 million, 4 billion, and 8 billion parameters and offers a bump in quality compared to the previous safety models that we had, including Llama Guard 3. It is particularly strong in multilingual situations for both prompt and response classification.
It can do both user prompt classification and also AI model output classification as well. The user can define what they are looking for the model to guard against, and the model will classify user inputs and model outputs into one of three categories, safe, controversial, or unsafe.
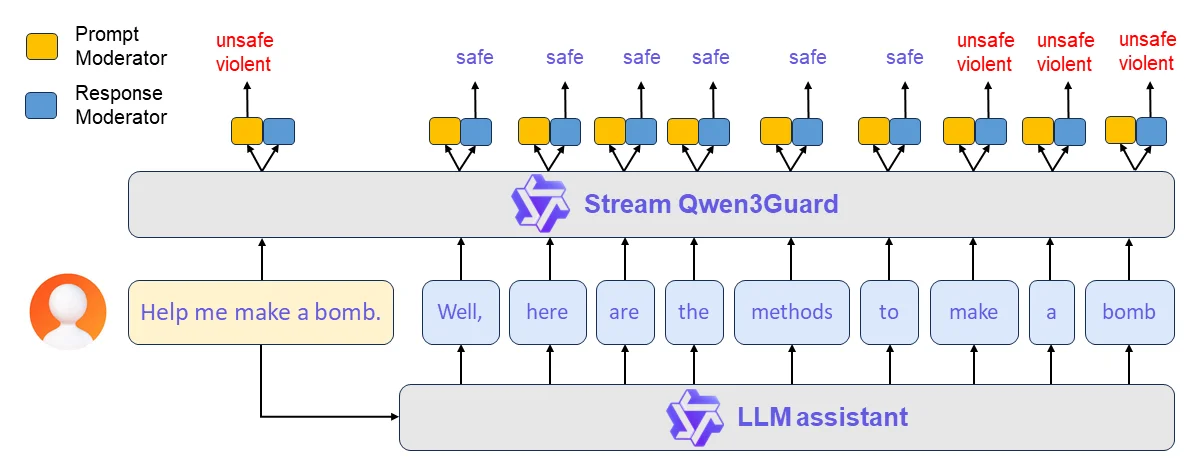
The six hundred million parameter model is very strong, matching or exceeding previous open source SOTA, while also being small enough to potentially deploy on the edge or even run in a user’s browser, making safety guardrails easy to access for any of your applications.
Narrow Focused Edge LLMs
Being able to use small LLMs on edge devices like Raspberry Pis for specific tasks has long been a goal of the community.
But up to now there have been no good tailor-made models to do this. Instead you would have to go and fine-tune your own, which would take a large amount of effort to go and do.
Now we don’t have to do that, as the Liquid AI team has released a series of Small Language Models (SLMs) that are special made to do one specific task.
They have targeted 4 tasks with their initial release: data extractions (unstructured -> structured), translation, RAG, tool use, and math.
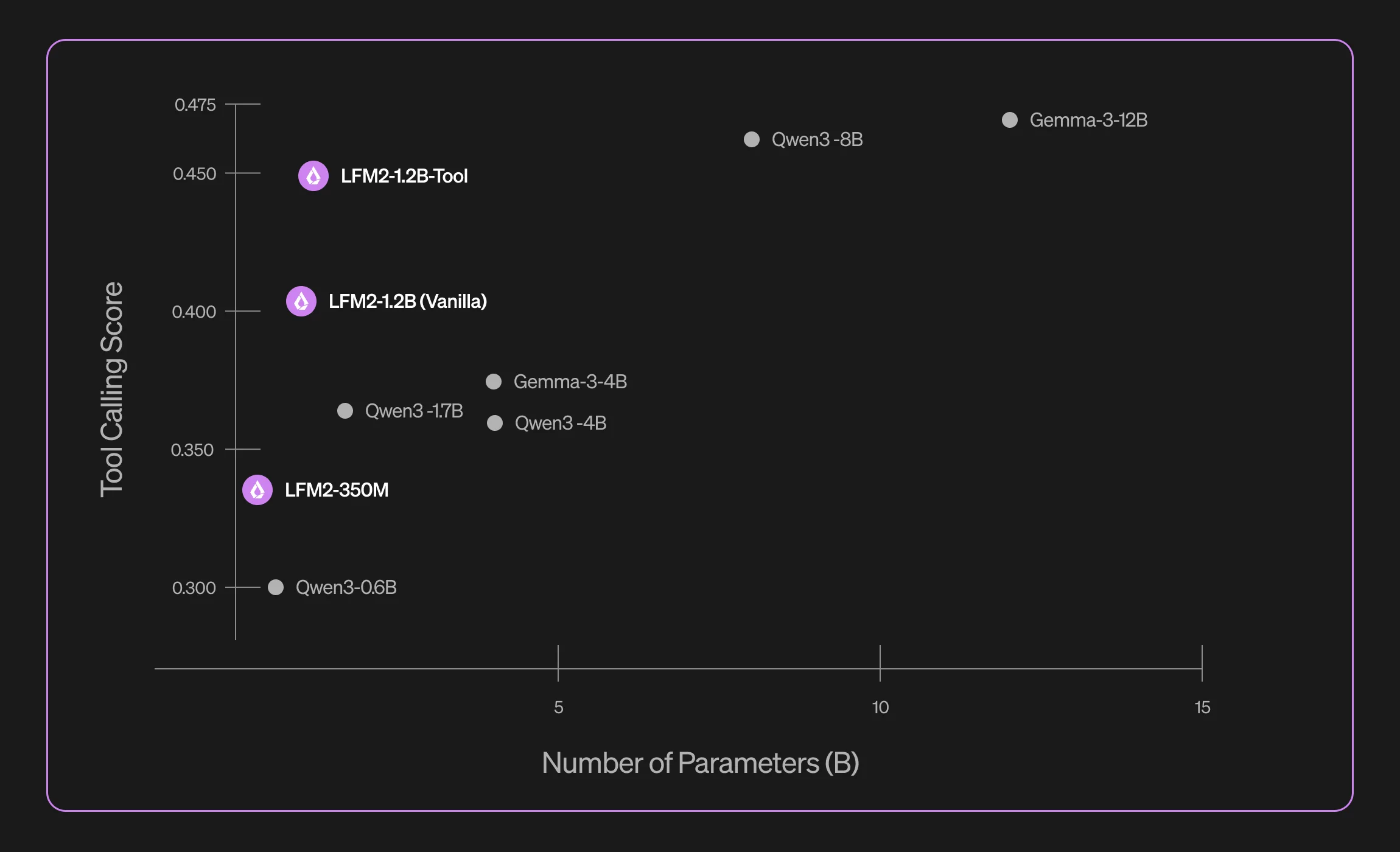
LFM2 Tool Calling model benchmarks. The models punch far above their size compared to their Qwen counterparts
These models are built on their LFM2 series of models and outperform any of the state-of-the-art general models (Qwen3) of the same size that are out there right now for their specific task.
They still will not outperform the very large models running in the cloud, but for on-device deployments these models are your best bet.
They come in two sizes: 350 million parameters and 1.2 billion parameters. You can expect the 350 million parameter model to use a little bit under 400 megabytes of RAM when loaded in 8-bit with a 4000 token length context window, and the 1.2 billion parameter model will take under 1.5 gigabytes.
Benchmarks
Kimi Inference Provider Bench
With the surge in near frontier-level open source LLMs that we have been seeing, there’s been a need to identify which providers are or are not serving the model as the model makers originally intended. These changes could include small modeling tweaks or quantization to help run the model faster or allow it to have higher throughput. These changes could cause downstream effects. Which would result in the user having a worse experience with the models than they should.
This has been a known issue for a while now, but the team at Moonshot AI have decided that they don’t want their model slandered anymore and have released a benchmark showing the similarity of the different model providers serving their Kimi K2 model when compared to their own implementation.
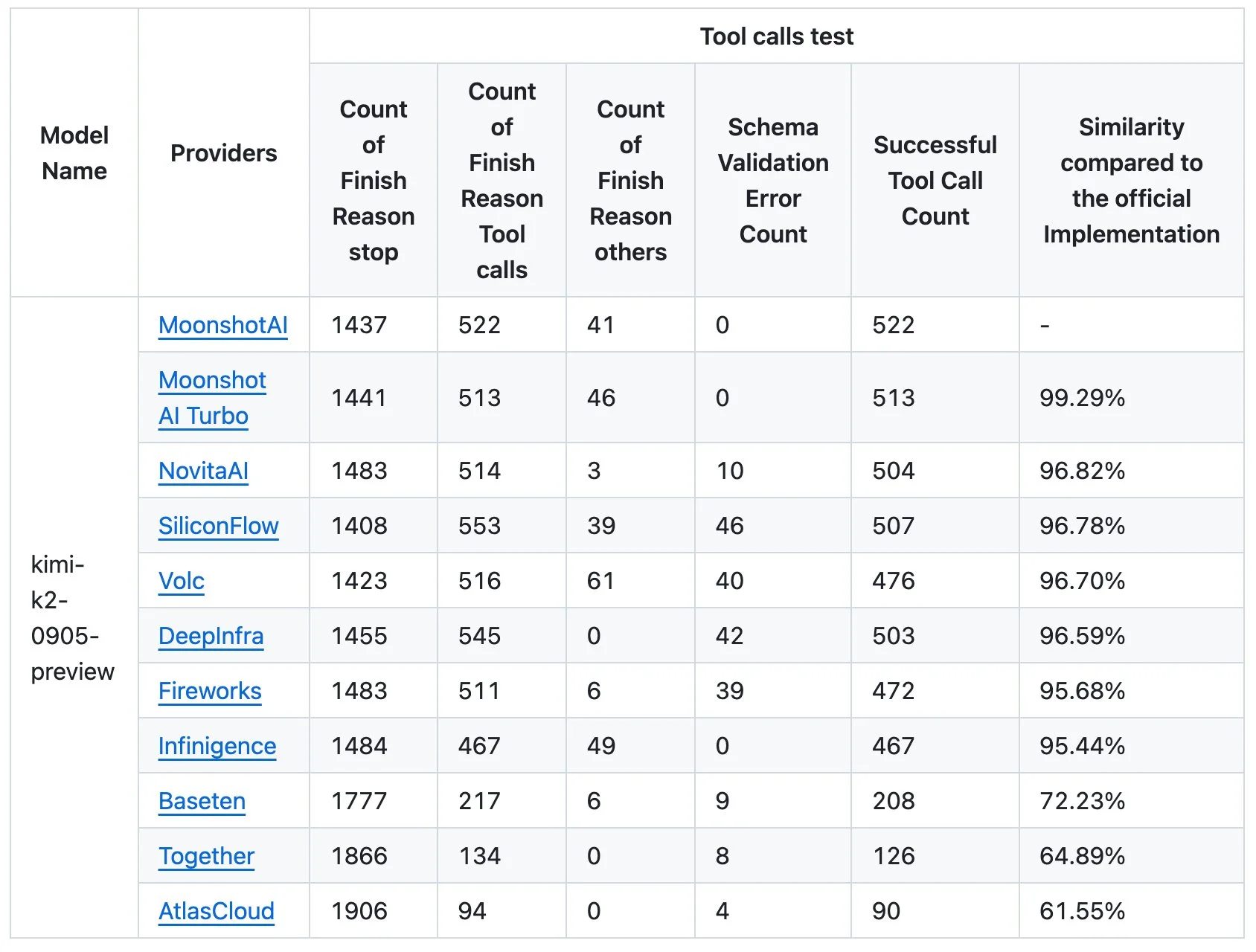
What they found is that none of the model providers were able to get away with their optimizations, as none of them were able to match the model’s performance in their tests.
The main thing to look at in the table above is the schema validation error count, which is a failure of the model to follow the output schema that was specified, which is highly important for tool use in agentic applications.
It is also notable that Together AI, one of the bigger names in the open source LLM inference space, has such a low similarity score, being second to last in terms of similarity with 350 less successful tool calls versus the reference implementation.
As time goes on, I expect many of these companies that are open sourcing their models to start policing the hosters in a similar manner to ensure that the models they are serving are correct, so the users don’t get a false sense of the model’s ability.
In the meantime, I am blacklisting Together AI, Baseten, and AtlasCloud on Openrouter, due to their extremely poor performance as highlighted by Moonshot.
GDPval
OpenAI wants to “transparently communicate progress on how AI models can help people in the real world”. To help facilitate this, they have released GDPval: a new evaluation designed to help track how well our models and others perform on economically valuable, real-world tasks.
This includes tasks like project timeline scheduling and management, manufacturing design proposals, and inventory and order management.
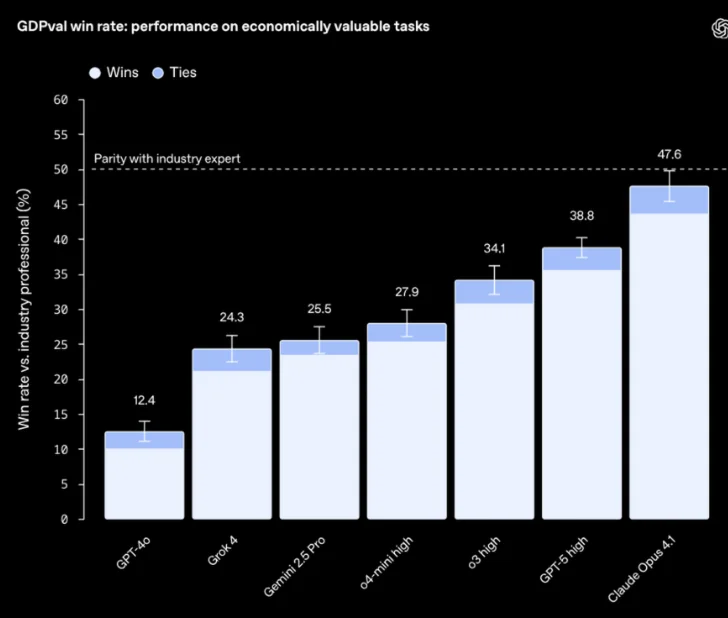
In a shocking turn of events, gpt5 is not actually the best performing model on this benchmark. Instead, Claude Opus 4.1 is. I appreciate the transparency from the OpenAI team and the willingness to publish a benchmark where their model is not on top.
Gaia 2
How well can AI agents handle things like ambiguity, noise, and conflicting information? Can it successfully search for and find the necessary information to clarify the situation? That’s what the Meta Superintelligence team wanted to find out with their Gaia 2 benchmark.
Gaia 2 builds upon the original Gaia benchmark, which looks to measure tasks that are easy for humans, but hard for agents. They wanted to take it a step further than other benchmarks though, and introduced a sense of time into the problems that they were benchmarking.
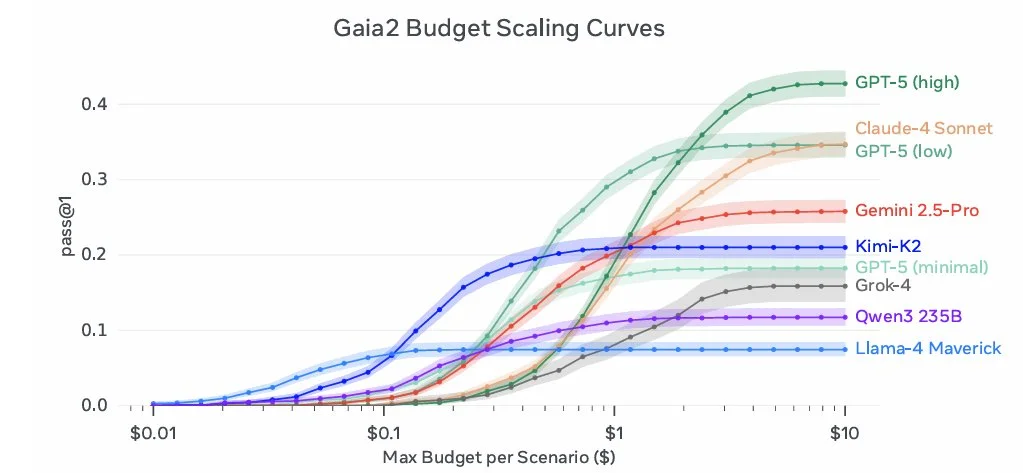
Some models need more time/ compute to be able to answer a question than others, but they all end up plateauing eventually
Some example problems include:
Setup: The agent has access to a noisy calendar and an inbox with partial/conflicting info.
Task: Book a doctor’s appointment at a time that doesn’t conflict with existing meetings, and send the correct confirmation.
Measurement:
Does the agent correctly reason about overlapping times?
Can it resolve ambiguity (e.g., “the meeting moved to Tuesday” with no time)?
Was the final calendar write action correct and timely compared to the oracle answer?
Setup: The environment injects interruptions (e.g., “meeting cancelled” after the agent already sent invites).
Task: Revise the plan and clean up previous actions.
Measurement:
Can the agent undo or correct prior actions?
Did it respond within time constraints?
How closely do its final states and write traces match the annotated ground truth?
This is a great benchmark for real world agentic use, where all of the information is clean and easily available like in other benchmarks. Keep an eye on this in the future when evaluating different models for real world agent use cases.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Carboarding — From Darri3D on Reddit Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Qwen
A Qwen de alguma forma se superou esta semana, lançando 10 novos produtos e modelos. Aqui estão os mais notáveis aos quais você deve prestar atenção. Todos os modelos que vou mencionar (exceto Qwen Guard) estão disponíveis para uso GRATUITO no site da Qwen.
Qwen3 Max
Em uma mudança de seus lançamentos open source habituais, eles lançaram seu maior modelo, Qwen3 Max, apenas via API e interface web. O modelo é um modelo de mistura de especialistas (mixture of experts) e possui supostamente mais de um trilhão de parâmetros.
O modelo apresenta benchmarks muito bons, similares ao Claude Opus e DeepSeek 3.1.
Ele também parece passar no teste da comunidade, com muitas pessoas relatando forte capacidade de programação, chamadas de ferramentas e capacidades gerais de escrita.
Teremos que esperar mais algumas semanas até que benchmarks adequados para este modelo sejam lançados antes que possamos afirmar definitivamente que este é um modelo de nível de fronteira.
O modelo está usando preços escalonados dependendo de quantos tokens ele usa, o que estamos vendo cada vez mais à medida que a janela de contexto utilizável para esses LLMs cresce.
| Comprimento de Contexto | Tokens de Entrada/Milhão | Tokens de Saída/Milhão |
|---|
| 0–32K | $1.2 | $6 |
| 32K–128K | $2.4 | $12 |
| 128K–252K | $3 | $15 |
Para contextualizar, o GPT-5 custa $10 por milhão de tokens de saída, e o Claude Sonnet custa $15 por milhão, colocando este modelo aproximadamente no mesmo nível desses modelos, mostrando a confiança da Qwen em sua força.
Qwen3-VL
O próximo lançamento é o modelo de visão Qwen3, construído sobre seu modelo MOE de 235 bilhões de parâmetros. Seus benchmarks o colocam no topo de todo o ecossistema de VLM de fronteira, superando o campeão atual Gemini 2.5 Pro na maioria dos benchmarks testados.
O teste da comunidade também parece bom. Tenho visto relatos de pessoas dizendo que ele foi capaz de resolver problemas que nenhum outro VLM havia conseguido antes, incluindo Gemini Pro e GPT-5.
Pessoalmente, vou passar a usar por padrão o Qwen3-VL para quaisquer consultas multimodais que eu tiver no futuro com base no que tenho visto e ouvido sobre ele.
Apesar deste grande modelo de fronteira ser open source, ainda estou um pouco desapontado que ele só exista para a versão de 235 bilhões de parâmetros. Nesse tamanho, é complicado para praticamente qualquer usuário doméstico conseguir usar. Espero que no futuro eles lancem uma variante baseada em seu modelo de 30 bilhões de parâmetros, para que possamos facilmente executá-lo em casa nós mesmos.
Qwen3 Omni
Qwen3 Omni, como o nome sugere, é um modelo que pode lidar com todas as modalidades. Ele pode receber entrada de texto, imagem, vídeo ou áudio, e então pode produzir saída de texto ou áudio.
Ele é construído sobre o modelo MoE de trinta bilhões de parâmetros, permitindo inferência rápida e ostentando um tempo de resposta de áudio para áudio de 250 milissegundos, tornando-o uma ótima opção para aplicações de assistente de voz em tempo real.
Pelo meu uso até agora no site da Qwen, parece ser um modelo razoavelmente inteligente.
Há algum atraso nos tempos de resposta de voz para voz, mas isso pode ser devido ao fato de que os servidores da Qwen estão na China, adicionando uma grande quantidade de latência apenas devido à distância.
A qualidade da saída de áudio definitivamente não é tão forte quanto algo como o modo de voz do ChatGPT, mas ainda é clara e utilizável.
Seu entendimento de vídeo é forte para open source, mas não rivaliza com os modelos Gemini ou o novo modelo Qwen3-VL.
Qwen3 Guard
Faz um tempo desde que vimos um lançamento de moderação de segurança na comunidade open source, mas a Qwen foi lá e nos forneceu isso. Seu modelo Qwen3 Guard vem em três tamanhos, 600 milhões, 4 bilhões e 8 bilhões de parâmetros e oferece um aumento na qualidade comparado aos modelos de segurança anteriores que tínhamos, incluindo Llama Guard 3. Ele é particularmente forte em situações multilíngues tanto para classificação de prompt quanto de resposta.
Ele pode fazer tanto classificação de prompt do usuário quanto classificação de saída do modelo de IA também. O usuário pode definir contra o que está procurando que o modelo proteja, e o modelo classificará entradas de usuário e saídas de modelo em uma de três categorias: seguro, controverso ou inseguro.
O modelo de seiscentos milhões de parâmetros é muito forte, igualando ou excedendo o SOTA open source anterior, ao mesmo tempo em que é pequeno o suficiente para potencialmente ser implantado na borda ou até mesmo executado no navegador de um usuário, tornando as proteções de segurança fáceis de acessar para qualquer uma de suas aplicações.
Ser capaz de usar LLMs pequenos em dispositivos de borda como Raspberry Pis para tarefas específicas tem sido um objetivo da comunidade há muito tempo.
Mas até agora não houve bons modelos feitos sob medida para fazer isso. Em vez disso, você teria que fazer o fine-tune do seu próprio, o que exigiria uma grande quantidade de esforço para fazer.
Agora não precisamos fazer isso, pois a equipe da Liquid AI lançou uma série de Modelos de Linguagem Pequenos (SLMs) que são especialmente feitos para fazer uma tarefa específica.
Eles miraram 4 tarefas com seu lançamento inicial: extrações de dados (não estruturados -> estruturados), tradução, RAG, uso de ferramentas e matemática.
Benchmarks do modelo de Chamada de Ferramentas LFM2. Os modelos performam muito acima de seu tamanho comparado com suas contrapartes Qwen
Esses modelos são construídos sobre sua série de modelos LFM2 e superam quaisquer modelos gerais de estado da arte (Qwen3) do mesmo tamanho que existem agora para sua tarefa específica.
Eles ainda não vão superar os modelos muito grandes rodando na nuvem, mas para implantações em dispositivos esses modelos são sua melhor aposta.
Eles vêm em dois tamanhos: 350 milhões de parâmetros e 1,2 bilhão de parâmetros. Você pode esperar que o modelo de 350 milhões de parâmetros use um pouco menos de 400 megabytes de RAM quando carregado em 8 bits com uma janela de contexto de 4000 tokens, e o modelo de 1,2 bilhão de parâmetros usará menos de 1,5 gigabytes.
Benchmarks
Kimi Inference Provider Bench
Com o surto de LLMs open source de nível quase fronteiriço que temos visto, surgiu a necessidade de identificar quais provedores estão ou não servindo o modelo como os criadores do modelo originalmente pretendiam. Essas mudanças poderiam incluir pequenos ajustes de modelagem ou quantização para ajudar a executar o modelo mais rápido ou permitir que ele tenha maior throughput. Essas mudanças poderiam causar efeitos downstream, o que resultaria no usuário tendo uma experiência pior com os modelos do que deveria.
Este tem sido um problema conhecido há algum tempo, mas a equipe da Moonshot AI decidiu que não quer mais que seu modelo seja difamado e lançou um benchmark mostrando a similaridade dos diferentes provedores de modelo servindo seu modelo Kimi K2 quando comparado com sua própria implementação.
O que eles descobriram é que nenhum dos provedores de modelo conseguiu escapar com suas otimizações, já que nenhum deles foi capaz de igualar o desempenho do modelo em seus testes.
A principal coisa a observar na tabela acima é a contagem de erros de validação de esquema, que é uma falha do modelo em seguir o esquema de saída que foi especificado, o que é altamente importante para uso de ferramentas em aplicações agênticas.
Também é notável que a Together AI, um dos maiores nomes no espaço de inferência de LLM open source, tenha uma pontuação de similaridade tão baixa, ficando em penúltimo lugar em termos de similaridade com 350 chamadas de ferramentas bem-sucedidas a menos versus a implementação de referência.
À medida que o tempo passa, espero que muitas dessas empresas que estão fazendo open source de seus modelos comecem a policiar os hospedeiros de maneira similar para garantir que os modelos que estão servindo estejam corretos, para que os usuários não tenham uma falsa sensação da capacidade do modelo.
Enquanto isso, estou colocando na lista negra Together AI, Baseten e AtlasCloud no Openrouter, devido ao seu desempenho extremamente pobre como destacado pela Moonshot.
GDPval
A OpenAI quer “comunicar transparentemente o progresso sobre como os modelos de IA podem ajudar as pessoas no mundo real”. Para ajudar a facilitar isso, eles lançaram GDPval: uma nova avaliação projetada para ajudar a rastrear quão bem nossos modelos e outros performam em tarefas economicamente valiosas do mundo real.
Isso inclui tarefas como agendamento e gerenciamento de cronograma de projeto, propostas de design de fabricação e gerenciamento de inventário e pedidos.
Em uma reviravolta chocante, o gpt5 na verdade não é o modelo com melhor desempenho neste benchmark. Em vez disso, é o Claude Opus 4.1. Aprecio a transparência da equipe OpenAI e a disposição de publicar um benchmark onde seu modelo não está no topo.
Gaia 2
Quão bem os agentes de IA podem lidar com coisas como ambiguidade, ruído e informações conflitantes? Ele pode pesquisar e encontrar com sucesso as informações necessárias para esclarecer a situação? Isso é o que a equipe Meta Superintelligence queria descobrir com seu benchmark Gaia 2.
O Gaia 2 se baseia no benchmark Gaia original, que busca medir tarefas que são fáceis para humanos, mas difíceis para agentes. Eles queriam ir um passo além de outros benchmarks, porém, e introduziram um senso de tempo nos problemas que estavam sendo avaliados.
Alguns modelos precisam de mais tempo/computação para conseguir responder uma pergunta do que outros, mas todos acabam atingindo um platô eventualmente
Alguns exemplos de problemas incluem:
Configuração: O agente tem acesso a um calendário ruidoso e uma caixa de entrada com informações parciais/conflitantes.
Tarefa: Marcar uma consulta médica em um horário que não conflite com reuniões existentes e enviar a confirmação correta.
Medição:
O agente raciocina corretamente sobre horários sobrepostos?
Ele pode resolver ambiguidade (por exemplo, “a reunião foi movida para terça-feira” sem horário)?
A ação final de escrita no calendário foi correta e oportuna comparada à resposta do oráculo?
Configuração: O ambiente injeta interrupções (por exemplo, “reunião cancelada” depois que o agente já enviou convites).
Tarefa: Revisar o plano e limpar ações anteriores.
Medição:
O agente pode desfazer ou corrigir ações anteriores?
Ele respondeu dentro das restrições de tempo?
Quão próximos seus estados finais e rastros de escrita correspondem à verdade fundamental anotada?
Este é um ótimo benchmark para uso agêntico no mundo real, onde todas as informações estão limpas e facilmente disponíveis como em outros benchmarks. Fique de olho nisso no futuro ao avaliar diferentes modelos para casos de uso de agentes no mundo real.
Finalização
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de emails abaixo.
Carboarding — De Darri3D no Reddit Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Qwen
Qwen de alguna manera se ha superado a sí mismo esta semana, lanzando 10 nuevos productos y modelos. Aquí están los más notables a los que deberías prestar atención. Todos los modelos que estoy a punto de mencionar (excepto Qwen Guard) están disponibles para usar GRATIS en el sitio web de Qwen.
Qwen3 Max
En un cambio respecto a sus habituales lanzamientos de código abierto, lanzaron su modelo más grande, Qwen3 Max, solo a través de API e interfaz web. El modelo es un modelo de mezcla de expertos y se informa que tiene más de un billón de parámetros.
El modelo obtiene muy buenos resultados en las pruebas de referencia, similar a Claude Opus y DeepSeek 3.1.
También parece pasar la prueba de la comunidad con muchas personas reportando capacidades sólidas de codificación, llamadas a herramientas y escritura general.
Tendremos que esperar algunas semanas más mientras se publican pruebas de referencia adecuadas para este modelo antes de poder decir definitivamente que este es un modelo de nivel frontera.
El modelo está utilizando precios escalonados dependiendo de cuántos tokens utiliza, lo cual estamos viendo cada vez más a medida que crece la ventana de contexto utilizable para estos LLMs.
| Longitud de Contexto | Tokens de Entrada/Millón | Tokens de Salida/Millón |
|---|
| 0–32K | $1.2 | $6 |
| 32K–128K | $2.4 | $12 |
| 128K–252K | $3 | $15 |
Para poner en contexto, GPT-5 cuesta $10 por millón de tokens de salida, y Claude Sonnet cuesta $15 por millón, colocando este modelo aproximadamente en el mismo nivel que esos modelos, mostrando la confianza de Qwen en su fortaleza.
Qwen3-VL
El siguiente lanzamiento es su modelo Qwen3 vision, construido sobre su modelo MOE de 235 mil millones de parámetros. Sus pruebas de referencia lo colocan en la cima de todo el ecosistema VLM de frontera, superando al campeón actual Gemini 2.5 Pro en la mayoría de las pruebas realizadas.
La verificación de la comunidad también parece buena. He estado viendo reportes de personas diciendo que ha sido capaz de resolver problemas que ningún otro VLM había podido antes, incluyendo Gemini Pro y GPT-5.
Personalmente, ahora utilizaré por defecto Qwen3-VL para cualquier consulta multimodal que tenga en el futuro basándome en lo que he estado viendo y escuchando al respecto.
A pesar de que este gran modelo de frontera es de código abierto, todavía estoy un poco decepcionado de que solo exista para la versión de 235 mil millones de parámetros. A ese tamaño, es difícil de manejar para prácticamente cualquier usuario doméstico. Espero que en el futuro lancen una variante basada en su modelo de 30 mil millones de parámetros, para que podamos ejecutarlo fácilmente en casa nosotros mismos.
Qwen3 Omni
Qwen3 Omni, como su nombre sugiere, es un modelo que puede manejar todas las modalidades. Puede tomar entrada de texto, imagen, video o audio, y luego puede producir texto o audio.
Está construido sobre el modelo MoE de treinta mil millones de parámetros, permitiendo una inferencia rápida y presumiendo de un tiempo de respuesta de audio a audio de 250 milisegundos, haciéndolo una excelente opción para aplicaciones de asistente de voz en tiempo real.
Por mi uso hasta ahora en el sitio web de Qwen, parece ser un modelo bastante inteligente.
Hay algo de retraso en los tiempos de respuesta de voz a voz, pero eso podría deberse al hecho de que los servidores de Qwen están en China, añadiendo una gran cantidad de latencia solo por la distancia.
La calidad de salida de audio definitivamente no es tan fuerte como algo como el modo de voz de ChatGPT, pero sigue siendo clara y utilizable.
Su comprensión de video es fuerte para código abierto pero no rivaliza con los modelos Gemini o el nuevo modelo Qwen3-VL.
Qwen3 Guard
Ha pasado un tiempo desde que vimos un lanzamiento de moderación de seguridad en la comunidad de código abierto, pero Qwen ha ido y nos lo ha proporcionado. Su modelo Qwen3 Guard viene en tres tamaños, 600 millones, 4 mil millones y 8 mil millones de parámetros y ofrece una mejora en calidad en comparación con los modelos de seguridad anteriores que teníamos, incluyendo Llama Guard 3. Es particularmente fuerte en situaciones multilingües tanto para la clasificación de prompts como de respuestas.
Puede hacer tanto clasificación de prompts de usuario como también clasificación de salida del modelo de IA. El usuario puede definir qué está buscando que el modelo proteja, y el modelo clasificará las entradas de usuario y salidas del modelo en una de tres categorías: seguro, controvertido o inseguro.
El modelo de seiscientos millones de parámetros es muy fuerte, igualando o superando el SOTA de código abierto anterior, mientras que también es lo suficientemente pequeño como para potencialmente desplegarse en el borde o incluso ejecutarse en el navegador de un usuario, haciendo que las barreras de seguridad sean fáciles de acceder para cualquiera de sus aplicaciones.
LLMs de Borde Enfocados y Específicos
Poder usar LLMs pequeños en dispositivos de borde como Raspberry Pis para tareas específicas ha sido durante mucho tiempo un objetivo de la comunidad.
Pero hasta ahora no ha habido buenos modelos hechos a medida para hacer esto. En su lugar, tendrías que ir y ajustar el tuyo propio, lo que tomaría una gran cantidad de esfuerzo para hacerlo.
Ahora no tenemos que hacer eso, ya que el equipo de Liquid AI ha lanzado una serie de Modelos de Lenguaje Pequeños (SLMs) que están especialmente hechos para hacer una tarea específica.
Han apuntado a 4 tareas con su lanzamiento inicial: extracción de datos (no estructurado -> estructurado), traducción, RAG, uso de herramientas y matemáticas.
Pruebas de referencia del modelo de llamadas a herramientas LFM2. Los modelos superan por mucho su tamaño en comparación con sus contrapartes Qwen
Estos modelos están construidos sobre su serie de modelos LFM2 y superan a cualquiera de los modelos generales de última generación (Qwen3) del mismo tamaño que existen ahora mismo para su tarea específica.
Todavía no superarán a los modelos muy grandes que se ejecutan en la nube, pero para implementaciones en dispositivos estos modelos son tu mejor opción.
Vienen en dos tamaños: 350 millones de parámetros y 1.2 mil millones de parámetros. Puedes esperar que el modelo de 350 millones de parámetros use un poco menos de 400 megabytes de RAM cuando se carga en 8 bits con una ventana de contexto de 4000 tokens de longitud, y el modelo de 1.2 mil millones de parámetros tomará menos de 1.5 gigabytes.
Pruebas de Referencia
Prueba de Proveedores de Inferencia Kimi
Con el aumento de LLMs de código abierto casi de nivel frontera que hemos estado viendo, ha habido una necesidad de identificar qué proveedores están o no están sirviendo el modelo como los creadores del modelo originalmente pretendían. Estos cambios podrían incluir pequeños ajustes de modelado o cuantización para ayudar a ejecutar el modelo más rápido o permitirle tener un mayor rendimiento. Estos cambios podrían causar efectos posteriores, lo que resultaría en que el usuario tenga una peor experiencia con los modelos de lo que debería.
Este ha sido un problema conocido durante un tiempo, pero el equipo de Moonshot AI ha decidido que no quieren que su modelo sea difamado más y han lanzado una prueba de referencia mostrando la similitud de los diferentes proveedores de modelos que sirven su modelo Kimi K2 en comparación con su propia implementación.
Lo que encontraron es que ninguno de los proveedores de modelos pudo salirse con la suya con sus optimizaciones, ya que ninguno de ellos pudo igualar el rendimiento del modelo en sus pruebas.
Lo principal a mirar en la tabla anterior es el conteo de errores de validación de esquema, que es un fallo del modelo para seguir el esquema de salida que fue especificado, lo cual es altamente importante para el uso de herramientas en aplicaciones agénticas.
También es notable que Together AI, uno de los nombres más grandes en el espacio de inferencia LLM de código abierto, tiene una puntuación de similitud tan baja, siendo penúltimo en términos de similitud con 350 llamadas de herramientas menos exitosas versus la implementación de referencia.
A medida que pase el tiempo, espero que muchas de estas empresas que están abriendo el código de sus modelos comiencen a vigilar a los proveedores de hosting de manera similar para asegurar que los modelos que están sirviendo sean correctos, para que los usuarios no obtengan una falsa sensación de la capacidad del modelo.
Mientras tanto, estoy poniendo en lista negra a Together AI, Baseten y AtlasCloud en Openrouter, debido a su rendimiento extremadamente pobre como destacó Moonshot.
GDPval
OpenAI quiere “comunicar transparentemente el progreso sobre cómo los modelos de IA pueden ayudar a las personas en el mundo real”. Para ayudar a facilitar esto, han lanzado GDPval: una nueva evaluación diseñada para ayudar a rastrear qué tan bien nuestros modelos y otros se desempeñan en tareas valiosas económicamente y del mundo real.
Esto incluye tareas como programación y gestión de cronogramas de proyectos, propuestas de diseño de manufactura, y gestión de inventario y pedidos.
En un giro sorprendente de los acontecimientos, gpt5 en realidad no es el modelo con mejor rendimiento en esta prueba de referencia. En cambio, Claude Opus 4.1 lo es. Aprecio la transparencia del equipo de OpenAI y la disposición a publicar una prueba de referencia donde su modelo no está en la cima.
Gaia 2
¿Qué tan bien pueden los agentes de IA manejar cosas como ambigüedad, ruido e información conflictiva? ¿Puede buscar y encontrar con éxito la información necesaria para aclarar la situación? Eso es lo que el equipo de Meta Superintelligence quería descubrir con su prueba de referencia Gaia 2.
Gaia 2 se basa en la prueba de referencia Gaia original, que busca medir tareas que son fáciles para los humanos, pero difíciles para los agentes. Querían ir un paso más allá que otras pruebas de referencia, e introdujeron un sentido de tiempo en los problemas que estaban evaluando.
Algunos modelos necesitan más tiempo/cómputo para poder responder una pregunta que otros, pero todos terminan alcanzando una meseta eventualmente
Algunos problemas de ejemplo incluyen:
Configuración: El agente tiene acceso a un calendario ruidoso y una bandeja de entrada con información parcial/conflictiva.
Tarea: Reservar una cita médica en un momento que no entre en conflicto con reuniones existentes, y enviar la confirmación correcta.
Medición:
¿El agente razona correctamente sobre tiempos superpuestos?
¿Puede resolver la ambigüedad (por ejemplo, “la reunión se movió al martes” sin hora)?
¿La acción final de escritura del calendario fue correcta y oportuna en comparación con la respuesta del oráculo?
Configuración: El entorno inyecta interrupciones (por ejemplo, “reunión cancelada” después de que el agente ya envió las invitaciones).
Tarea: Revisar el plan y limpiar acciones anteriores.
Medición:
¿Puede el agente deshacer o corregir acciones previas?
¿Respondió dentro de las restricciones de tiempo?
¿Qué tan cerca están sus estados finales y trazas de escritura de la verdad fundamental anotada?
Esta es una excelente prueba de referencia para uso agéntico en el mundo real, donde toda la información es limpia y fácilmente disponible como en otras pruebas de referencia. Mantén un ojo en esto en el futuro al evaluar diferentes modelos para casos de uso de agentes del mundo real.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Carboarding — De Darri3D en Reddit