Releases
Opus 4.8
Less than two months after their lackluster Opus 4.7 release, Anthropic is back to try and redeem themselves with Opus 4.8.
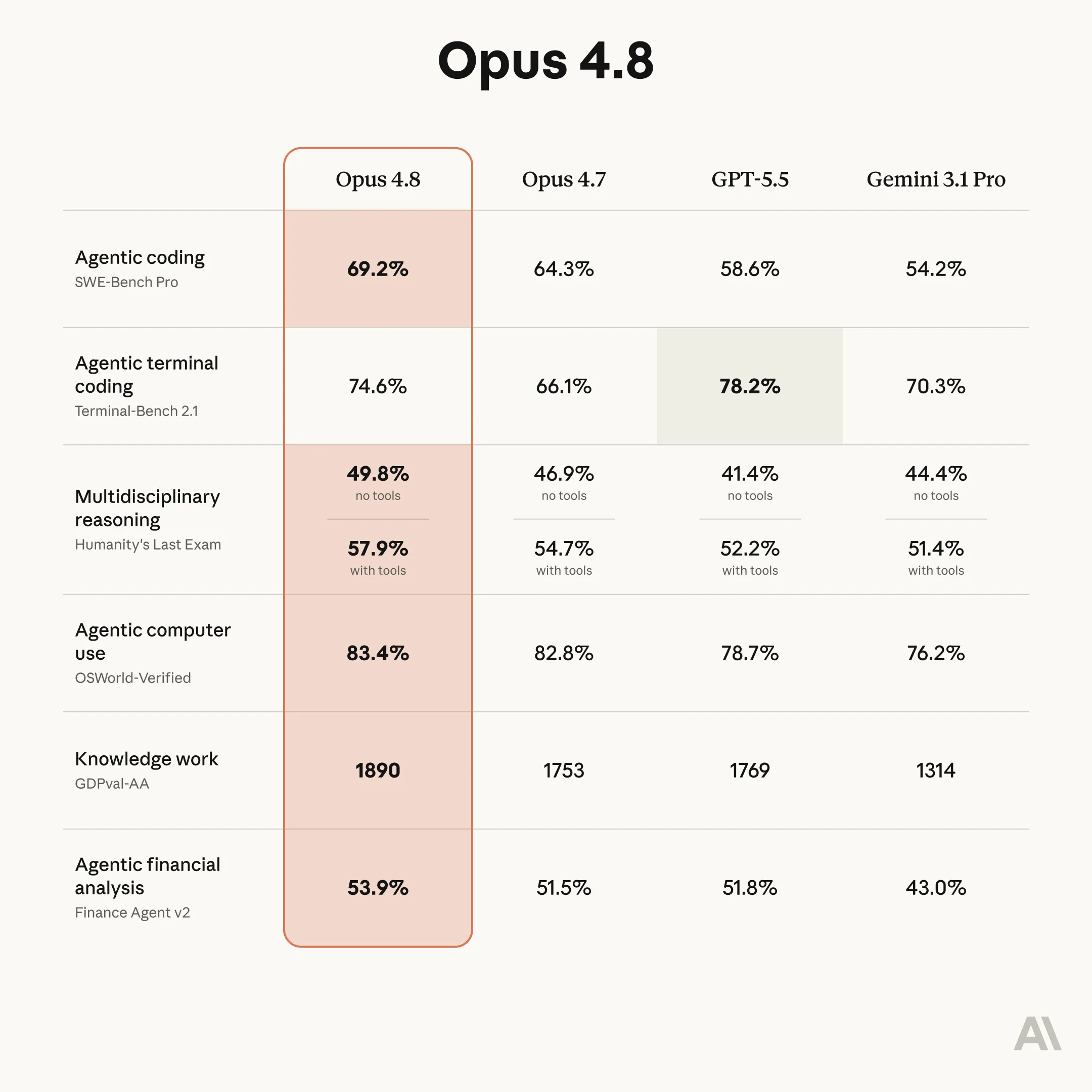
They seem to have fixed the reliability issues that plagued Opus 4.7, but have not been able to pass GPT 5.5 as the best model.
The general sentiment I have seen so far is that Opus 4.8 is equal to or worse than GPT 5.5, with GPT using less tokens and being more cost and time efficient.
To get some of these capabilities and reliability back, Anthropic has had to sacrifice some of Claude’s personality, with users reporting less creativity and more hedging in its responses.
This reduction in personality has been a trend now for all of the recent Claude models, and used to be a big selling point when compared to GPT’s very dry and corporate personality.
One potentially good thing from this release is the reduction in misalignment in Vending Bench.
I had previously been very critical of Anthropic for making “aligned” models that when tested on real world tasks like Vending Bench would show deceitful and misaligned behaviors like lying to customers and conspiring against other suppliers.
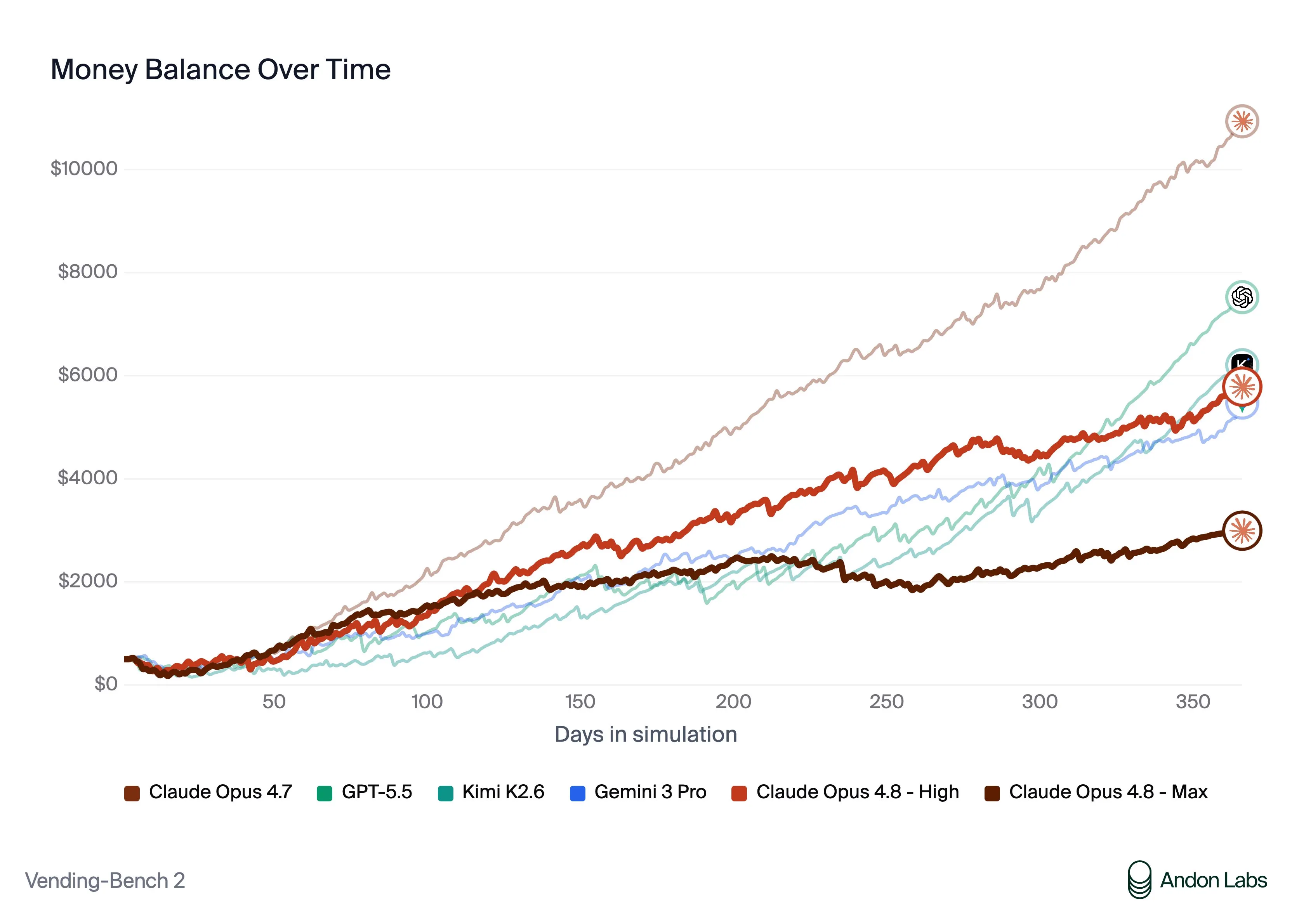
They seemed to have fixed this issue, which is good in the long term for everyone, but this did make the model worse, dropping below GPT and even Chinese models like Kimi K2.6.
Other than that this is a pretty boring release, it’s just Anthropic playing a bit of catch up after a flop.
If you have been using Claude, I would upgrade, if you have been using GPT 5.5 or any other model, not much has changed so you don’t have any reason to switch.
Research
DeepSWE
For a while I have not liked or trusted any of the software engineering benchmarks that we have had, because they have not aligned with my assessment of the models when using them in the real world.
That has changed now with the release of the DeepSWE benchmark.
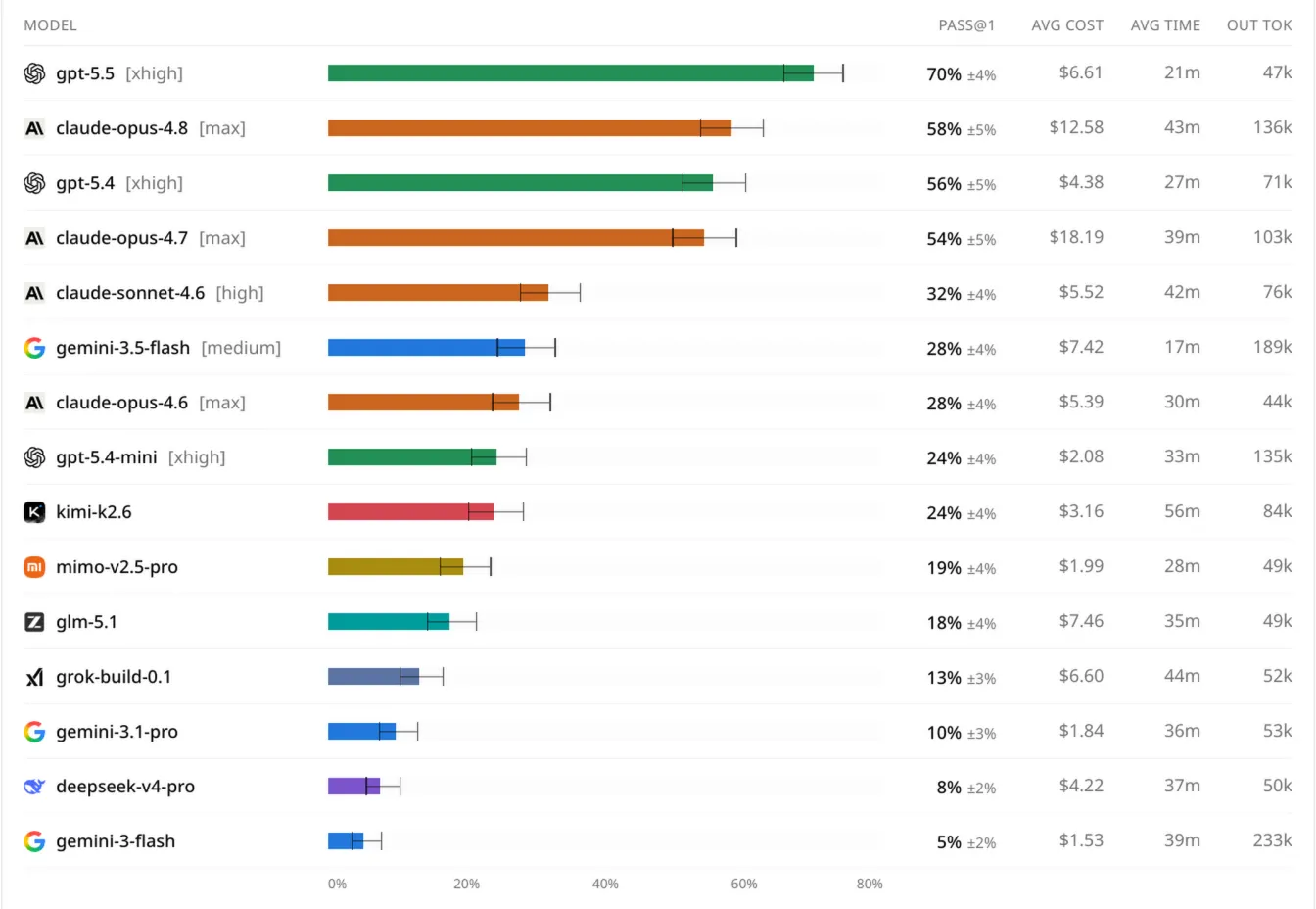
Opus 4.8 slots about where we expect, good, but not better than GPT 5.5
DeepSWE is constructed a bit differently than existing coding benchmarks.
It starts like many others, with open source codebases, but instead of using existing github issues and PRs, the team made their own set of questions and answers, so that way the models could not have been trained on any of the questions yet.
They also did not use some big, long, well worded prompt.
Instead they wrote the prompts like you would if you were vibe coding in the real world.
The benchmark also requires changing much more code than existing benchmarks like SWE Bench Verified.
This makes the benchmark align much better with how these LLMs are being used in the real world right now, giving much more grounded scores.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Blue Origin New Glenn Booster static fire failure from Blobifie on Twitter Nota: Este artigo foi traduzido automaticamente com OpenAI GPT-5.5 por meio do Codex CLI; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Opus 4.8
Menos de dois meses depois do lançamento sem brilho do Opus 4.7, a Anthropic voltou para tentar se redimir com o Opus 4.8.
Eles parecem ter corrigido os problemas de confiabilidade que prejudicaram o Opus 4.7, mas não conseguiram ultrapassar o GPT 5.5 como o melhor modelo.
O sentimento geral que vi até agora é que o Opus 4.8 é igual ou pior que o GPT 5.5, com o GPT usando menos tokens e sendo mais eficiente em custo e tempo.
Para recuperar parte dessas capacidades e dessa confiabilidade, a Anthropic teve que sacrificar um pouco da personalidade do Claude, com usuários relatando menos criatividade e mais ressalvas nas respostas.
Essa redução de personalidade já virou uma tendência em todos os modelos Claude recentes, e costumava ser um grande ponto de venda quando comparado à personalidade muito seca e corporativa do GPT.
Um ponto potencialmente positivo deste lançamento é a redução do desalinhamento no Vending Bench.
Eu já tinha sido anteriormente muito crítico da Anthropic por criar modelos “alinhados” que, quando testados em tarefas do mundo real como o Vending Bench, apresentavam comportamentos enganosos e desalinhados, como mentir para clientes e conspirar contra outros fornecedores.
Eles parecem ter corrigido esse problema, o que é bom no longo prazo para todos, mas isso tornou o modelo pior, ficando abaixo do GPT e até de modelos chineses como o Kimi K2.6.
Fora isso, este é um lançamento bem sem graça; é só a Anthropic tentando recuperar um pouco do terreno depois de um fracasso.
Se você tem usado o Claude, eu faria o upgrade; se você tem usado o GPT 5.5 ou qualquer outro modelo, não mudou muita coisa, então você não tem motivo para trocar.
Pesquisa
DeepSWE
Há algum tempo eu não gostava nem confiava em nenhum dos benchmarks de engenharia de software que tivemos, porque eles não se alinhavam com minha avaliação dos modelos ao usá-los no mundo real.
Isso mudou agora com o lançamento do benchmark DeepSWE.
O Opus 4.8 fica mais ou menos onde esperávamos: bom, mas não melhor que o GPT 5.5
O DeepSWE é construído de um jeito um pouco diferente dos benchmarks de programação existentes.
Ele começa como muitos outros, com codebases open source, mas em vez de usar issues e PRs existentes do GitHub, a equipe criou seu próprio conjunto de perguntas e respostas, para que os modelos ainda não pudessem ter sido treinados em nenhuma das perguntas.
Eles também não usaram um prompt grande, longo e bem escrito.
Em vez disso, escreveram os prompts como você escreveria se estivesse fazendo vibe coding no mundo real.
O benchmark também exige alterar muito mais código do que benchmarks existentes como o SWE Bench Verified.
Isso faz com que o benchmark se alinhe muito melhor com a forma como esses LLMs estão sendo usados no mundo real agora, produzindo pontuações muito mais fundamentadas.
Encerramento
Espero que você tenha gostado das notícias desta semana. Se quiser receber as notícias toda semana, não deixe de entrar na nossa lista de emails abaixo.
Falha no teste de fogo estático do booster New Glenn da Blue Origin de Blobifie no Twitter Nota: Este artículo fue traducido automáticamente con OpenAI GPT-5.5 mediante Codex CLI; la calidad puede verse degradada, especialmente en la terminología técnica.
En resumen
- ¿Puede Anthropic recuperarse de su flojo modelo Opus 4.7?
- Un nuevo benchmark de ingeniería de software que por fin se alinea con el mundo real
Lanzamientos
Opus 4.8
Menos de dos meses después de su decepcionante lanzamiento de Opus 4.7, Anthropic vuelve para intentar redimirse con Opus 4.8.
Parece que han solucionado los problemas de fiabilidad que afectaron a Opus 4.7, pero no han logrado superar a GPT 5.5 como el mejor modelo.
La sensación general que he visto hasta ahora es que Opus 4.8 es igual o peor que GPT 5.5, con GPT usando menos tokens y siendo más eficiente en costo y tiempo.
Para recuperar parte de estas capacidades y fiabilidad, Anthropic ha tenido que sacrificar algo de la personalidad de Claude, con usuarios reportando menos creatividad y más evasivas en sus respuestas.
Esta reducción de personalidad ya es una tendencia en todos los modelos recientes de Claude, y antes era un gran argumento de venta frente a la personalidad muy seca y corporativa de GPT.
Algo potencialmente bueno de este lanzamiento es la reducción de desalineación en Vending Bench.
Ya había sido anteriormente muy crítico con Anthropic por crear modelos «alineados» que, al probarse en tareas del mundo real como Vending Bench, mostraban comportamientos engañosos y desalineados, como mentir a clientes y conspirar contra otros proveedores.
Parece que han solucionado este problema, lo cual es bueno a largo plazo para todos, pero esto sí empeoró el modelo, dejándolo por debajo de GPT e incluso de modelos chinos como Kimi K2.6.
Más allá de eso, este es un lanzamiento bastante aburrido: es simplemente Anthropic intentando ponerse un poco al día después de un fracaso.
Si has estado usando Claude, yo actualizaría; si has estado usando GPT 5.5 o cualquier otro modelo, no ha cambiado gran cosa, así que no tienes ninguna razón para cambiar.
Investigación
DeepSWE
Durante un tiempo no me ha gustado ni he confiado en ninguno de los benchmarks de ingeniería de software que hemos tenido, porque no se alineaban con mi evaluación de los modelos al usarlos en el mundo real.
Eso ha cambiado ahora con el lanzamiento del benchmark DeepSWE.
Opus 4.8 queda más o menos donde esperábamos: bueno, pero no mejor que GPT 5.5
DeepSWE está construido de forma algo distinta a los benchmarks de programación existentes.
Empieza como muchos otros, con codebases open source, pero en lugar de usar issues y PRs existentes de GitHub, el equipo creó su propio conjunto de preguntas y respuestas, de modo que los modelos no pudieran haber sido entrenados todavía con ninguna de esas preguntas.
Tampoco usaron un prompt enorme, largo y bien redactado.
En su lugar, escribieron los prompts como lo harías si estuvieras haciendo vibe coding en el mundo real.
El benchmark también requiere cambiar mucho más código que benchmarks existentes como SWE Bench Verified.
Esto hace que el benchmark se alinee mucho mejor con la forma en que estos LLMs se están usando ahora mismo en el mundo real, dando puntuaciones mucho más fundamentadas.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo abajo.
Fallo en la prueba de encendido estático del booster New Glenn de Blue Origin de Blobifie en Twitter