Releases
Opus 4.7
Only a week after announcing the existence of Mythos Anthropic has released Opus 4.7.
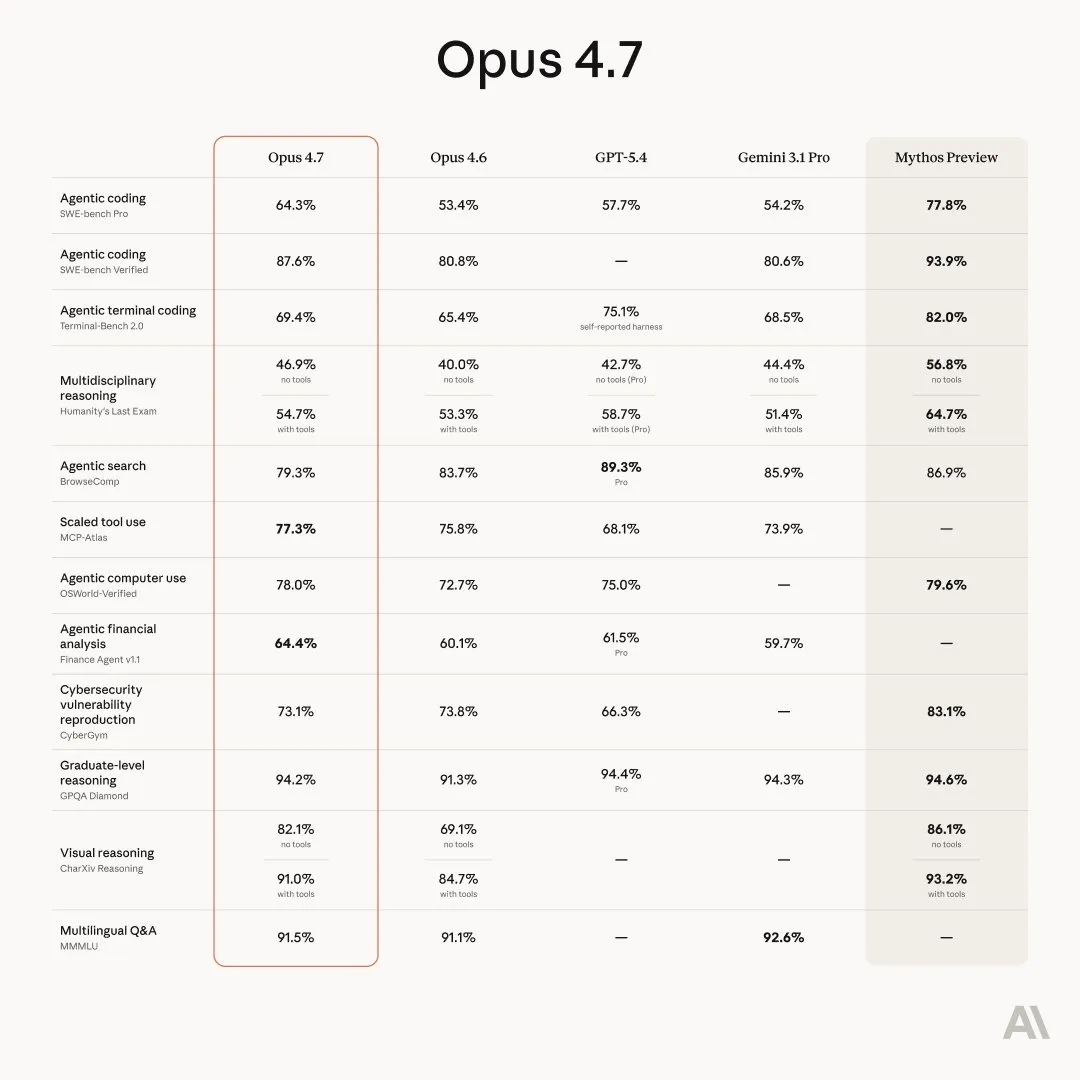
New benchmarking chart meta: show your new public model beating all the other labs’ models, but still losing to your internal “actually good” model
The consensus for Opus 4.7 is not as clear as previous releases.
Usually a new model release is clearly better than its predecessors; this is the case for pretty much every lab (except Mistral).
But for Opus 4.7 I have been seeing mixed opinions so far.
It seems to lack the level of refinement of previous Claude models.
Its personality and soul are lacking, and it capabilities within Claude Code, while still good, are a bit shaky, with multiple people (including myself) running into a higher than normal number of tool call failures.
For coding the model does seem smarter, but also more unreliable, from Chubby on Twitter:
Opus 4.7 feels like a disgruntled employee whose results you can’t judge and have to check afterward. The trust you had with 4.6 is gone. It’s like hiring a new employee who had excellent grades in their application but is totally sloppy and disgruntled in practice and doesn’t follow instructions.
This seems to be due to the new adaptive thinking mode that the model uses.
This allows the model to think more or less for a given query based on how hard it thinks it is.
The GPT series of models has had this for a while and it has worked very well, but Anthropic seemed to have missed the mark with their implementation of it.
Opus 4.7 only considers coding or STEM related tasks to be hard enough for more thinking, causing to reason less and give worse answers for almost every other domain.
For OpenAI, their adaptive thinking was for a better user experience, since users prefer faster answers. Anthropic on the other hand, being far more compute constrained than OpenAI is right now, are using adaptive thinking to save compute. From a HackerNews poster:
[Adaptive thinking is] a solved problem for the companies. It solves their problems. Not yours ;)
To add insult to injury, Anthropic also updated the tokenizer for the model, which makes it use more tokens than normal, causing it to be 20-50% more expensive than Opus 4.6 for the same number of characters.
For most people, Opus 4.7 is a sidegrade at most, trading off raw intelligence and capability for reliability. For most other use cases it seems to be a bit of a downgrade, so I would not recommend using it at this time unless it performs noticeably better for your own use cases.
Qwen 3.6 35B
Less than 2 months after the Qwen 3.5 releases, we now have our first open source Qwen 3.6 model, an update to the 35B-A3B mixture of experts model.
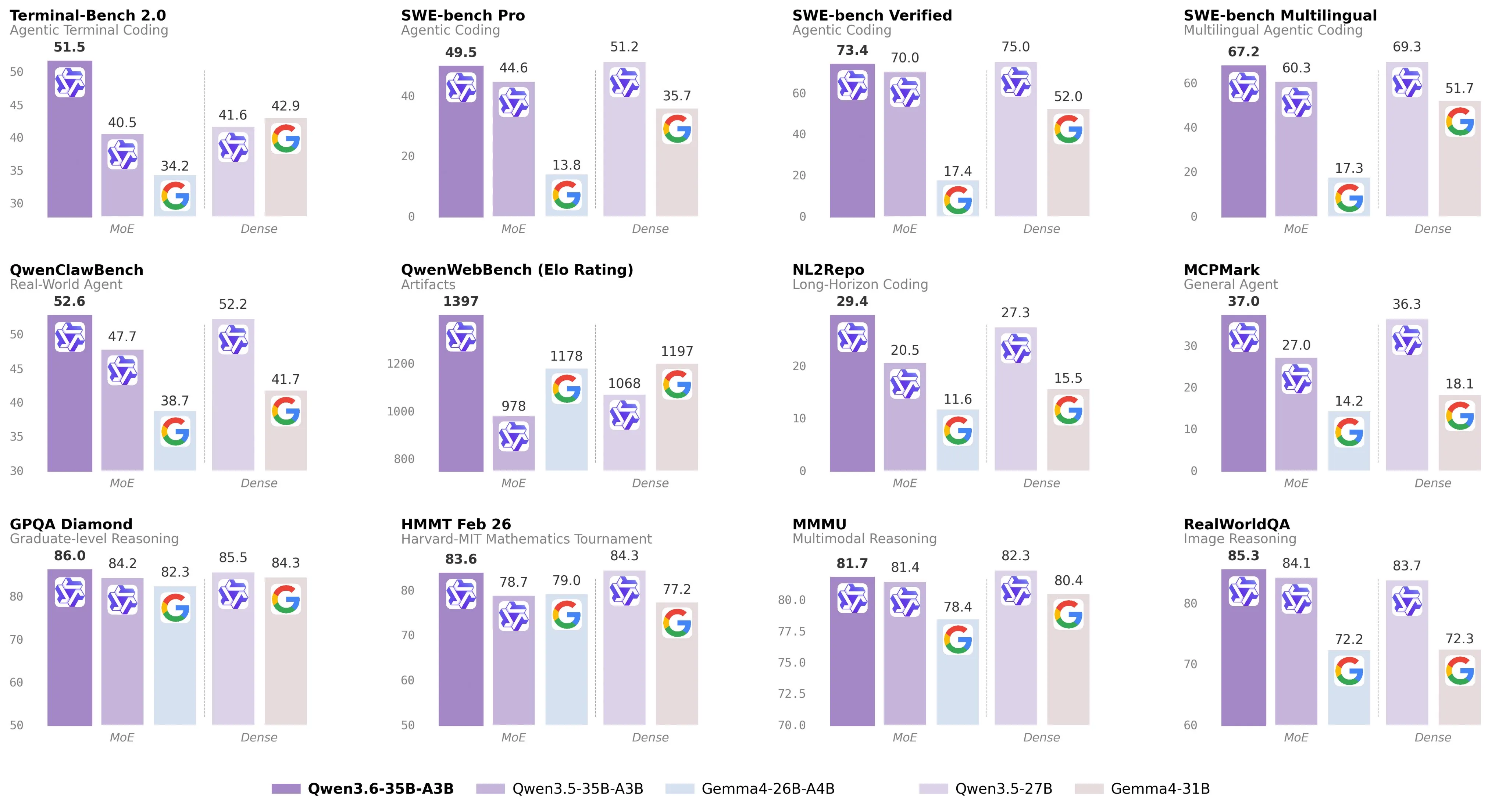
The Qwen 3.5 and Gemma 4 dense models (the 27B and 31B models in the chart above) were considered to be the first models that were good enough to be used in coding harnesses and agent interfaces like OpenClaw.
This Qwen 3.6 model is able to handily beat both of its dense counterparts, while being far more efficient, making it runnable at decent speeds (>20 tokens per second) on pretty much any hardware with at least 24GB of memory.
In terms of its benchmark scores, it’s around the Sonnet 4.5 level, which is insane since it is at least one order of magnitude smaller than Sonnet, which was released only 5 months ago.
If this trend continues, that means that we will have a Opus 4.6/GPT 5.4 level model that we can run at home fairly easily in 6 months.
I have been personally using this model with Hermes Agent (a OpenClaw alternative that is a bit friendlier for open source models) and it has worked fairly well with no major issues.
I have seen similar sentiment from those on LocalLLaMA who have been using it as a personal agent and also as a fairly competent coding assistant.
As I said for the Qwen3.5 and Gemma 4 models, now is the best time to start using local LLMs, because they are starting to get good enough to replace OpenAI and Anthropic for easy and medium difficulty tasks.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Midjourney 8.1 and Seedance 2.0 made by Jerrod Lew on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Opus 4.7
Apenas uma semana após anunciar a existência do Mythos, a Anthropic lançou o Opus 4.7.
Nova meta nos gráficos de benchmark: mostre seu novo modelo público superando todos os outros laboratórios, mas ainda perdendo para o seu modelo interno “realmente bom”
O consenso sobre o Opus 4.7 não é tão claro quanto nos lançamentos anteriores.
Normalmente, um novo lançamento de modelo é claramente melhor do que seus predecessores; esse é o caso de praticamente todos os laboratórios (exceto a Mistral).
Mas para o Opus 4.7, tenho visto opiniões divergentes até agora.
Parece faltar o nível de refinamento dos modelos Claude anteriores.
Sua personalidade e “alma” estão ausentes, e suas capacidades dentro do Claude Code, embora ainda boas, são um pouco instáveis, com várias pessoas (inclusive eu) encontrando um número acima do normal de falhas nas chamadas de ferramentas.
Para programação, o modelo parece mais inteligente, mas também mais instável, segundo Chubby no Twitter:
O Opus 4.7 parece um funcionário insatisfeito cujos resultados você não consegue avaliar e precisa verificar depois. A confiança que você tinha com o 4.6 sumiu. É como contratar um novo funcionário que tinha notas excelentes na candidatura, mas é completamente descuidado e mal-humorado na prática e não segue instruções.
Isso parece ser causado pelo novo modo de raciocínio adaptativo que o modelo utiliza.
Esse modo permite que o modelo pense mais ou menos para uma determinada consulta com base em quão difícil ele julga que ela é.
A série de modelos GPT tem isso há algum tempo e funcionou muito bem, mas a Anthropic parece ter errado na implementação.
O Opus 4.7 considera apenas tarefas de programação ou STEM como suficientemente difíceis para um raciocínio mais aprofundado, fazendo com que raciocine menos e dê respostas piores em praticamente todos os outros domínios.
Para a OpenAI, o raciocínio adaptativo visava uma melhor experiência do usuário, já que os usuários preferem respostas mais rápidas. A Anthropic, por outro lado, sendo muito mais limitada em termos de capacidade computacional do que a OpenAI atualmente, está usando o raciocínio adaptativo para economizar processamento. De acordo com um usuário do HackerNews:
[O raciocínio adaptativo é] um problema resolvido para as empresas. Ele resolve os problemas delas. Não os seus ;)
Para piorar, a Anthropic também atualizou o tokenizador do modelo, o que faz com que ele use mais tokens do que o normal, tornando-o 20-50% mais caro do que o Opus 4.6 para o mesmo número de caracteres.
Para a maioria das pessoas, o Opus 4.7 é, na melhor das hipóteses, uma atualização lateral, trocando inteligência e capacidade brutas por confiabilidade. Para a maioria dos outros casos de uso, parece ser uma ligeira regressão, portanto não recomendo seu uso no momento, a menos que ele apresente um desempenho notavelmente melhor para os seus próprios casos de uso.
Qwen 3.6 35B
Menos de 2 meses após os lançamentos do Qwen 3.5, temos agora nosso primeiro modelo open source Qwen 3.6, uma atualização do modelo mixture of experts 35B-A3B.
Os modelos densos Qwen 3.5 e Gemma 4 (os modelos de 27B e 31B no gráfico acima) eram considerados os primeiros modelos bons o suficiente para serem usados em ambientes de programação e interfaces de agentes como o OpenClaw.
Este modelo Qwen 3.6 consegue superar com folga ambos os seus equivalentes densos, sendo muito mais eficiente, o que permite rodá-lo em velocidades decentes (>20 tokens por segundo) em praticamente qualquer hardware com pelo menos 24 GB de memória.
Em termos de pontuações nos benchmarks, está no nível do Sonnet 4.5, o que é impressionante, pois é pelo menos uma ordem de grandeza menor que o Sonnet, lançado há apenas 5 meses.
Se essa tendência continuar, significa que teremos um modelo no nível do Opus 4.6/GPT 5.4 que poderemos rodar em casa com facilidade em 6 meses.
Tenho usado pessoalmente este modelo com o Hermes Agent (uma alternativa ao OpenClaw um pouco mais amigável para modelos open source) e funcionou muito bem, sem problemas graves.
Tenho visto sentimentos semelhantes entre os usuários do LocalLLaMA que o têm usado como agente pessoal e também como um assistente de programação bastante competente.
Como já disse para os modelos Qwen 3.5 e Gemma 4, agora é o melhor momento para começar a usar LLMs locais, porque eles estão começando a ser bons o suficiente para substituir a OpenAI e a Anthropic em tarefas de dificuldade fácil e média.
Conclusão
Espero que você tenha gostado das novidades desta semana. Se quiser receber as notícias toda semana, não deixe de se inscrever na nossa lista de e-mails abaixo.
Midjourney 8.1 e Seedance 2.0 feito por Jerrod Lew no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Opus 4.7
Solo una semana después de anunciar la existencia de Mythos, Anthropic ha lanzado Opus 4.7.
Nueva meta en los gráficos de benchmarks: mostrar tu nuevo modelo público superando a todos los demás laboratorios, pero aún por debajo de tu modelo interno “realmente bueno”
El consenso sobre Opus 4.7 no es tan claro como en lanzamientos anteriores.
Normalmente, el lanzamiento de un nuevo modelo es claramente mejor que sus predecesores; esto aplica para prácticamente todos los laboratorios (excepto Mistral).
Pero con Opus 4.7 he visto opiniones encontradas hasta ahora.
Parece carecer del nivel de refinamiento de los modelos Claude anteriores.
Su personalidad y esencia dejan que desear, y sus capacidades dentro de Claude Code, aunque siguen siendo buenas, son un poco inestables, con varias personas (incluido yo mismo) experimentando un número mayor de lo normal de fallos en las llamadas a herramientas.
Para programación, el modelo parece más inteligente, pero también menos fiable. Según Chubby en Twitter:
Opus 4.7 se siente como un empleado descontento cuyos resultados no puedes juzgar y tienes que revisar después. La confianza que tenías con 4.6 ha desaparecido. Es como contratar a un nuevo empleado que tenía excelentes calificaciones en su solicitud, pero que en la práctica es totalmente descuidado y descontento, y no sigue las instrucciones.
Esto parece deberse al nuevo modo de pensamiento adaptativo que utiliza el modelo.
Esto permite al modelo pensar más o menos ante una consulta determinada en función de lo difícil que considera que es.
La serie de modelos GPT ha tenido esto durante un tiempo y ha funcionado muy bien, pero Anthropic parece haber fallado con su implementación.
Opus 4.7 solo considera las tareas de programación o STEM como suficientemente difíciles para pensar más, lo que lleva a razonar menos y dar peores respuestas en casi cualquier otro dominio.
Para OpenAI, su pensamiento adaptativo buscaba una mejor experiencia de usuario, ya que los usuarios prefieren respuestas más rápidas. Anthropic, por otro lado, al estar mucho más limitado en cómputo que OpenAI en este momento, utiliza el pensamiento adaptativo para ahorrar cómputo. Según un usuario de HackerNews:
[El pensamiento adaptativo] es un problema resuelto para las empresas. Resuelve sus problemas. No los tuyos ;)
Para colmo, Anthropic también actualizó el tokenizador del modelo, lo que hace que use más tokens de lo normal, haciendo que sea entre un 20-50% más caro que Opus 4.6 para el mismo número de caracteres.
Para la mayoría de las personas, Opus 4.7 es, en el mejor de los casos, una actualización lateral, sacrificando inteligencia bruta y capacidad por fiabilidad. Para la mayoría de los demás casos de uso parece ser una ligera degradación, por lo que no recomendaría usarlo en este momento a menos que rinda notablemente mejor para tus propios casos de uso.
Qwen 3.6 35B
Menos de 2 meses después de los lanzamientos de Qwen 3.5, ya tenemos nuestro primer modelo de código abierto Qwen 3.6, una actualización del modelo 35B-A3B de mezcla de expertos.
Los modelos densos Qwen 3.5 y Gemma 4 (los modelos de 27B y 31B en el gráfico anterior) fueron considerados los primeros modelos lo suficientemente buenos para usarse en entornos de programación e interfaces de agentes como OpenClaw.
Este modelo Qwen 3.6 es capaz de superar holgadamente a ambos modelos densos, siendo mucho más eficiente, lo que permite ejecutarlo a velocidades decentes (>20 tokens por segundo) en prácticamente cualquier hardware con al menos 24 GB de memoria.
En términos de sus puntuaciones en benchmarks, se sitúa alrededor del nivel de Sonnet 4.5, lo cual es una locura dado que es al menos un orden de magnitud más pequeño que Sonnet, que fue lanzado hace apenas 5 meses.
Si esta tendencia continúa, significa que tendremos un modelo al nivel de Opus 4.6/GPT 5.4 que podremos ejecutar en casa con bastante facilidad en 6 meses.
Personalmente he estado usando este modelo con Hermes Agent (una alternativa a OpenClaw que es un poco más amigable para los modelos de código abierto) y ha funcionado bastante bien sin problemas mayores.
He visto una opinión similar entre quienes participan en LocalLLaMA y lo han usado como agente personal y también como asistente de programación bastante competente.
Como dije con los modelos Qwen3.5 y Gemma 4, ahora es el mejor momento para empezar a usar LLMs locales, porque están comenzando a ser lo suficientemente buenos como para reemplazar a OpenAI y Anthropic en tareas de dificultad fácil y media.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Midjourney 8.1 y Seedance 2.0 creado por Jerrod Lew en Twitter