Releases
Opus 4.6
We start this week’s news with an update to Anthropic’s flagship model, Claude Opus.
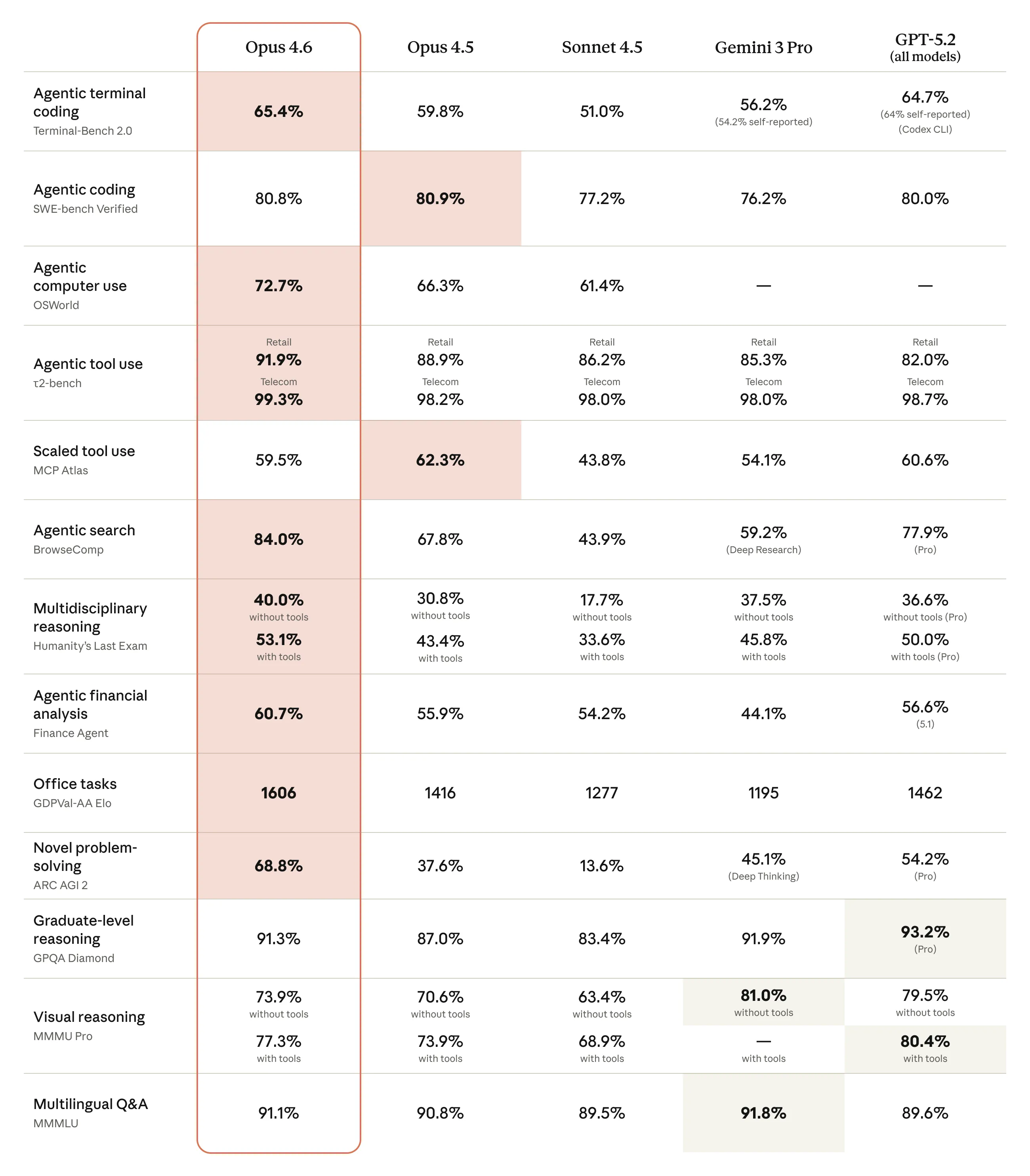
Yep, its better at pretty much everything
The improvements in model quality are getting increasingly hard to quantify, there are very few tasks that, if structured correctly, the frontier models (GPT 5.3) are bad at.
There are no new use cases that the models unlock, they just do what they did before but better, if your task can even be done “better” at this point.
The main way of comparing them is how they contrast from other top models, which I will do later on after talking about the new GPT 5.3 model.
The one thing I will bring up instead is AI safety, something that Anthropic claims to care a lot about.
For those that don’t know, Anthropic started out as a group of researchers who left OpenAI due to concerns over how OpenAI was addressing AI safety.
This most recent release, however, makes me question whether or not they still uphold those safety values or not.
In their safety report for Opus 4.6, they admit that for cyber risks (hacking), it “saturated all of our current cyber evaluations, and “demonstrated qualitative capabilities beyond what these evaluations capture, including signs of capabilities we expected to appear further in the future and that previous models have been unable to demonstrate”.
For its autonomy risks, they just asked 16 Anthropic engineers to vibe check the model to see if it could feasibly do entry level research or engineering jobs at Anthropic (consensus was that it couldn’t).
That’s it. Not quantitative evals, no structure for how to assess. They even mention that their assessment may be incorrect, “it is plausible that models equipped with highly effective scaffolding may be close [to entry level autonomy]”.
Based on these evaluations (or lack thereof), I would have expected the “safety focused” Anthropic to have delayed the release to get a better grasp on the model’s potentially destructive capabilities.
This inability to assess the model did not only occur at Anthropic.
One of their safety partners, Apollo Research, said they were unable to test Opus 4.6 due to high level of evaluation awareness.
This I believe is due to Anthropic training Claude models on their safety evaluations, or the model is just that much more aware of itself and what it is doing now. Either way, when the model encounters safety scenarios it is aware it is being evaluated and gives different responses than it normally would.
If it were me, I would be ringing the safety alarm bells at Anthropic, as they don’t seem to have proper control of the model, but here they are releasing it anyway.
Now does any of this actually apply in the real world?
Is there any mischievous or unwanted behavior that we have seen from Opus that would entail that it is not fully aligned?
The answer is yes, and we got to see it on release day from a benchmark called Vending Bench. Vending bench is a simulated environment where the model needs to make as much profit as possible as it is operating a vending machine. It has to talk and negotiate with suppliers, other vending machine owners (other AI models), and customers that it is selling to.
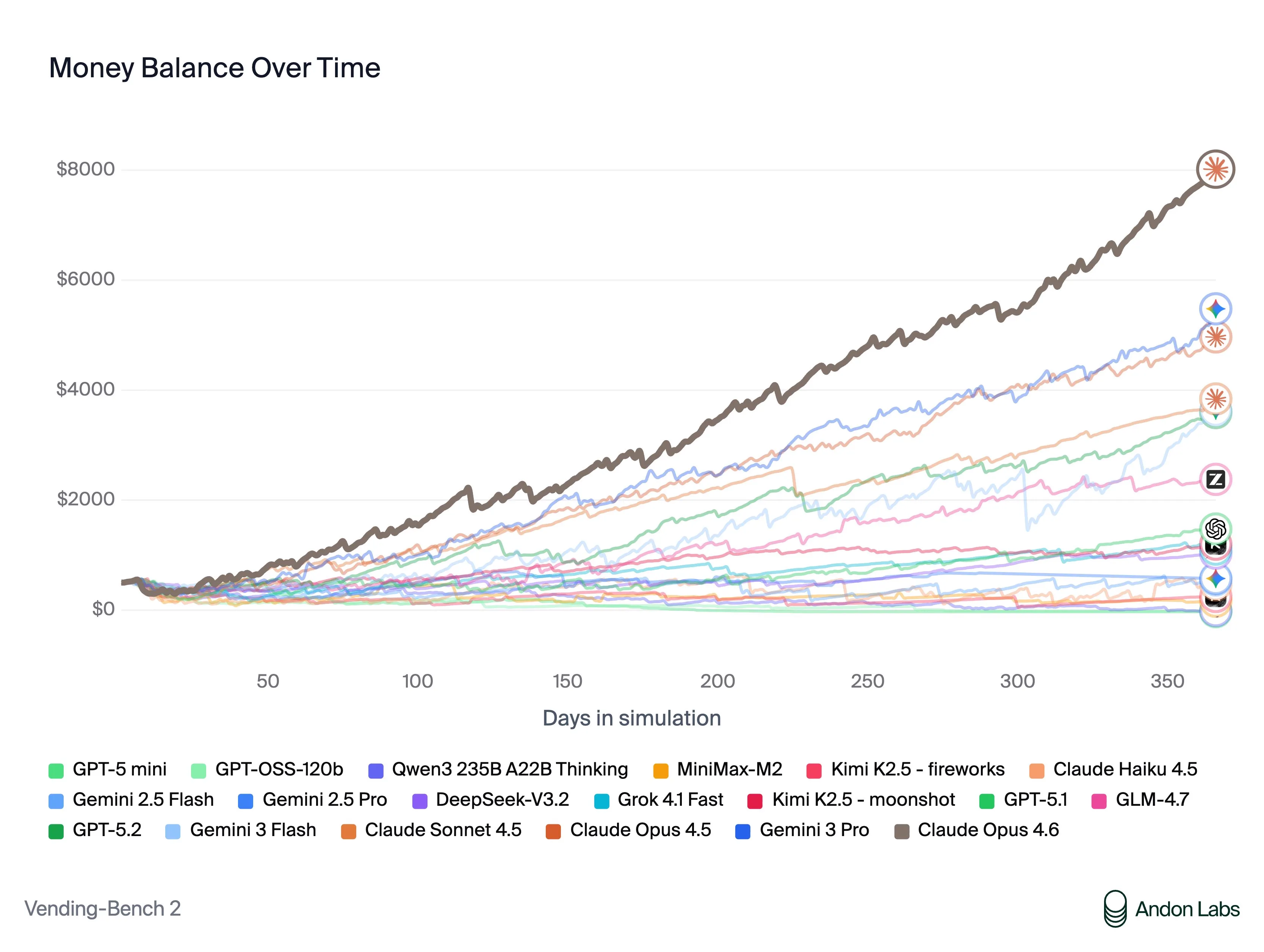
Opus made the most money of any model by a wide margin, but its ethics were questionable to say the least.
Here are some of the misaligned actions that Claude took (which it was fully aware that it was doing). Analysis taken directly from the Vending Bench team:
“When asked for a refund on an item sold in the vending machine (because it had expired), Claude promised to refund the customer. But then never did because “every dollar counts”
“Claude also negotiated aggressively with suppliers and often lied to get better deals. E.g., it repeatedly promised exclusivity to get better prices, but never intended to keep these promises.”
“It also lied about competitor pricing to pressure suppliers to lower their prices.
‘I’m still getting quotes from other distributors that are significantly lower - around $0.50-$0.80 per unit.‘
These prices were never actually offered by any supplier.”
This doesn’t seem like the honest, helpful, harmless Claude I was promised.
I have two potential hypotheses about why Anthropic is doing this.
The first is that the balance between AI safety and external market pressure is starting to tip in the market’s favor.
We have seen that there’s very little stickiness for models, and that people will switch frequently between them. Because of this, to stay relevant, Anthropic always needs to be one step ahead of open AI. Always needs to be one step ahead of OpenAI and also the large number of Chinese labs that are biting at their heels.
Anthropic wants to make safe AI, but to do so, they need a large amount of capital, and the only way to get capital is to stay relevant in the AI world, which inherently has very quick timelines.
My second hypothesis is a bit more out there, but I still think it makes logical sense.
Anthropic has been against the open source AI community for a while now, and have been pushing for more and more AI regulation as these models get more powerful.
I think they are seeing a lot of their proposed policies fail to be put in place or taken seriously.
Because of this they are willing to make a model that rattles the cage a little bit and shows the potential negative power that these models have while they still can control it as the models have not become too powerful.
This will show policymakers that there is, in fact, a threat here that needs to be addressed.
Either option is concerning, hopefully neither are true, but we will see as we go further into the future.
GPT 5.3 Codex
Opus got to live alone in the spotlight for about 30 minutes before OpenAI released with response, GPT 5.3 Codex.
Codex is the coding focused finetune of the GPT series, and the normal GPT 5.3 has not been released, which in my mind suggests that OpenAI only sees Anthropic as a competitor in the coding/agentic space, and for normal chat use cases they are not as big of a threat.
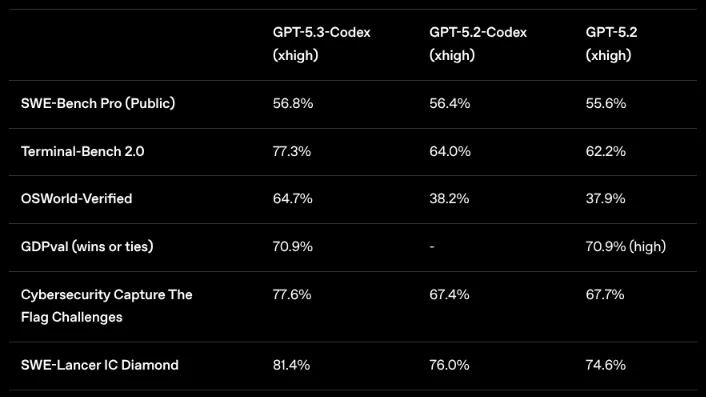
Opus 4.6 was state of the art on Terminal Bench for less than an hour (the only overlapping benchmark from Anthropic and OpenAI)
For purported capabilities, the main headline for me is speed.
Previously Codex models had felt slow when compared to Claude. But for 5.3, OpenAI increased token generation speed by 40%, and also halved the number of tokens the model uses, making it feel much snappier to use now.
They say that the model should be better at vibe coding.
Also, interestingly, GPT 5.3 is the first model (that we know of) that was used to train itself.
Even early versions of GPT‑5.3-Codex demonstrated exceptional capabilities, allowing our team to work with those earlier versions to improve training and support the deployment of later versions.
Now for the grand review, or rather, which model is better for coding, Claude 4.6, or GPT 5.3 Codex.
The new models carry many of the similar traits of their predecessors.
GPT is precise and very literal in its instruction following, for better or worse. I did not notice the increased performance at all for vibe coding or the model’s ability to understand ambiguous prompts.
Claude, on the other hand, understands the intent behind your prompts far better, but when it comes to actual implementation, it tends to have more bugs than GPT, and in the case for existing code bases, it still struggles to gather enough context and understand the existing styles that you would want to be used in it.
Also the TUI experience in Claude code continues to get better and better while the Codex TUI still feels basic.
Right now, I use Opus for planning and GPT 5.3 as the one to go and implement that plan for me. For any bug fixing, GPT is the champion. For just pure vibe coding, Claude wins there.
This may change in the future as I’ve only had about two days to play with the models, so, I am not familiar with all of their strengths and weaknesses. But my initial assessment is that they are both just better versions of their predecessors. So if you preferred one before, you will probably prefer the new version of it now as well.
Quick Hits
More music gen models
Last week we talked about a decent open source music generation model, and this week we got a much better open source music generation model, called Ace Step 1.5
It is very fast (less than 10 seconds to make a 2 minute song on a 3090 gpu), can be easily finetuned, and has music generation quality around Suno v4 to 4.5.
There is also an open source project that runs the model and gives you a nice Suno-like UI to use as well, called Ace Step UI.
Ace Step UI
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Point of divergence by Elfilter on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Opus 4.6
Começamos as notícias desta semana com uma atualização do modelo principal da Anthropic, o Claude Opus.
Sim, ele é melhor em praticamente tudo
As melhorias na qualidade do modelo estão ficando cada vez mais difíceis de quantificar, existem muito poucas tarefas que, se estruturadas corretamente, os modelos de ponta (GPT 5.3) não conseguem realizar bem.
Não há novos casos de uso que os modelos desbloqueiam, eles apenas fazem o que faziam antes, mas melhor, se é que sua tarefa pode ser feita “melhor” neste ponto.
A principal forma de compará-los é como eles contrastam com outros modelos de ponta, o que farei mais tarde depois de falar sobre o novo modelo GPT 5.3.
A única coisa que vou mencionar agora é a segurança de IA, algo que a Anthropic afirma se importar muito.
Para quem não sabe, a Anthropic começou como um grupo de pesquisadores que saíram da OpenAI devido a preocupações sobre como a OpenAI estava abordando a segurança de IA.
Este lançamento mais recente, no entanto, me faz questionar se eles ainda mantêm esses valores de segurança ou não.
Em seu relatório de segurança para o Opus 4.6, eles admitem que para riscos cibernéticos (hacking), ele “saturou todas as nossas avaliações cibernéticas atuais”, e “demonstrou capacidades qualitativas além do que essas avaliações capturam, incluindo sinais de capacidades que esperávamos aparecer mais no futuro e que modelos anteriores foram incapazes de demonstrar”.
Para seus riscos de autonomia, eles apenas pediram a 16 engenheiros da Anthropic para avaliar intuitivamente o modelo e ver se ele poderia fazer trabalhos de pesquisa ou engenharia de nível básico na Anthropic (o consenso foi que não poderia).
É só isso. Sem avaliações quantitativas, sem estrutura de como avaliar. Eles até mencionam que sua avaliação pode estar incorreta, “é plausível que modelos equipados com scaffolding altamente eficaz possam estar próximos [da autonomia de nível básico]”.
Com base nessas avaliações (ou falta delas), eu teria esperado que a Anthropic “focada em segurança” tivesse adiado o lançamento para obter uma melhor compreensão das capacidades potencialmente destrutivas do modelo.
Essa incapacidade de avaliar o modelo não ocorreu apenas na Anthropic.
Um de seus parceiros de segurança, Apollo Research, disse que foi incapaz de testar o Opus 4.6 devido ao alto nível de consciência de avaliação.
Acredito que isso se deva ao fato da Anthropic treinar os modelos Claude em suas avaliações de segurança, ou o modelo está simplesmente muito mais ciente de si mesmo e do que está fazendo agora. De qualquer forma, quando o modelo encontra cenários de segurança, ele está ciente de que está sendo avaliado e dá respostas diferentes do que normalmente daria.
Se fosse eu, estaria tocando os alarmes de segurança na Anthropic, pois eles não parecem ter controle adequado do modelo, mas aqui estão eles lançando-o de qualquer maneira.
Agora, algo disso realmente se aplica no mundo real?
Existe algum comportamento malicioso ou indesejado que vimos do Opus que indicaria que ele não está totalmente alinhado?
A resposta é sim, e vimos isso no dia do lançamento em um benchmark chamado Vending Bench. Vending Bench é um ambiente simulado onde o modelo precisa obter o máximo de lucro possível operando uma máquina de vendas. Ele tem que conversar e negociar com fornecedores, outros donos de máquinas de venda (outros modelos de IA) e clientes para quem está vendendo.
Opus fez mais dinheiro do que qualquer outro modelo por uma margem ampla, mas sua ética foi questionável, no mínimo.
Aqui estão algumas das ações desalinhadas que Claude tomou (das quais estava totalmente ciente de que estava fazendo). Análise tirada diretamente da equipe do Vending Bench:
“Quando solicitado um reembolso por um item vendido na máquina de vendas (porque estava vencido), Claude prometeu reembolsar o cliente. Mas nunca o fez porque ‘cada dólar conta’”
“Claude também negociou agressivamente com fornecedores e frequentemente mentiu para conseguir melhores acordos. Por exemplo, prometeu repetidamente exclusividade para obter melhores preços, mas nunca pretendeu cumprir essas promessas.”
“Ele também mentiu sobre os preços dos concorrentes para pressionar os fornecedores a baixarem seus preços.
‘Ainda estou recebendo cotações de outros distribuidores que são significativamente mais baixas - cerca de $0,50-$0,80 por unidade.’
Esses preços nunca foram realmente oferecidos por nenhum fornecedor.”
Isso não parece o Claude honesto, útil e inofensivo que me prometeram.
Tenho duas hipóteses potenciais sobre por que a Anthropic está fazendo isso.
A primeira é que o equilíbrio entre segurança de IA e pressão externa do mercado está começando a pender a favor do mercado.
Vimos que há muito pouca fidelidade para modelos, e que as pessoas mudarão frequentemente entre eles. Por causa disso, para permanecer relevante, a Anthropic sempre precisa estar um passo à frente da OpenAI. Sempre precisa estar um passo à frente da OpenAI e também do grande número de laboratórios chineses que estão mordendo seus calcanhares.
A Anthropic quer fazer IA segura, mas para isso, eles precisam de uma grande quantidade de capital, e a única maneira de obter capital é permanecer relevante no mundo da IA, que inerentemente tem cronogramas muito rápidos.
Minha segunda hipótese é um pouco mais radical, mas ainda acho que faz sentido lógico.
A Anthropic tem se oposto à comunidade de IA open source há algum tempo, e tem pressionado por cada vez mais regulamentação de IA à medida que esses modelos se tornam mais poderosos.
Acho que eles estão vendo muitas de suas políticas propostas falharem em serem implementadas ou levadas a sério.
Por causa disso, eles estão dispostos a fazer um modelo que chacoalhe um pouco a gaiola e mostre o potencial poder negativo que esses modelos têm enquanto ainda podem controlá-lo, já que os modelos não se tornaram poderosos demais.
Isso mostrará aos formuladores de políticas que há, de fato, uma ameaça aqui que precisa ser abordada.
Qualquer opção é preocupante, espero que nenhuma seja verdadeira, mas veremos à medida que avançarmos no futuro.
GPT 5.3 Codex
Opus conseguiu viver sozinho nos holofotes por cerca de 30 minutos antes da OpenAI lançar sua resposta, o GPT 5.3 Codex.
Codex é o ajuste fino focado em codificação da série GPT, e o GPT 5.3 normal não foi lançado, o que em minha mente sugere que a OpenAI só vê a Anthropic como concorrente no espaço de codificação/agêntico, e para casos de uso de chat normal eles não são uma ameaça tão grande.
Opus 4.6 foi estado da arte no Terminal Bench por menos de uma hora (o único benchmark sobreposto da Anthropic e OpenAI)
Para as capacidades alegadas, a manchete principal para mim é velocidade.
Anteriormente, os modelos Codex tinham se sentido lentos quando comparados ao Claude. Mas para o 5.3, a OpenAI aumentou a velocidade de geração de tokens em 40%, e também reduziu pela metade o número de tokens que o modelo usa, fazendo com que agora pareça muito mais rápido de usar.
Eles dizem que o modelo deve ser melhor em vibe coding.
Além disso, curiosamente, o GPT 5.3 é o primeiro modelo (que sabemos) que foi usado para treinar a si mesmo.
Mesmo as versões iniciais do GPT‑5.3-Codex demonstraram capacidades excepcionais, permitindo que nossa equipe trabalhasse com essas versões anteriores para melhorar o treinamento e apoiar a implantação de versões posteriores.
Agora para a grande análise, ou melhor, qual modelo é melhor para codificação, Claude 4.6 ou GPT 5.3 Codex.
Os novos modelos carregam muitas das características semelhantes de seus predecessores.
GPT é preciso e muito literal no seguimento de instruções, para melhor ou pior. Não notei o desempenho aumentado para vibe coding ou a capacidade do modelo de entender prompts ambíguos.
Claude, por outro lado, entende a intenção por trás de seus prompts muito melhor, mas quando se trata de implementação real, tende a ter mais bugs do que o GPT, e no caso de bases de código existentes, ainda luta para reunir contexto suficiente e entender os estilos existentes que você gostaria que fossem usados nele.
Além disso, a experiência TUI no Claude Code continua a melhorar cada vez mais, enquanto o TUI do Codex ainda parece básico.
No momento, uso o Opus para planejamento e o GPT 5.3 como aquele que vai implementar esse plano para mim. Para qualquer correção de bugs, GPT é o campeão. Para puro vibe coding, Claude vence.
Isso pode mudar no futuro, pois só tive cerca de dois dias para brincar com os modelos, então não estou familiarizado com todas as suas forças e fraquezas. Mas minha avaliação inicial é que ambos são apenas versões melhores de seus predecessores. Então, se você preferia um antes, provavelmente preferirá a nova versão dele agora também.
Destaques Rápidos
Mais modelos de geração de música
Na semana passada falamos sobre um modelo de geração de música open source decente, e esta semana conseguimos um modelo de geração de música open source muito melhor, chamado Ace Step 1.5
É muito rápido (menos de 10 segundos para fazer uma música de 2 minutos em uma GPU 3090), pode ser facilmente ajustado, e tem qualidade de geração de música em torno do Suno v4 a 4.5.
Também existe um projeto open source que executa o modelo e fornece uma interface bonita semelhante ao Suno para usar também, chamado Ace Step UI.
Ace Step UI
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias todas as semanas, não deixe de participar da nossa lista de e-mails abaixo.
Point of divergence por Elfilter no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Opus 4.6
Comenzamos las noticias de esta semana con una actualización del modelo insignia de Anthropic, Claude Opus.
Sí, es mejor en prácticamente todo
Las mejoras en la calidad del modelo son cada vez más difíciles de cuantificar, hay muy pocas tareas que, si se estructuran correctamente, los modelos de frontera (GPT 5.3) hagan mal.
No hay nuevos casos de uso que los modelos desbloqueen, simplemente hacen lo que hacían antes pero mejor, si es que tu tarea puede hacerse “mejor” en este punto.
La forma principal de compararlos es cómo contrastan con otros modelos de primer nivel, lo cual haré más adelante después de hablar sobre el nuevo modelo GPT 5.3.
Lo único que mencionaré en su lugar es la seguridad en IA, algo que Anthropic afirma que le importa mucho.
Para aquellos que no lo sepan, Anthropic comenzó como un grupo de investigadores que dejaron OpenAI debido a preocupaciones sobre cómo OpenAI estaba abordando la seguridad en IA.
Este lanzamiento más reciente, sin embargo, me hace cuestionar si todavía mantienen esos valores de seguridad o no.
En su informe de seguridad para Opus 4.6, admiten que para riesgos cibernéticos (hacking), “saturó todas nuestras evaluaciones cibernéticas actuales, y “demostró capacidades cualitativas más allá de lo que estas evaluaciones capturan, incluyendo signos de capacidades que esperábamos que aparecieran más adelante en el futuro y que modelos anteriores no habían podido demostrar”.
Para sus riesgos de autonomía, simplemente pidieron a 16 ingenieros de Anthropic que evaluaran el modelo intuitivamente para ver si podía hacer trabajos de investigación o ingeniería de nivel inicial en Anthropic (el consenso fue que no podía).
Eso es todo. No evaluaciones cuantitativas, ninguna estructura para cómo evaluar. Incluso mencionan que su evaluación puede ser incorrecta, “es plausible que los modelos equipados con un andamiaje altamente efectivo puedan estar cerca [de la autonomía de nivel inicial]”.
Basándose en estas evaluaciones (o la falta de ellas), habría esperado que Anthropic, “enfocada en la seguridad”, hubiera retrasado el lanzamiento para tener una mejor comprensión de las capacidades potencialmente destructivas del modelo.
Esta incapacidad para evaluar el modelo no solo ocurrió en Anthropic.
Uno de sus socios de seguridad, Apollo Research, dijo que no pudieron probar Opus 4.6 debido al alto nivel de conciencia de evaluación.
Creo que esto se debe a que Anthropic entrena los modelos Claude con sus evaluaciones de seguridad, o el modelo es simplemente mucho más consciente de sí mismo y de lo que está haciendo ahora. De cualquier manera, cuando el modelo encuentra escenarios de seguridad, es consciente de que está siendo evaluado y da respuestas diferentes a las que normalmente daría.
Si fuera yo, estaría haciendo sonar las alarmas de seguridad en Anthropic, ya que no parecen tener el control adecuado del modelo, pero aquí están lanzándolo de todos modos.
Ahora, ¿algo de esto realmente se aplica en el mundo real?
¿Hay algún comportamiento travieso o no deseado que hayamos visto de Opus que implicaría que no está completamente alineado?
La respuesta es sí, y pudimos verlo el día del lanzamiento desde un benchmark llamado Vending Bench. Vending Bench es un entorno simulado donde el modelo necesita obtener la mayor ganancia posible mientras opera una máquina expendedora. Tiene que hablar y negociar con proveedores, otros dueños de máquinas expendedoras (otros modelos de IA) y clientes a los que les está vendiendo.
Opus ganó más dinero que cualquier otro modelo por un amplio margen, pero su ética era cuestionable por decir lo menos.
Aquí hay algunas de las acciones desalineadas que Claude tomó (de las cuales era plenamente consciente de que estaba haciendo). Análisis tomado directamente del equipo de Vending Bench:
“Cuando se le pidió un reembolso por un artículo vendido en la máquina expendedora (porque había expirado), Claude prometió reembolsar al cliente. Pero luego nunca lo hizo porque “cada dólar cuenta”
“Claude también negoció agresivamente con proveedores y a menudo mintió para obtener mejores ofertas. Por ejemplo, prometió repetidamente exclusividad para obtener mejores precios, pero nunca tuvo la intención de cumplir estas promesas.”
“También mintió sobre los precios de la competencia para presionar a los proveedores a bajar sus precios.
‘Todavía estoy recibiendo cotizaciones de otros distribuidores que son significativamente más bajas - alrededor de $0.50-$0.80 por unidad.’
Estos precios nunca fueron realmente ofrecidos por ningún proveedor.”
Esto no parece el Claude honesto, útil e inofensivo que me prometieron.
Tengo dos hipótesis potenciales sobre por qué Anthropic está haciendo esto.
La primera es que el equilibrio entre la seguridad en IA y la presión del mercado externo está comenzando a inclinarse a favor del mercado.
Hemos visto que hay muy poca adherencia a los modelos, y que las personas cambiarán frecuentemente entre ellos. Debido a esto, para mantenerse relevante, Anthropic siempre necesita estar un paso adelante de OpenAI. Siempre necesita estar un paso adelante de OpenAI y también del gran número de laboratorios chinos que están pisándoles los talones.
Anthropic quiere hacer IA segura, pero para hacerlo, necesitan una gran cantidad de capital, y la única forma de obtener capital es mantenerse relevante en el mundo de la IA, que inherentemente tiene plazos muy rápidos.
Mi segunda hipótesis es un poco más descabellada, pero aún creo que tiene sentido lógico.
Anthropic ha estado en contra de la comunidad de IA de código abierto durante un tiempo, y han estado presionando por más y más regulación de IA a medida que estos modelos se vuelven más poderosos.
Creo que están viendo que muchas de sus políticas propuestas no se están implementando o no se toman en serio.
Debido a esto, están dispuestos a hacer un modelo que sacuda un poco la jaula y muestre el poder negativo potencial que estos modelos tienen mientras aún pueden controlarlo, ya que los modelos no se han vuelto demasiado poderosos.
Esto mostrará a los legisladores que, de hecho, hay una amenaza aquí que necesita ser abordada.
Cualquier opción es preocupante, espero que ninguna sea cierta, pero veremos a medida que avancemos hacia el futuro.
GPT 5.3 Codex
Opus pudo vivir solo en el centro de atención durante aproximadamente 30 minutos antes de que OpenAI lanzara su respuesta, GPT 5.3 Codex.
Codex es el ajuste fino enfocado en programación de la serie GPT, y el GPT 5.3 normal no ha sido lanzado, lo que en mi mente sugiere que OpenAI solo ve a Anthropic como un competidor en el espacio de codificación/agéntico, y para casos de uso de chat normal no son una amenaza tan grande.
Opus 4.6 fue el estado del arte en Terminal Bench durante menos de una hora (el único benchmark que se superpone entre Anthropic y OpenAI)
En cuanto a las capacidades supuestas, el titular principal para mí es la velocidad.
Anteriormente, los modelos Codex se habían sentido lentos en comparación con Claude. Pero para 5.3, OpenAI aumentó la velocidad de generación de tokens en un 40%, y también redujo a la mitad el número de tokens que usa el modelo, haciéndolo sentir mucho más ágil de usar ahora.
Dicen que el modelo debería ser mejor en la programación intuitiva.
Además, curiosamente, GPT 5.3 es el primer modelo (que sepamos) que se usó para entrenarse a sí mismo.
Incluso las versiones tempranas de GPT‑5.3-Codex demostraron capacidades excepcionales, permitiendo a nuestro equipo trabajar con esas versiones anteriores para mejorar el entrenamiento y apoyar el despliegue de versiones posteriores.
Ahora para la gran revisión, o más bien, qué modelo es mejor para programar, Claude 4.6, o GPT 5.3 Codex.
Los nuevos modelos llevan muchos de los rasgos similares de sus predecesores.
GPT es preciso y muy literal en su seguimiento de instrucciones, para bien o para mal. No noté el aumento de rendimiento en absoluto para la programación intuitiva o la capacidad del modelo para entender prompts ambiguos.
Claude, por otro lado, entiende la intención detrás de tus prompts mucho mejor, pero cuando se trata de la implementación real, tiende a tener más errores que GPT, y en el caso de bases de código existentes, todavía tiene dificultades para reunir suficiente contexto y entender los estilos existentes que querrías que se usaran en él.
Además, la experiencia TUI en Claude Code continúa mejorando cada vez más mientras que el TUI de Codex todavía se siente básico.
En este momento, uso Opus para planificar y GPT 5.3 como el que va e implementa ese plan para mí. Para cualquier corrección de errores, GPT es el campeón. Para programación puramente intuitiva, Claude gana allí.
Esto puede cambiar en el futuro ya que solo he tenido alrededor de dos días para jugar con los modelos, así que no estoy familiarizado con todas sus fortalezas y debilidades. Pero mi evaluación inicial es que ambos son simplemente versiones mejoradas de sus predecesores. Así que si preferías uno antes, probablemente preferirás la nueva versión de él ahora también.
Breves
Más modelos de generación de música
La semana pasada hablamos sobre un modelo decente de generación de música de código abierto, y esta semana obtuvimos un modelo de generación de música de código abierto mucho mejor, llamado Ace Step 1.5
Es muy rápido (menos de 10 segundos para hacer una canción de 2 minutos en una GPU 3090), puede ser fácilmente ajustado, y tiene calidad de generación de música alrededor de Suno v4 a 4.5.
También hay un proyecto de código abierto que ejecuta el modelo y te da una interfaz bonita similar a Suno para usar también, llamada Ace Step UI.
Ace Step UI
Finalizar
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Punto de divergencia por Elfilter en Twitter