News
Anthropic overtakes OpenAI in API revenue
A recent report from Menlo Ventures has shown that Anthropic has recently passed OpenAI in terms of LLM API revenue, capturing over 30% of the market versus OpenAI’s 25%. They also have an even more commanding lead for coding market share capturing 42% of the market. This comes of the heels of the explosion in usage of Cursor and Claude Code in the last year, as Anthropic has become the defacto standard for real world agentic applications.
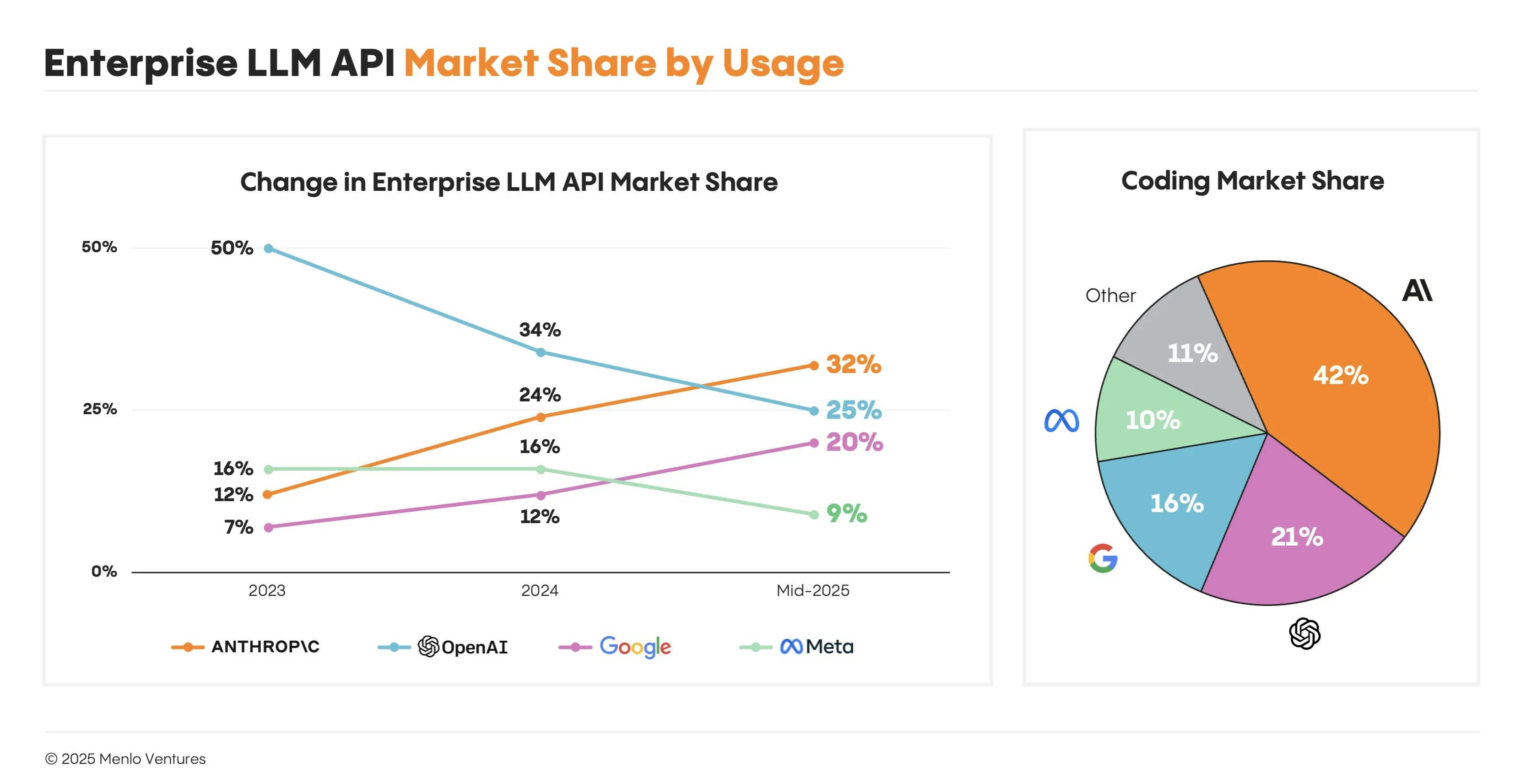
Also, as a part of the report, they showed that only 11% of enterprises are using open-source models in high-usage scenarios, and about 50% of them are not using open-source models at all, even for experimentation or smaller tasks. This is due to the high costs of running or finetuning your own model versus optimizing a system prompt for a closed source model, especially with the top models changing every week. I expect this number to go up in the future if AI progress starts to stagnate, or go to 0 if someone achieves AGI.

Releases
Z.ai takes over the top
I have been hyping up Z.ai the last few weeks now, and they have not disappointed. This week they have released their GLM 4.5 series of models, which from what I have seen, are the best open source agentic models on the market right now.
They have released 2 variants, 4.5 and 4.5 Air. They are both MoE models, with 4.5 having 355 billion total params and 32 billion active params, and Air having 106 billion params with 12 billion active. What this means is that 4.5 needs a proper multi gpu (H100s or better) setup to run at any meaningful speeds, while the Air model could feasible be run at home with a combo cpu + gpu setup using something like Ktransformers.
But why would you want to use these models? Simply put, because they are incredible.
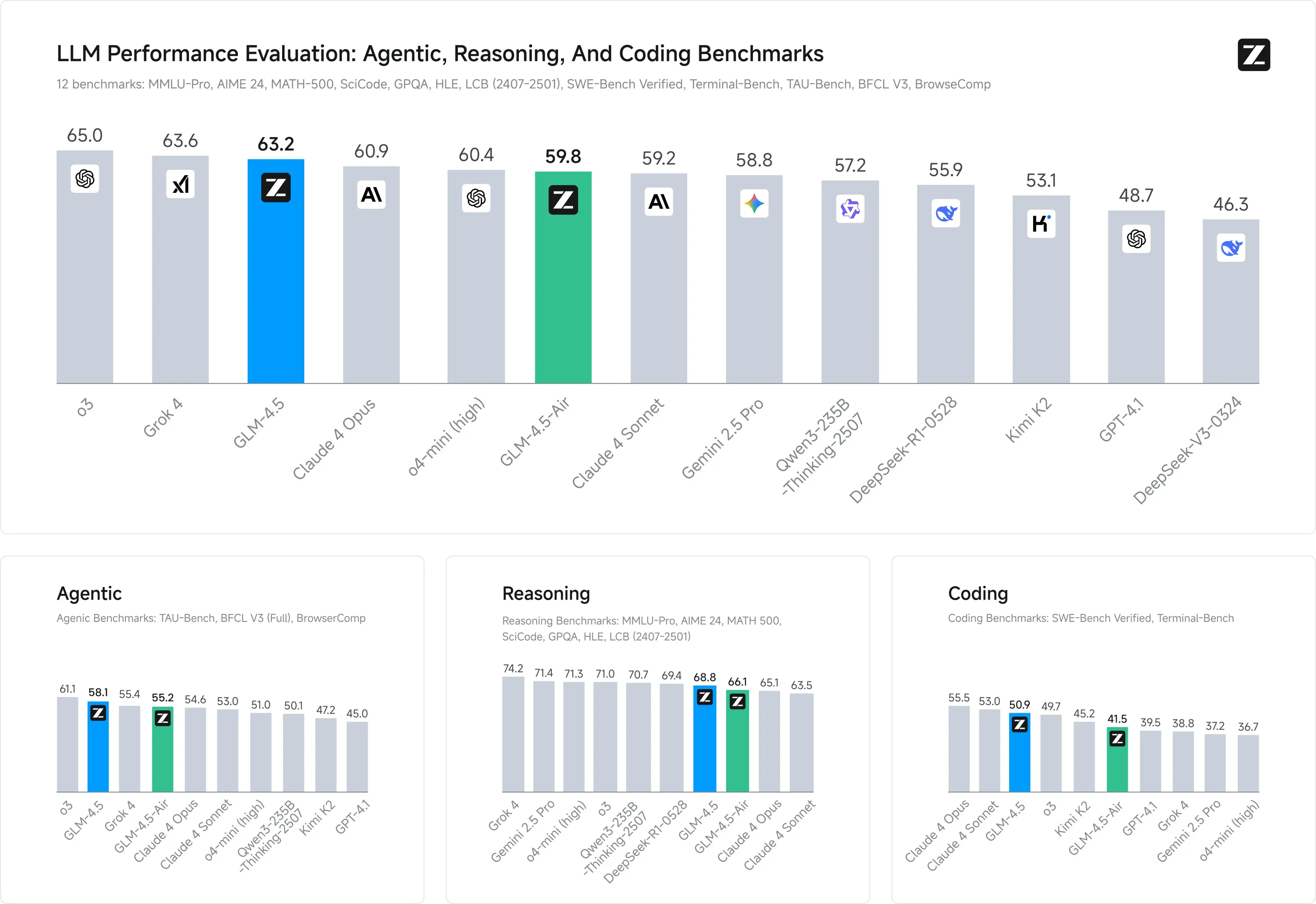
The GLM 4.5 go blow for blow with the Claude 4 models and the OpenAI o series
Public benchmarks are one thing, but do they actually pass the test in the real world? Of course they do.

When evaluated by humans, GLM 4.5 matches Sonnet in agentic coding, the first model that I have seen do so
You don’t have to take other people’s word for it though. I have switched to using GLM 4.5 in Claude Code, and I have noticed no practical difference, other than the cost being 5x less. Reddit also agrees, with users comparing the Air model to the new Qwen3 235B model that was released last week, while being 2x smaller, and others also agreeing with me that the large model is akin to Sonnet/Opus for agentic and coding tasks.
I plan on running the Air model as my daily driver local model, probably taking the role that I use o3 for for day to day tasks. I will also probably stay with the large 4.5 models as well for my coding workflows as well for the foreseeable future.
If you haven’t been able to tell already, these models blow the previous best models of Kimi K2 and Qwen3 by a hefty amount, all while being smaller and faster than them.
You can try both of the models for free right now on z.ai.
Wan 2.2
Alibaba has improved their SOTA open source video model, Wan 2.1, releasing their Wan 2.2 series of models. There are 2 models that they released, a 5 billion parameter “standard” model that can do both text and image to video, and then also 2 MoE models with 28 billion params with 14B active, one for text to video and the other for image to video.
The MoE models are interesting as they have 2 experts, one for high noise denoising for the early part of the generation process, and another for low noise denoising later for later steps. I think this will end up being similar to the SDXL refiner, where the community finds a way to get rid of it and unify the model to not need as many steps and parameters to make it work just as well.
From what I have seen so far, the models work well, definitely not sota when compared to closed source models like Veo3, but still a very big bump in quality versus the previous best, Wan 2.1.
A pink sports car is driving very fast along a beach at sunset, the car says “REPLICATE” on the side, it drifts around in the sand - From fofr on Twitter
Qwen3-30B-3A Update
Qwen released 3 models last week, and they must have really enjoyed all the attention that brought them, because they did the same this week, dropping 3 new versions of their 30B3A MoE Qwen3 model.
The first 2 are the basic reasoning and non reasoning variants, both of which are comparable to Gemini 2.5 Flash.
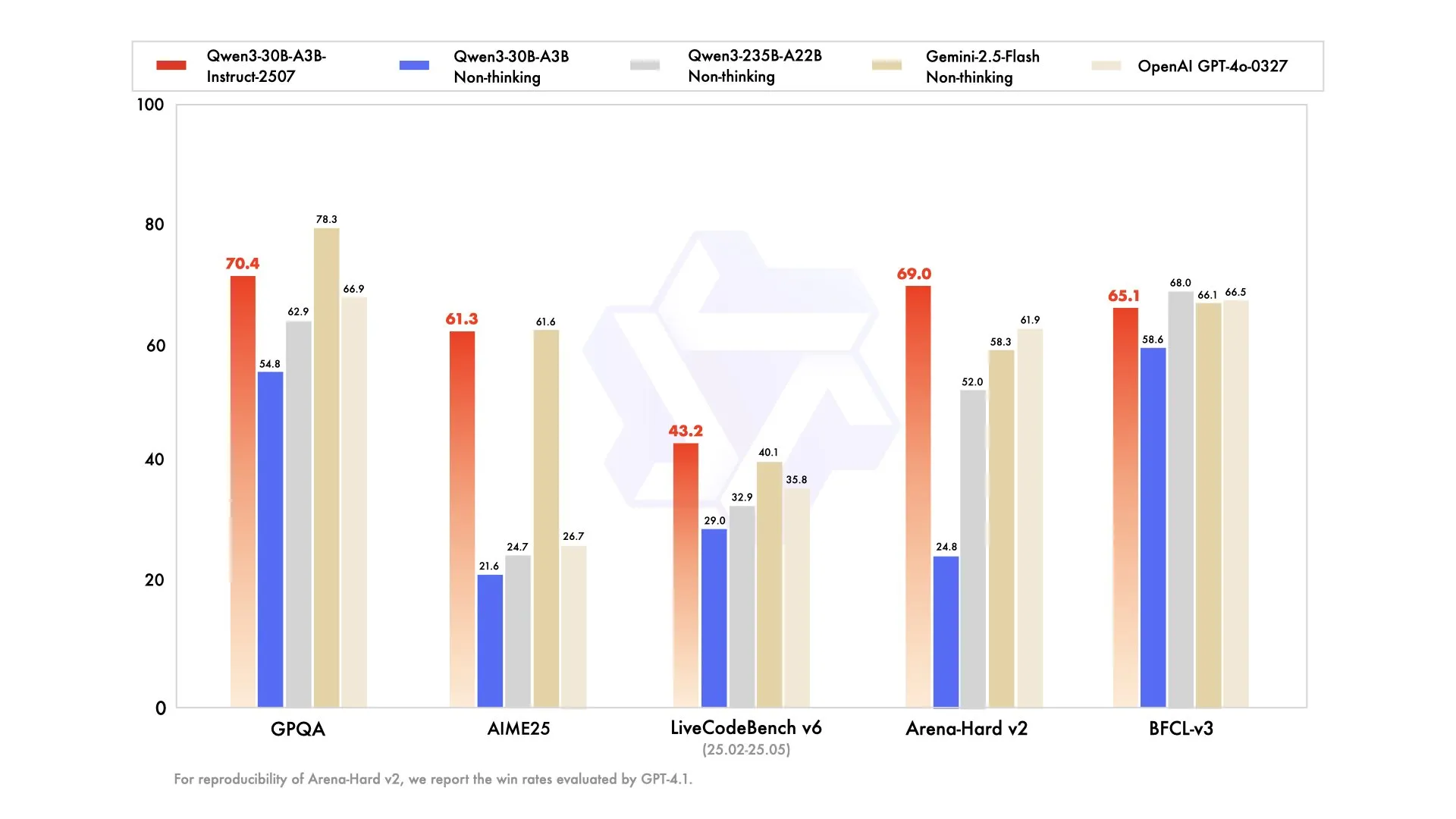
Non thinking model benchmarks
The 3rd model they released in the series is a agentic coding model, which, while not being that impressive when compared GLM 4.5 and Sonnet, does have the distinction of being the first “small” open source model that is capable of doing agentic coding at all, a task which has eluded open source for a while.
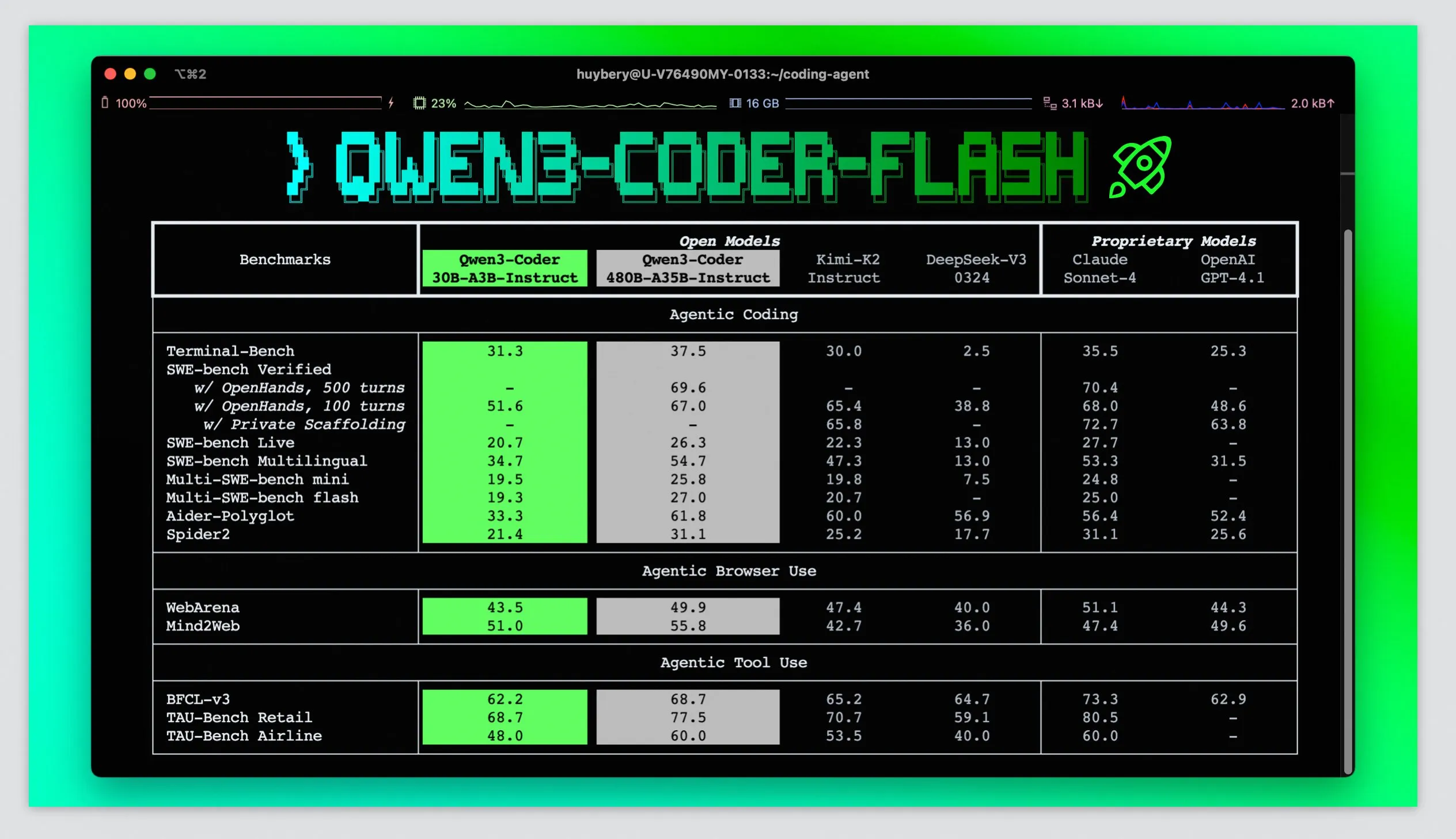
Coding model benchmarks
These models are interesting and exciting because they can be run at relatively high speeds (> 40 tokens per second) on computers without GPUs, giving more people access to these models without breaking the bank.
New BFL Open Source Model
Black Forest Labs has partnered with Krea to make a new open source image generation model, called Flux Krea dev. The model is focused on getting rid of the AI feel that many image generators have, and also allowing for unique aesthetics similar to Midjourney. They have also focused on having exceptional realism and image quality. The model uses the same architecture as the original Flux dev model, making it compatible with all image generation frameworks out of the box.

Flux schnell vs flux krea comparison - from fruesome on reddit
Speed Round
Useful tools or topics I found this week that may or not be AI related, but I didn’t have time to write a full section about.
Cerebras Code
Cerebras is launching their own Claude Code model hosting competitor, offering the Qwen3 coder model for $50 a month while also being 20 times faster. Qwen3 coder, sadly, does not appear to be that great of an agentic coding model, especially when compared to the new GLM 4.5 model that just came out. If Cerebras starts offering the GLM 4.5 model, I will immediately be picking this up though, as the speeds are almost instantaneous for text generation.
Gemini Deep Think
Google has released an upgraded version of their Gemini 2.5 Pro model called Gemini 2.5 DeepThink, which is based on the model that recently got a gold medal at the International Math Olympiad. They have scaled up the test time compute by allowing Gemini to think for longer, and also in parallel, and then be able to select the best options after going and exploring a whole bunch of different choices that it could potentially go and make.
It benchmarks very well on both public and private evals, beating even the overfit Grok 4 model from XAi. If you would like to use it, it is available through Google’s AI-Ultra subscription tier. And they say it should come out on the Gemini API in the coming weeks.
ChatGPT study mode
OpenAI has released a study mode to use to learn new subjects.
Users quickly figured out that under the hood, it’s just a prompt, thus making OpenAI a ChatGPT wrapper. Also you can have study mode at home (or with any other LLM) just by copying their system prompt.
Trackio
Weights and Biases is the most used library for tracking machine learning experiments, and it is a buggy mess, but there have been no good alternatives that researchers could use. Until now. Our saviours at Huggingface have released a library called Trackio, which is an open source, local version of Weights and Biases that you can use to track your experiments. Its meant as a drop in replacement, so you shouldn’t need to update any of you logging code at all.
Just update your code to use import trackio as wandb and your project will be free of the hell that is W&B forever.
VibeKit Auth
Wouldn’t it be nice if people could use their ChatGPT or Claude Pro subscription in your app? Now you can, using a new library called VibeKit.
Claude Tokenizer Exploration
Claude’s tokenizer is weird, Sasuke_420 on Twitter breaks down how weird it really is.
MoE finetuning library
Finetuning mixture of experts models is notoriously hard, so team at Character AI have released a battle hardened trainer written in pure PyTorch to help the community more easily fine tune these models.
Use ChatGPT agent to find coupon codes
Thank me later, which you can do by subscribing to the newsletter (link below).
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Giraffes Volleyball Championship 2022 - from remi on twitter
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Anthropic ultrapassa OpenAI em receita de API
Um relatório recente da Menlo Ventures mostrou que a Anthropic recentemente ultrapassou a OpenAI em termos de receita de API de LLM, capturando mais de 30% do mercado versus 25% da OpenAI. Eles também têm uma liderança ainda mais dominante em participação de mercado para programação, capturando 42% do mercado. Isso vem na esteira da explosão no uso do Cursor e Claude Code no último ano, já que a Anthropic se tornou o padrão de fato para aplicações agênticas do mundo real.
Além disso, como parte do relatório, eles mostraram que apenas 11% das empresas estão usando modelos de código aberto em cenários de alto uso, e cerca de 50% delas não estão usando modelos de código aberto de forma alguma, mesmo para experimentação ou tarefas menores. Isso se deve aos altos custos de executar ou fazer fine-tuning do seu próprio modelo versus otimizar um prompt de sistema para um modelo de código fechado, especialmente com os melhores modelos mudando toda semana. Espero que esse número aumente no futuro se o progresso da IA começar a estagnar, ou vá para 0 se alguém alcançar AGI.
Lançamentos
Z.ai assume o topo
Tenho falado muito sobre Z.ai nas últimas semanas, e eles não decepcionaram. Esta semana eles lançaram sua série GLM 4.5 de modelos, que pelo que vi, são os melhores modelos agênticos de código aberto do mercado neste momento.
Eles lançaram 2 variantes, 4.5 e 4.5 Air. Ambos são modelos MoE, com o 4.5 tendo 355 bilhões de parâmetros totais e 32 bilhões de parâmetros ativos, e o Air tendo 106 bilhões de parâmetros com 12 bilhões ativos. O que isso significa é que o 4.5 precisa de uma configuração adequada de multi-GPU (H100s ou melhor) para rodar em velocidades significativas, enquanto o modelo Air poderia ser executado em casa com uma configuração combo de CPU + GPU usando algo como Ktransformers.
Mas por que você gostaria de usar esses modelos? Simplesmente porque eles são incríveis.
O GLM 4.5 vai de igual para igual com os modelos Claude 4 e a série o da OpenAI
Benchmarks públicos são uma coisa, mas eles realmente passam no teste do mundo real? Claro que sim.
Quando avaliado por humanos, GLM 4.5 iguala Sonnet em programação agêntica, o primeiro modelo que vi fazer isso
Você não precisa acreditar na palavra de outras pessoas, no entanto. Mudei para usar GLM 4.5 no Claude Code, e não notei nenhuma diferença prática, além do custo ser 5x menor. O Reddit também concorda, com usuários comparando o modelo Air ao novo modelo Qwen3 235B que foi lançado na semana passada, sendo 2x menor, e outros também concordando comigo que o modelo grande é semelhante ao Sonnet/Opus para tarefas agênticas e de programação.
Planejo executar o modelo Air como meu modelo local diário, provavelmente assumindo o papel que uso o o3 para tarefas do dia a dia. Também provavelmente vou continuar com os modelos grandes 4.5 também para meus fluxos de trabalho de programação no futuro previsível.
Se você ainda não conseguiu perceber, esses modelos superam em muito os melhores modelos anteriores de Kimi K2 e Qwen3, tudo isso sendo menores e mais rápidos que eles.
Você pode experimentar ambos os modelos gratuitamente agora em z.ai.
Wan 2.2
A Alibaba melhorou seu modelo de vídeo de código aberto SOTA, Wan 2.1, lançando sua série Wan 2.2 de modelos. Existem 2 modelos que eles lançaram, um modelo “padrão” de 5 bilhões de parâmetros que pode fazer tanto texto quanto imagem para vídeo, e também 2 modelos MoE com 28 bilhões de parâmetros com 14B ativos, um para texto para vídeo e outro para imagem para vídeo.
Os modelos MoE são interessantes, pois têm 2 experts, um para remoção de ruído de alto nível para a parte inicial do processo de geração, e outro para remoção de ruído de baixo nível posteriormente para etapas posteriores. Acho que isso acabará sendo similar ao refiner SDXL, onde a comunidade encontra uma maneira de se livrar dele e unificar o modelo para não precisar de tantas etapas e parâmetros para fazê-lo funcionar tão bem.
Pelo que vi até agora, os modelos funcionam bem, definitivamente não são SOTA quando comparados a modelos de código fechado como Veo3, mas ainda assim um grande salto de qualidade versus o melhor anterior, Wan 2.1.
Um carro esportivo rosa está dirigindo muito rápido ao longo de uma praia ao pôr do sol, o carro diz “REPLICATE” na lateral, ele derrapa na areia - De fofr no Twitter
Atualização Qwen3-30B-3A
A Qwen lançou 3 modelos na semana passada, e eles devem ter realmente gostado de toda a atenção que isso trouxe, porque fizeram o mesmo esta semana, lançando 3 novas versões de seu modelo MoE Qwen3 30B3A.
Os primeiros 2 são as variantes básicas de raciocínio e não raciocínio, ambas comparáveis ao Gemini 2.5 Flash.
Benchmarks do modelo não pensante
O 3º modelo que eles lançaram na série é um modelo de programação agêntica, que, embora não seja tão impressionante quando comparado ao GLM 4.5 e Sonnet, tem a distinção de ser o primeiro modelo “pequeno” de código aberto capaz de fazer programação agêntica, uma tarefa que tem escapado do código aberto por um tempo.
Benchmarks do modelo de programação
Esses modelos são interessantes e empolgantes porque podem ser executados em velocidades relativamente altas (> 40 tokens por segundo) em computadores sem GPUs, dando a mais pessoas acesso a esses modelos sem quebrar o banco.
Novo Modelo de Código Aberto BFL
Black Forest Labs fez parceria com Krea para criar um novo modelo de geração de imagens de código aberto, chamado Flux Krea dev. O modelo está focado em se livrar da sensação de IA que muitos geradores de imagens têm, e também em permitir estéticas únicas semelhantes ao Midjourney. Eles também se concentraram em ter realismo excepcional e qualidade de imagem. O modelo usa a mesma arquitetura que o modelo Flux dev original, tornando-o compatível com todos os frameworks de geração de imagens prontos para uso.
Comparação Flux schnell vs flux krea - de fruesome no reddit
Rodada Rápida
Ferramentas ou tópicos úteis que encontrei esta semana que podem ou não estar relacionados a IA, mas não tive tempo de escrever uma seção completa sobre.
Cerebras Code
A Cerebras está lançando seu próprio concorrente de hospedagem de modelo Claude Code, oferecendo o modelo Qwen3 coder por $50 por mês enquanto também é 20 vezes mais rápido. Qwen3 coder, infelizmente, não parece ser um modelo de programação agêntica tão bom, especialmente quando comparado ao novo modelo GLM 4.5 que acabou de sair. Se a Cerebras começar a oferecer o modelo GLM 4.5, vou imediatamente adquirir isso, pois as velocidades são quase instantâneas para geração de texto.
Gemini Deep Think
O Google lançou uma versão atualizada de seu modelo Gemini 2.5 Pro chamada Gemini 2.5 DeepThink, que é baseada no modelo que recentemente ganhou uma medalha de ouro na Olimpíada Internacional de Matemática. Eles escalaram a computação em tempo de teste permitindo que o Gemini pense por mais tempo, e também em paralelo, e então seja capaz de selecionar as melhores opções depois de ir e explorar um monte de escolhas diferentes que ele poderia potencialmente fazer.
Ele tem benchmarks muito bons em avaliações públicas e privadas, superando até mesmo o modelo Grok 4 overfit da XAi. Se você quiser usá-lo, está disponível através do nível de assinatura AI-Ultra do Google. E eles dizem que deve sair na API do Gemini nas próximas semanas.
Modo de estudo ChatGPT
A OpenAI lançou um modo de estudo para usar para aprender novos assuntos.
Os usuários rapidamente descobriram que por baixo dos panos, é apenas um prompt, tornando assim a OpenAI um wrapper do ChatGPT. Além disso, você pode ter o modo de estudo em casa (ou com qualquer outro LLM) apenas copiando o prompt do sistema deles.
Trackio
Weights and Biases é a biblioteca mais usada para rastrear experimentos de aprendizado de máquina, e é uma bagunça cheia de bugs, mas não houve boas alternativas que os pesquisadores pudessem usar. Até agora. Nossos salvadores na Huggingface lançaram uma biblioteca chamada Trackio, que é uma versão local de código aberto do Weights and Biases que você pode usar para rastrear seus experimentos. É destinado como uma substituição direta, então você não deve precisar atualizar nenhum do seu código de logging.
Apenas atualize seu código para usar import trackio as wandb e seu projeto estará livre do inferno que é o W&B para sempre.
VibeKit Auth
Não seria legal se as pessoas pudessem usar sua assinatura ChatGPT ou Claude Pro no seu app? Agora você pode, usando uma nova biblioteca chamada VibeKit.
Exploração do Tokenizador Claude
O tokenizador do Claude é estranho, Sasuke_420 no Twitter explica o quão estranho ele realmente é.
Biblioteca de fine-tuning MoE
Fazer fine-tuning de modelos mixture of experts é notoriamente difícil, então a equipe da Character AI lançou um treinador testado em batalha escrito em PyTorch puro para ajudar a comunidade a fazer fine-tune desses modelos mais facilmente.
Use o agente ChatGPT para encontrar códigos de cupom
Agradeça-me depois, o que você pode fazer assinando a newsletter (link abaixo).
Finalização
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Campeonato de Vôlei de Girafas 2022 - de remi no twitter
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
Anthropic supera a OpenAI en ingresos por API
Un informe reciente de Menlo Ventures ha mostrado que Anthropic ha superado recientemente a OpenAI en términos de ingresos por API de LLM, capturando más del 30% del mercado frente al 25% de OpenAI. También tienen un liderazgo aún más dominante en cuota de mercado de codificación, capturando el 42% del mercado. Esto viene después de la explosión en el uso de Cursor y Claude Code en el último año, ya que Anthropic se ha convertido en el estándar de facto para aplicaciones agénticas del mundo real.
Además, como parte del informe, mostraron que solo el 11% de las empresas están usando modelos de código abierto en escenarios de alto uso, y alrededor del 50% de ellas no están usando modelos de código abierto en absoluto, ni siquiera para experimentación o tareas más pequeñas. Esto se debe a los altos costos de ejecutar o hacer fine-tuning de tu propio modelo versus optimizar un prompt de sistema para un modelo de código cerrado, especialmente con los mejores modelos cambiando cada semana. Espero que este número suba en el futuro si el progreso de la IA comienza a estancarse, o baje a 0 si alguien logra AGI.
Lanzamientos
Z.ai toma la delantera
He estado promocionando Z.ai las últimas semanas, y no han decepcionado. Esta semana han lanzado su serie GLM 4.5 de modelos, que por lo que he visto, son los mejores modelos agénticos de código abierto en el mercado en este momento.
Han lanzado 2 variantes, 4.5 y 4.5 Air. Ambos son modelos MoE, con 4.5 teniendo 355 mil millones de parámetros totales y 32 mil millones de parámetros activos, y Air teniendo 106 mil millones de parámetros con 12 mil millones activos. Lo que esto significa es que 4.5 necesita una configuración adecuada de múltiples GPU (H100 o mejor) para ejecutarse a velocidades significativas, mientras que el modelo Air podría ejecutarse de manera factible en casa con una configuración combinada de CPU + GPU usando algo como Ktransformers.
¿Pero por qué querrías usar estos modelos? Simplemente, porque son increíbles.
Los GLM 4.5 compiten mano a mano con los modelos Claude 4 y la serie o de OpenAI
Los benchmarks públicos son una cosa, pero ¿realmente pasan la prueba en el mundo real? Por supuesto que sí.
Cuando es evaluado por humanos, GLM 4.5 iguala a Sonnet en codificación agéntica, el primer modelo que he visto hacerlo
No tienes que creer solo en la palabra de otras personas. He cambiado a usar GLM 4.5 en Claude Code, y no he notado ninguna diferencia práctica, aparte de que el costo es 5 veces menor. Reddit también está de acuerdo, con usuarios comparando el modelo Air con el nuevo modelo Qwen3 235B que se lanzó la semana pasada, mientras es 2 veces más pequeño, y otros también están de acuerdo conmigo en que el modelo grande es similar a Sonnet/Opus para tareas agénticas y de codificación.
Planeo ejecutar el modelo Air como mi modelo local principal del día a día, probablemente tomando el rol que uso o3 para tareas diarias. También probablemente me quedaré con los modelos grandes 4.5 también para mis flujos de trabajo de codificación en el futuro previsible.
Si aún no te has dado cuenta, estos modelos superan a los anteriores mejores modelos de Kimi K2 y Qwen3 por una cantidad considerable, todo mientras son más pequeños y rápidos que ellos.
Puedes probar ambos modelos gratis ahora mismo en z.ai.
Wan 2.2
Alibaba ha mejorado su modelo de video de código abierto SOTA, Wan 2.1, lanzando su serie Wan 2.2 de modelos. Hay 2 modelos que lanzaron, un modelo “estándar” de 5 mil millones de parámetros que puede hacer texto e imagen a video, y luego también 2 modelos MoE con 28 mil millones de parámetros con 14B activos, uno para texto a video y el otro para imagen a video.
Los modelos MoE son interesantes ya que tienen 2 expertos, uno para eliminación de ruido de alto nivel para la parte temprana del proceso de generación, y otro para eliminación de ruido de bajo nivel más tarde para pasos posteriores. Creo que esto terminará siendo similar al refinador SDXL, donde la comunidad encuentra una manera de deshacerse de él y unificar el modelo para no necesitar tantos pasos y parámetros para que funcione igual de bien.
Por lo que he visto hasta ahora, los modelos funcionan bien, definitivamente no es SOTA cuando se compara con modelos de código cerrado como Veo3, pero sigue siendo un gran salto en calidad versus el anterior mejor, Wan 2.1.
Un auto deportivo rosa está conduciendo muy rápido por una playa al atardecer, el auto dice “REPLICATE” en el costado, derrapa en la arena - De fofr en Twitter
Actualización de Qwen3-30B-3A
Qwen lanzó 3 modelos la semana pasada, y deben haber disfrutado realmente toda la atención que eso les trajo, porque hicieron lo mismo esta semana, lanzando 3 nuevas versiones de su modelo MoE Qwen3 30B3A.
Los primeros 2 son las variantes básicas de razonamiento y sin razonamiento, ambas comparables a Gemini 2.5 Flash.
Benchmarks del modelo sin pensamiento
El tercer modelo que lanzaron en la serie es un modelo de codificación agéntica, que, aunque no es tan impresionante cuando se compara con GLM 4.5 y Sonnet, tiene la distinción de ser el primer modelo “pequeño” de código abierto que es capaz de hacer codificación agéntica en absoluto, una tarea que ha eludido al código abierto por un tiempo.
Benchmarks del modelo de codificación
Estos modelos son interesantes y emocionantes porque pueden ejecutarse a velocidades relativamente altas (> 40 tokens por segundo) en computadoras sin GPU, dando a más personas acceso a estos modelos sin quebrar el banco.
Nuevo Modelo de Código Abierto de BFL
Black Forest Labs se ha asociado con Krea para hacer un nuevo modelo de generación de imágenes de código abierto, llamado Flux Krea dev. El modelo se enfoca en deshacerse de la sensación de IA que muchos generadores de imágenes tienen, y también permite estéticas únicas similares a Midjourney. También se han enfocado en tener un realismo excepcional y calidad de imagen. El modelo usa la misma arquitectura que el modelo original Flux dev, haciéndolo compatible con todos los frameworks de generación de imágenes desde el principio.
Comparación de Flux schnell vs flux krea - de fruesome en reddit
Ronda Rápida
Herramientas o temas útiles que encontré esta semana que pueden o no estar relacionados con IA, pero no tuve tiempo de escribir una sección completa.
Cerebras Code
Cerebras está lanzando su propio competidor de alojamiento de modelos Claude Code, ofreciendo el modelo codificador Qwen3 por $50 al mes mientras también es 20 veces más rápido. El codificador Qwen3, tristemente, no parece ser un modelo de codificación agéntica tan bueno, especialmente cuando se compara con el nuevo modelo GLM 4.5 que acaba de salir. Sin embargo, si Cerebras comienza a ofrecer el modelo GLM 4.5, inmediatamente voy a adquirir esto, ya que las velocidades son casi instantáneas para la generación de texto.
Gemini Deep Think
Google ha lanzado una versión mejorada de su modelo Gemini 2.5 Pro llamada Gemini 2.5 DeepThink, que se basa en el modelo que recientemente obtuvo una medalla de oro en la Olimpiada Internacional de Matemáticas. Han escalado el cómputo en tiempo de prueba al permitir que Gemini piense por más tiempo, y también en paralelo, y luego poder seleccionar las mejores opciones después de ir y explorar un montón de diferentes opciones que potencialmente podría tomar.
Obtiene muy buenos resultados en evaluaciones públicas y privadas, superando incluso al modelo sobreajustado Grok 4 de XAi. Si deseas usarlo, está disponible a través del nivel de suscripción AI-Ultra de Google. Y dicen que debería salir en la API de Gemini en las próximas semanas.
Modo de estudio de ChatGPT
OpenAI ha lanzado un modo de estudio para usar para aprender nuevas materias.
Los usuarios descubrieron rápidamente que bajo el capó, es solo un prompt, convirtiendo así a OpenAI en un wrapper de ChatGPT. También puedes tener el modo de estudio en casa (o con cualquier otro LLM) simplemente copiando su prompt de sistema.
Trackio
Weights and Biases es la biblioteca más utilizada para rastrear experimentos de aprendizaje automático, y es un desastre lleno de bugs, pero no ha habido buenas alternativas que los investigadores pudieran usar. Hasta ahora. Nuestros salvadores en Huggingface han lanzado una biblioteca llamada Trackio, que es una versión de código abierto y local de Weights and Biases que puedes usar para rastrear tus experimentos. Está diseñada como un reemplazo directo, por lo que no deberías necesitar actualizar ninguno de tu código de registro en absoluto.
Solo actualiza tu código para usar import trackio as wandb y tu proyecto estará libre del infierno que es W&B para siempre.
VibeKit Auth
¿No sería genial si las personas pudieran usar su suscripción a ChatGPT o Claude Pro en tu aplicación? Ahora puedes, usando una nueva biblioteca llamada VibeKit.
Exploración del Tokenizador de Claude
El tokenizador de Claude es extraño, Sasuke_420 en Twitter explica qué tan extraño realmente es.
Biblioteca de fine-tuning MoE
Hacer fine-tuning de modelos de mezcla de expertos es notoriamente difícil, por lo que el equipo de Character AI ha lanzado un entrenador probado en batalla escrito en PyTorch puro para ayudar a la comunidad a hacer fine-tuning de estos modelos más fácilmente.
Usa el agente de ChatGPT para encontrar códigos de cupón
Agradéceme más tarde, lo cual puedes hacer suscribiéndote al boletín (enlace abajo).
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Campeonato de Voleibol de Jirafas 2022 - de remi en twitter