Quick Hits
This was one of the quietest weeks of the year due to the holidays, so there is no major news or releases to be highlighted.
Post train bench
How good are LLM’s at finetuning other LLM’s?
That is what a group of researchers wanted to find out, so they made PostTrainBench, which measures how well model’s can finetune small LLMs do do better on some common benchmarks. They then compare the LLM’s results to a human finetuned baseline.
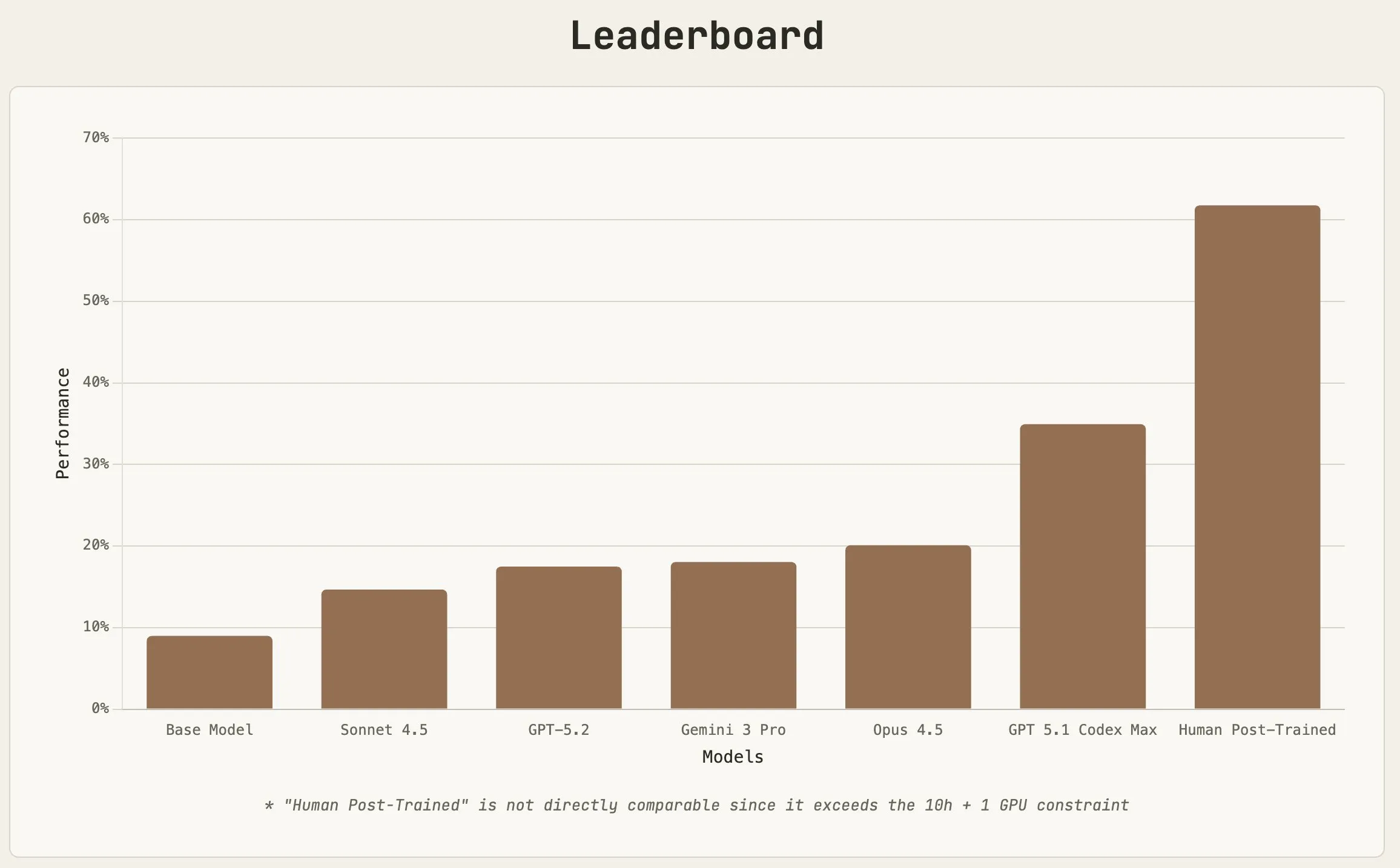
For the benchmark, there are 4 models that must be finetuned for a particular benchmark, and the LLM’s are given 10 hours on an H100 to get it done.
All of the models being evaluated used their native harnesses (ie Claude Code, Codex, or the Gemini CLI).
The time was not a bottleneck for the models, as all of them finished before the 10 hours was used up.
The quality of the trained models was mostly to do with data curation, which GPT 5.1 was able to do the best.
I was surprised how well the models were able to do, and that they were all able to get an increase in score versus the base model. GPT 5.2 is a step up from 5.1 as well, so my guess is that the difference between humans and models is even less than what is shown.
Qwen Image 2512
Continuing the refresh of their image models, the Qwen team has released a update for their Qwen Image model.
The Qwen Image model has fallen behind its open source competitors in Z Image (which is also from Alibaba) and Flux 2, and this release puts it in the same ballpark as those in terms of quality.
I would still recommend using Z Image, as it has similar quality while being faster and cheaper. Compared to Flux 2, it is smaller, and has better community support since all of the existing loras made for the previous should still work with this refreshed model.
Claude as your on call engineer
Monitoring and fixing deployment issues will quite literally keep you up at night.
But what if they didn’t?
Denislav Gavrilov had the idea of attaching Claude to the logs of his deployment cluster, and have it diagnose and hot fix any issues that came about, effectively making a 24/7 on-call engineer.
I personally would use GPT 5.2, as it has much better bug hunting ability, especially for more difficult issues, but the idea is still good nonetheless.
I think we will be seeing a lot more of this LLM “self healing” in future. Imagine that as you are testing your app and you run into a http 500 error, your coding agent sees this and immediately fixes it for you instead of you needing to copy the error or describe the issue to it.
I can also see this being used for web scraping tasks. Websites often change and break your information retrieval scripts, so if you detect a break or deviation in the site’s content, have an LLM immediately be fired up to go and investigate what changed and how to fix it. This will allow LLM’s to be able to proactively work for you with zero input needed from the user, freeing you up to do more productive and proactive tasks versus needing to maintain existing projects and infrastructure.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

A Louisiana snowman by Travis Chapman Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Destaques Rápidos
Esta foi uma das semanas mais tranquilas do ano devido aos feriados, então não há grandes notícias ou lançamentos para destacar.
Post train bench
Quão bons são os LLMs em fazer fine-tuning de outros LLMs?
Isso é o que um grupo de pesquisadores queria descobrir, então eles criaram o PostTrainBench, que mede quão bem os modelos conseguem fazer fine-tuning de pequenos LLMs para se saírem melhor em alguns benchmarks comuns. Eles então comparam os resultados dos LLMs com uma linha de base de fine-tuning feito por humanos.
Para o benchmark, existem 4 modelos que devem passar por fine-tuning para um benchmark específico, e os LLMs recebem 10 horas em um H100 para concluir a tarefa.
Todos os modelos sendo avaliados usaram seus harnesses nativos (ou seja, Claude Code, Codex, ou Gemini CLI).
O tempo não foi um gargalo para os modelos, já que todos terminaram antes das 10 horas se esgotarem.
A qualidade dos modelos treinados foi principalmente relacionada à curadoria de dados, na qual o GPT 5.1 conseguiu fazer melhor.
Fiquei surpreso com o quão bem os modelos conseguiram se sair, e que todos conseguiram obter um aumento na pontuação versus o modelo base. O GPT 5.2 está um passo à frente do 5.1 também, então meu palpite é que a diferença entre humanos e modelos é ainda menor do que o mostrado.
Qwen Image 2512
Continuando a atualização de seus modelos de imagem, a equipe Qwen lançou uma atualização para seu modelo Qwen Image.
O modelo Qwen Image ficou para trás de seus concorrentes de código aberto no Z Image (que também é da Alibaba) e Flux 2, e este lançamento o coloca no mesmo patamar desses em termos de qualidade.
Eu ainda recomendaria usar o Z Image, já que ele tem qualidade similar sendo mais rápido e mais barato. Comparado ao Flux 2, ele é menor, e tem melhor suporte da comunidade já que todos os loras existentes feitos para a versão anterior ainda devem funcionar com este modelo atualizado.
Claude como seu engenheiro de plantão
Monitorar e corrigir problemas de implantação literalmente pode te manter acordado à noite.
Mas e se isso não acontecesse?
Denislav Gavrilov teve a ideia de conectar o Claude aos logs de seu cluster de implantação, e fazer com que ele diagnostique e corrija rapidamente quaisquer problemas que surjam, efetivamente criando um engenheiro de plantão 24/7.
Eu pessoalmente usaria o GPT 5.2, já que ele tem uma capacidade muito melhor de caçar bugs, especialmente para problemas mais difíceis, mas a ideia ainda é boa de qualquer forma.
Acho que veremos muito mais dessa “auto-cura” de LLM no futuro. Imagine que enquanto você está testando seu aplicativo e encontra um erro http 500, seu agente de codificação vê isso e imediatamente corrige para você em vez de você precisar copiar o erro ou descrever o problema para ele.
Também posso ver isso sendo usado para tarefas de web scraping. Sites frequentemente mudam e quebram seus scripts de recuperação de informação, então se você detectar uma quebra ou desvio no conteúdo do site, faça com que um LLM seja imediatamente acionado para ir e investigar o que mudou e como corrigir. Isso permitirá que os LLMs sejam capazes de trabalhar proativamente para você com zero entrada necessária do usuário, liberando você para fazer tarefas mais produtivas e proativas em vez de precisar manter projetos e infraestrutura existentes.
Finalização
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, não deixe de se inscrever na nossa lista de e-mails abaixo.
Um boneco de neve da Louisiana por Travis Chapman Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Temas Destacados
Esta fue una de las semanas más tranquilas del año debido a las festividades, por lo que no hay noticias importantes o lanzamientos destacados.
Post train bench
¿Qué tan buenos son los LLM para hacer fine-tuning de otros LLM?
Eso es lo que un grupo de investigadores quería descubrir, así que crearon PostTrainBench, que mide qué tan bien los modelos pueden hacer fine-tuning de LLM pequeños para mejorar en algunos benchmarks comunes. Luego comparan los resultados de los LLM con una línea base de fine-tuning hecho por humanos.
Para el benchmark, hay 4 modelos a los que se les debe hacer fine-tuning para un benchmark en particular, y a los LLM se les dan 10 horas en un H100 para completarlo.
Todos los modelos evaluados utilizaron sus herramientas nativas (es decir, Claude Code, Codex, o el CLI de Gemini).
El tiempo no fue un cuello de botella para los modelos, ya que todos terminaron antes de que se agotaran las 10 horas.
La calidad de los modelos entrenados tuvo que ver principalmente con la curación de datos, lo cual GPT 5.1 pudo hacer mejor.
Me sorprendió lo bien que los modelos fueron capaces de hacerlo, y que todos pudieran obtener un aumento en la puntuación en comparación con el modelo base. GPT 5.2 es un paso adelante respecto a 5.1 también, así que mi suposición es que la diferencia entre humanos y modelos es incluso menor de lo que se muestra.
Qwen Image 2512
Continuando con la renovación de sus modelos de imagen, el equipo de Qwen ha lanzado una actualización para su modelo Qwen Image.
El modelo Qwen Image se ha quedado atrás de sus competidores de código abierto en Z Image (que también es de Alibaba) y Flux 2, y este lanzamiento lo coloca en la misma liga que esos en términos de calidad.
Aún recomendaría usar Z Image, ya que tiene una calidad similar mientras es más rápido y económico. En comparación con Flux 2, es más pequeño y tiene mejor soporte de la comunidad ya que todos los loras existentes hechos para el modelo anterior deberían seguir funcionando con este modelo actualizado.
Claude como tu ingeniero de guardia
El monitoreo y la corrección de problemas de despliegue literalmente te mantendrán despierto por la noche.
¿Pero qué pasaría si no lo hicieran?
Denislav Gavrilov tuvo la idea de conectar Claude a los registros de su clúster de despliegue, y hacer que diagnostique y corrija en caliente cualquier problema que surja, creando efectivamente un ingeniero de guardia 24/7.
Personalmente usaría GPT 5.2, ya que tiene una capacidad mucho mejor de búsqueda de errores, especialmente para problemas más difíciles, pero la idea es buena de todos modos.
Creo que veremos mucho más de esta “autocuración” de LLM en el futuro. Imagina que mientras estás probando tu aplicación y te encuentras con un error http 500, tu agente de codificación ve esto y lo arregla inmediatamente para ti en lugar de que necesites copiar el error o describirle el problema.
También puedo ver esto siendo usado para tareas de web scraping. Los sitios web a menudo cambian y rompen tus scripts de recuperación de información, así que si detectas una ruptura o desviación en el contenido del sitio, haz que un LLM se active inmediatamente para ir e investigar qué cambió y cómo arreglarlo. Esto permitirá que los LLM puedan trabajar de forma proactiva para ti sin necesidad de ninguna intervención del usuario, liberándote para hacer tareas más productivas y proactivas en lugar de necesitar mantener proyectos e infraestructura existentes.
Fin
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Un muñeco de nieve de Louisiana por Travis Chapman