Releases
Mistral 3
The EU’s largest LLM trainer, Mistral is back after another sizable hiatus, releasing 4 new models this week.
The models range in size, with 3 dense models named Ministral 3 with 3B, 8B, and 14B parameters, and then Mistral Large 3, which is a 675B MoE model with 41B active parameters, making it one of the largest frontier open source models right now, only behind Kimi K2’s one trillion parameters.
The Ministral models all come in base, instruct, and reasoning variants, which the Large model is only instruct for now, but they say they will release a reasoning variant in the future.
They also all come with multimodal vision capabilities, but they are not very good at vision tasks, which is highlighted by the fact they did not even bother to release any vision benchmarks.

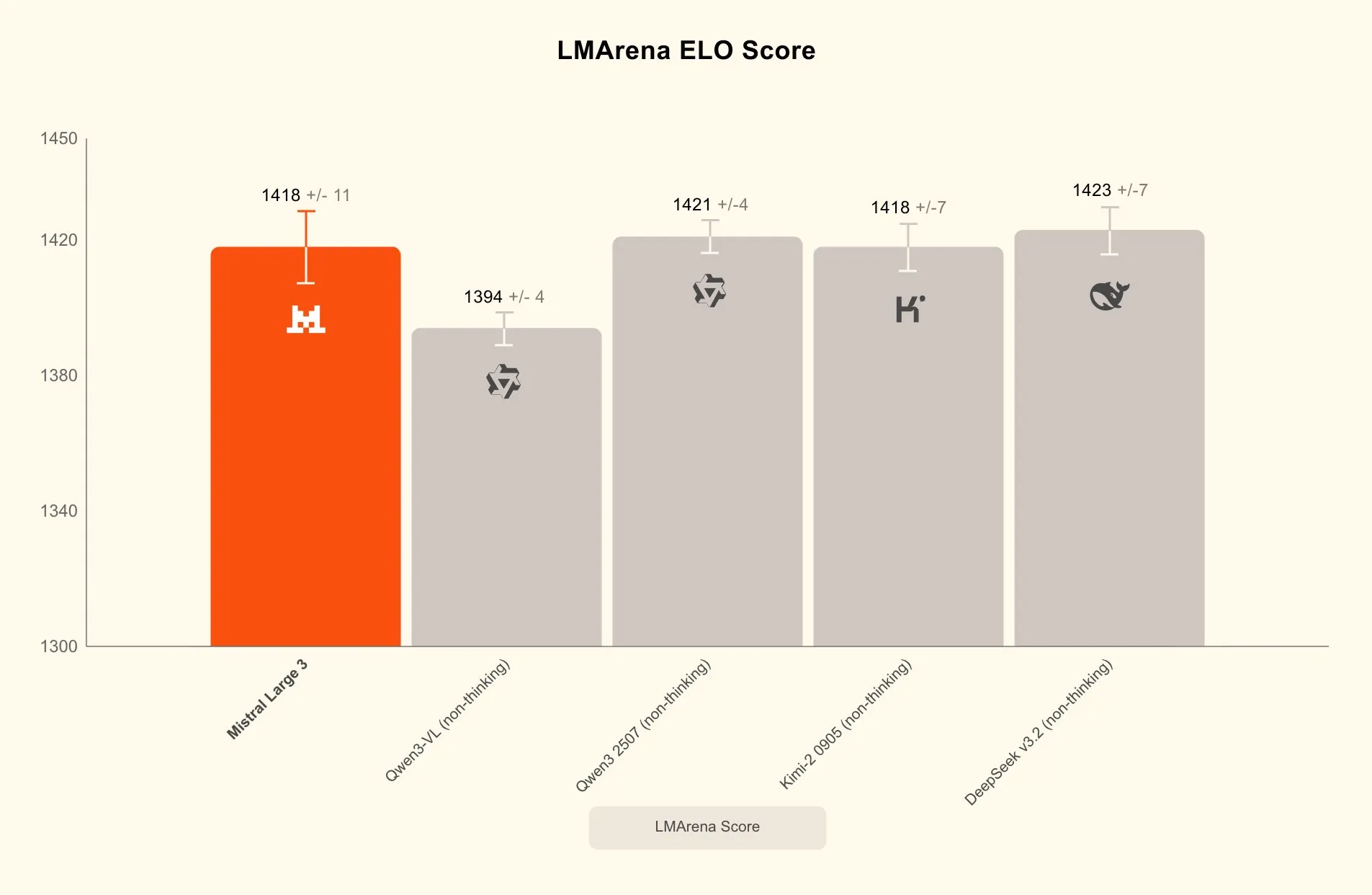
LMArena score, basically how friendly and sycophantic the model is
The general sentiment from people using these models is almost universally negative from what I have seen, with almost everyone saying that the models perform worse than any of their similarly sized counterparts across every task type.
One very glaring fault of the models is their very poor agentic performance, which is one of the main uses of LLM’s today.
My guess is that Mistral is not training on synthetic tool calling and coding data (called mid-training), which really helps the models with reasoning, tool use, and agentic tasks.
Because of this, I would advise you to not use any of the Mistral models at this point, since there are universally better options out there to use instead.
Based on these models, I would say the Mistral is a bit behind the curve right now, and will need to play some catch up if they want to remain relevant in the current AI ecosystem.
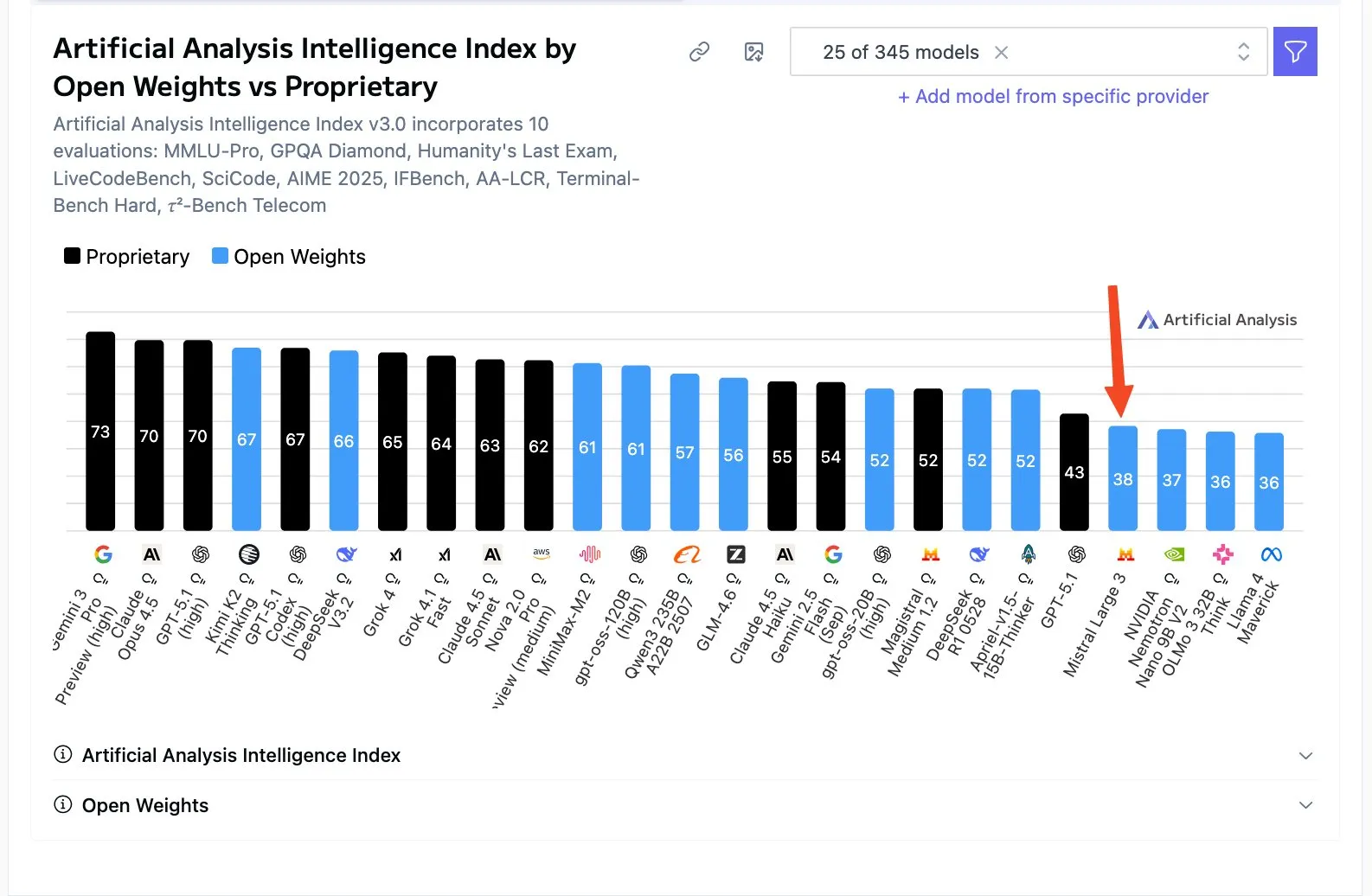
On Artificial Analysis’s LLM benchmark, Mistral Large (600B parameters) scored similarly to Qwen3 30B, which is frankly abysmal
Kling O1
We have many image editing models and also video generation models. But there has been a surprising lack of video editing models. A surprising lack of video editing models that have been released, with Wan VACE and Runway Aleph being the only models in the video editing space.
We now have a new entrant in this sparsely populated space, with the release of Kling O1.
The Kling team has somewhat quietly been improving their video generation models, with their current flagship Kling 2.5 Turbo being in the top 3 for text to video and the best for image to video according to Artificial Analysis.
Their O1 model does a good job maintaining the characteristics of the original reference video, and can fill in the gaps fairly well for anything that may be missing in the image (like removing objects from a video). For video editing, it seems to be the best model out there right now.
Prompt: Remove the train — from Nucleus on Twitter
Another example from a thread on Twitter
Comparison across multiple video editing models
Pricing is $0.17 per second of video edited (pricing gotten from Fal).
The model should be available wherever you get your video generation models, including Replicate and Fal, or also directly on the Kling AI website.
Arcee Trinity Models
Arcee AI, an American lab that has had many open source contributions in the past, has released their trained from scratch Trinity family of models in partnership with Datology.
They have released 2 models, a 8 billion parameter MoE model with 1 billion active parameters called Trinity Nano, and a 26 billion parameter model with 3 billion active parameters called Trinity Mini.
They also will release Trinity Large, which is a 420B parameter model with 13B active, in January.
The Nano model is only a preview release, and has no benchmarks on it that Arcee or anyone else has released. Arcee says that it will have an updated version and exit preview status when the Large model is released.
Given its size and architecture I expect it to compete with the Liquid 8B MoE model we covered a while ago.
It is also an instruct (non-reasoning) model which means that its response times should also be very fast.
The Mini model seems to be more polished, being a reasoning model that is competitive with the Qwen 30B MoE model.
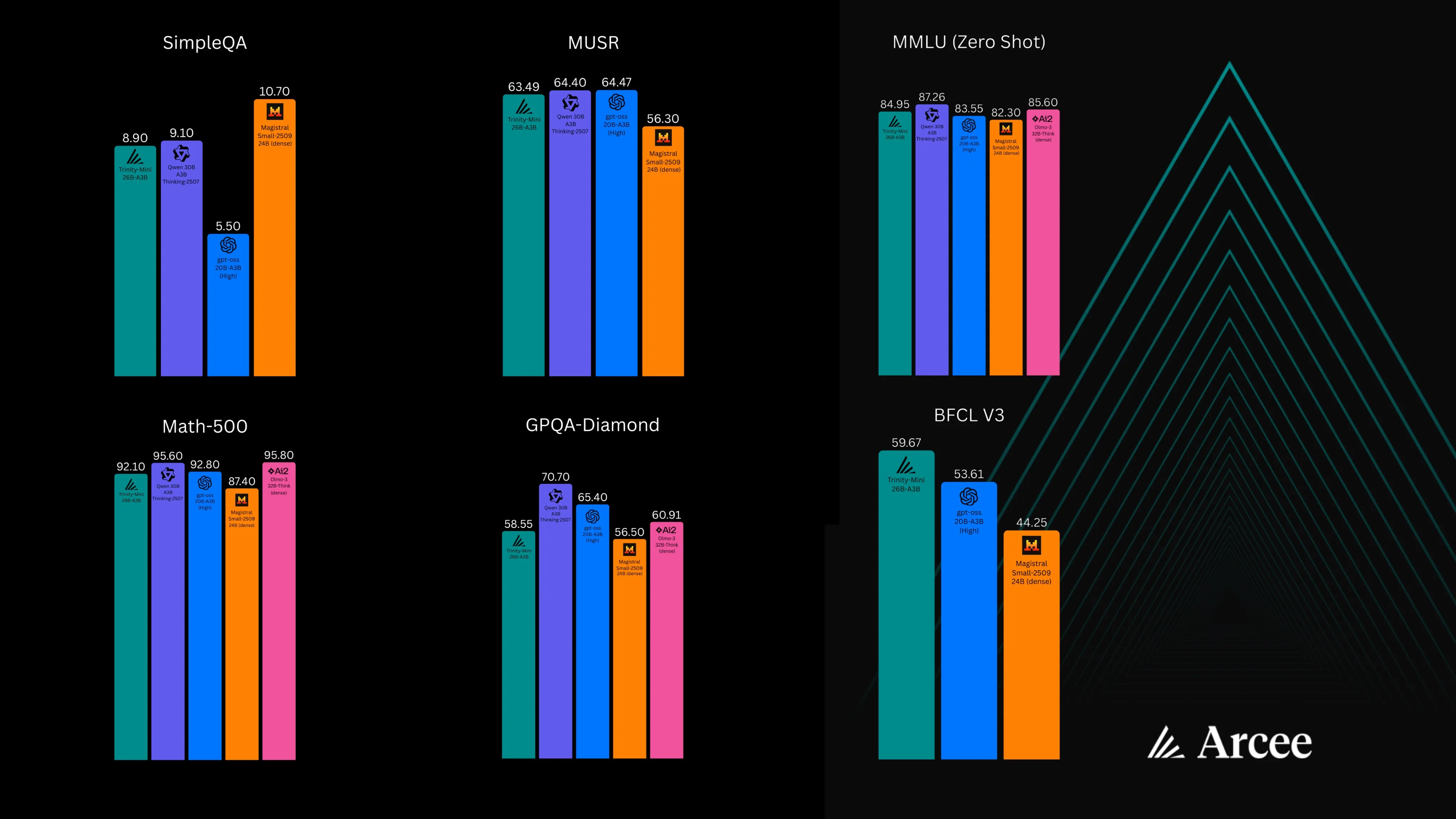
Teal: Arcee Mini; purple: Qwen 3 30B; blue: gpt-oss 20B; orange: Mistral Small; pink: Olmo 3 32B
The model passed my preliminary vibe check, and also Arcee has made models previous that are stronger than the benchmarks entail (because they do not benchmaxx) so expect this model to punch a bit above where the benchmarks put it.
I would recommend reading their initial report they published to learn more about the models and how they were able to train them in only 6 months.
I am excited to see more from this team and will definitely be keeping an eye on them in the future to see what they release.
Rnj-1
Another American AI lab, Essential AI has released their first model, a dense 8B parameter instruct model called Rnj-1.
The company is young, but its founders have been in the AI space for a while, as their team is headed by Ashish Vaswani, who is the first author on the Attention is All You Need paper, which introduced the transformer architecture LLMs use today.
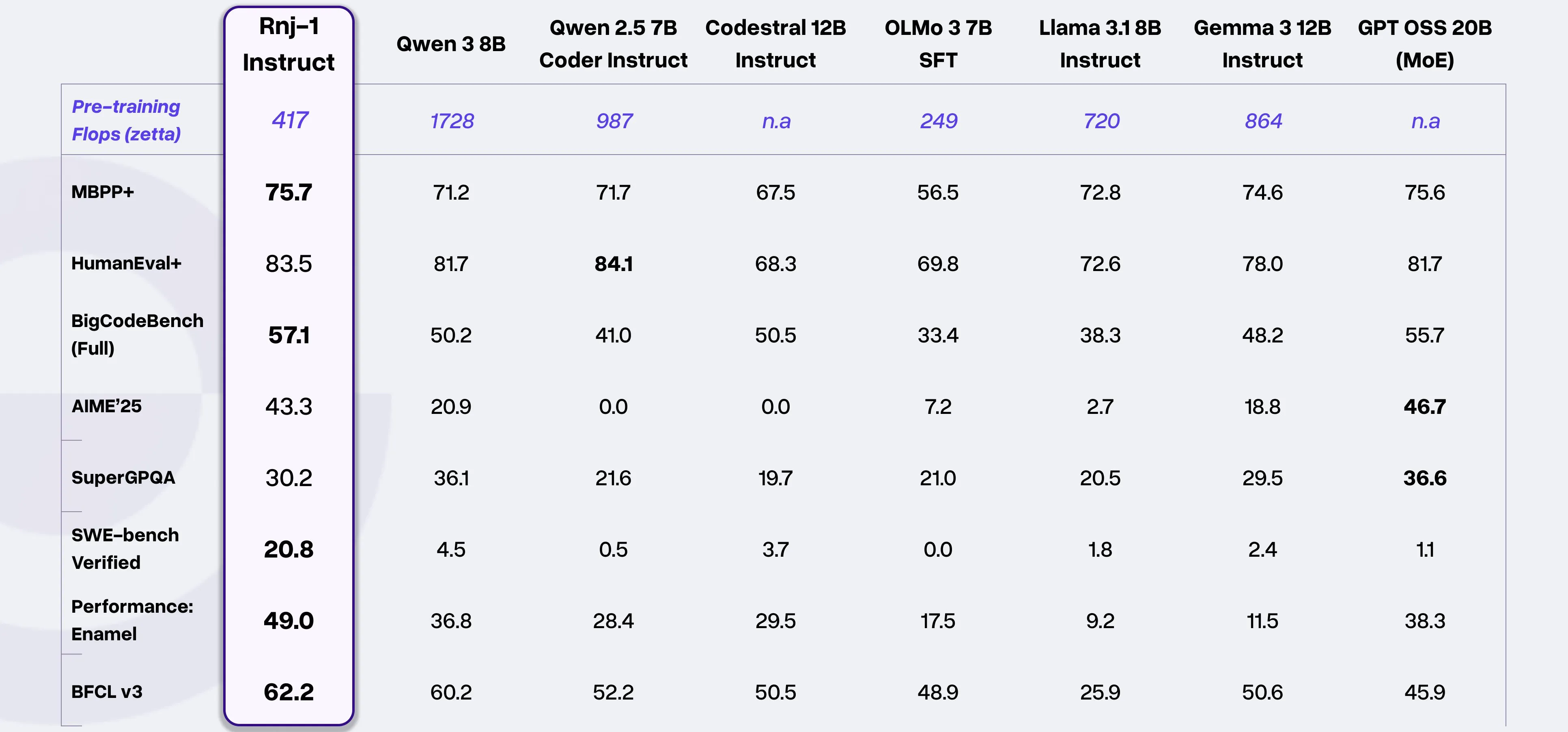
Impressive scores, especially when taking training FLOPs into account
The model was trained with a specific focus on tool use and coding performance, which is why they benchmark it on those tasks specifically.
It does well on these despite having no reinforcement learning done to it and only a small supervised finetuning pass.
This either means the team is on to something big, or they are overfitting on benchmarks.
I have yet to try it myself since it came out less than a day ago at the time of writing, so we will have to wait and see.
Either way, similar to the Arcee team, I am excited to see where this team goes in the future.
Runway 4.5
There is a new top text to video model, that being Runway 4.5.
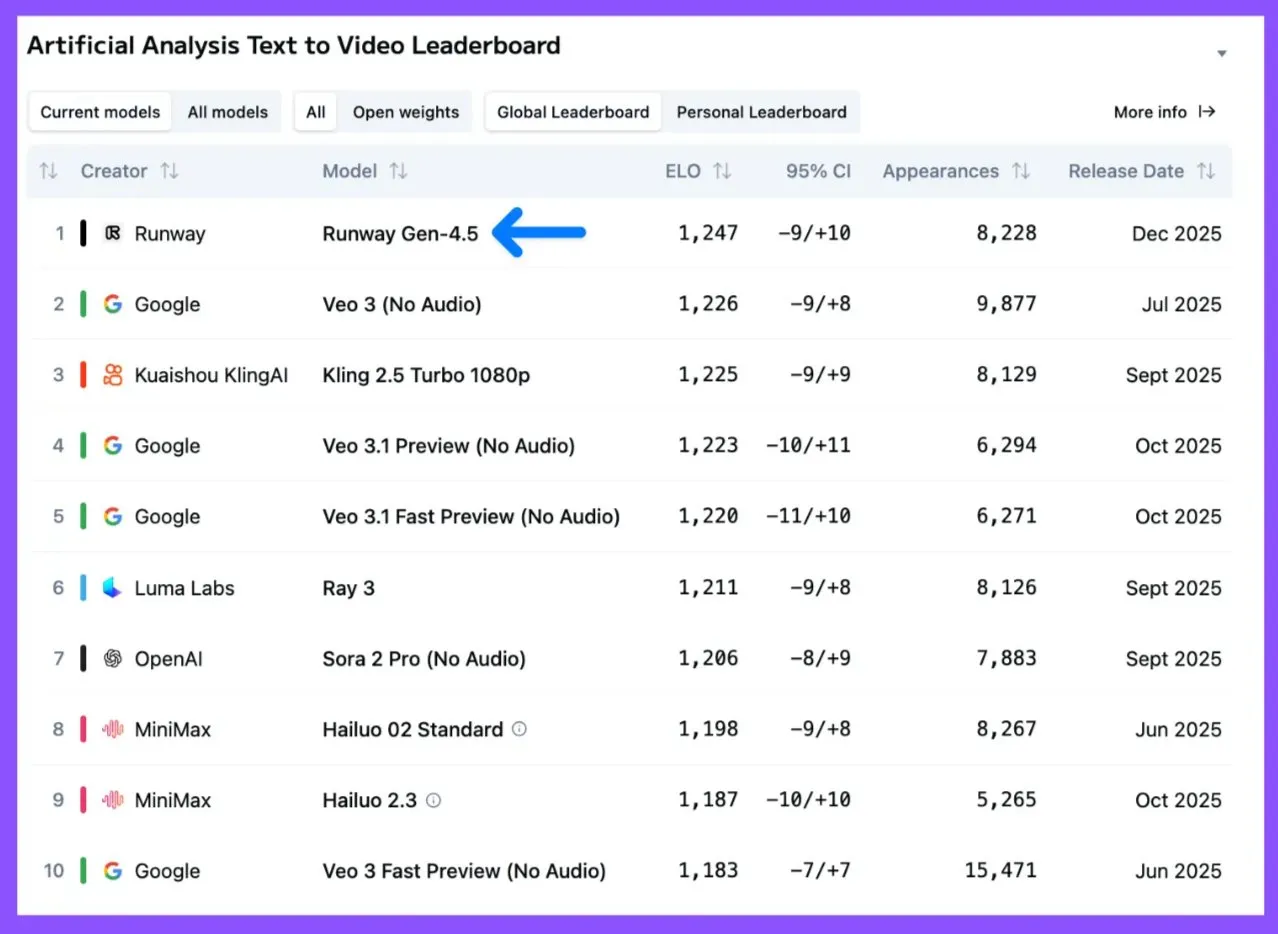
Scores from Artificial Analysis
The Runway team is rolling out access over the coming days/weeks on their platform, which appears to be the only way to use the model.
Some samples from the Runway Team
No real step change in terms of capabilities versus other models, just another incremental improvement in the video generation space.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Claude-inspired style in Midjourney — from Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Mistral 3
A maior treinadora de LLM da UE, Mistral está de volta após outro hiato considerável, lançando 4 novos modelos esta semana.
Os modelos variam em tamanho, com 3 modelos densos chamados Ministral 3 com 3B, 8B e 14B parâmetros, e depois Mistral Large 3, que é um modelo MoE de 675B com 41B parâmetros ativos, tornando-o um dos maiores modelos de código aberto de fronteira atualmente, ficando atrás apenas do Kimi K2 com um trilhão de parâmetros.
Os modelos Ministral vêm todos nas variantes base, instruct e reasoning, enquanto o modelo Large é apenas instruct por enquanto, mas eles dizem que lançarão uma variante reasoning no futuro.
Todos eles também vêm com capacidades de visão multimodal, mas não são muito bons em tarefas de visão, o que é destacado pelo fato de que eles nem sequer se deram ao trabalho de lançar benchmarks de visão.
Pontuação LMArena, basicamente quão amigável e bajulador o modelo é
O sentimento geral das pessoas usando esses modelos é quase universalmente negativo pelo que tenho visto, com quase todos dizendo que os modelos têm desempenho pior do que qualquer um de seus equivalentes de tamanho similar em todos os tipos de tarefas.
Uma falha muito gritante dos modelos é seu desempenho agêntico muito fraco, que é um dos principais usos dos LLMs hoje.
Meu palpite é que a Mistral não está treinando com dados sintéticos de chamadas de ferramentas e codificação (chamado mid-training), o que realmente ajuda os modelos com raciocínio, uso de ferramentas e tarefas agênticas.
Por causa disso, eu aconselharia você a não usar nenhum dos modelos Mistral neste momento, já que existem opções universalmente melhores disponíveis para usar.
Com base nesses modelos, eu diria que a Mistral está um pouco atrás da curva agora, e precisará fazer alguma recuperação se quiser permanecer relevante no ecossistema de IA atual.
No benchmark de LLM da Artificial Analysis, Mistral Large (600B parâmetros) pontuou similarmente ao Qwen3 30B, o que é francamente abismal
Kling O1
Temos muitos modelos de edição de imagem e também modelos de geração de vídeo. Mas houve uma surpreendente falta de modelos de edição de vídeo. Uma surpreendente falta de modelos de edição de vídeo que foram lançados, com Wan VACE e Runway Aleph sendo os únicos modelos no espaço de edição de vídeo.
Agora temos um novo concorrente neste espaço escassamente populado, com o lançamento do Kling O1.
A equipe Kling tem melhorado seus modelos de geração de vídeo de forma um tanto silenciosa, com seu atual carro-chefe Kling 2.5 Turbo estando no top 3 para texto para vídeo e sendo o melhor para imagem para vídeo de acordo com a Artificial Analysis.
Seu modelo O1 faz um bom trabalho mantendo as características do vídeo de referência original, e pode preencher as lacunas razoavelmente bem para qualquer coisa que possa estar faltando na imagem (como remover objetos de um vídeo). Para edição de vídeo, parece ser o melhor modelo disponível agora.
Prompt: Remova o trem — de Nucleus no Twitter
Outro exemplo de uma thread no Twitter
Comparação entre vários modelos de edição de vídeo
O preço é $0.17 por segundo de vídeo editado (preço obtido da Fal).
O modelo deve estar disponível onde quer que você obtenha seus modelos de geração de vídeo, incluindo Replicate e Fal, ou também diretamente no site Kling AI.
Modelos Arcee Trinity
Arcee AI, um laboratório americano que teve muitas contribuições de código aberto no passado, lançou sua família de modelos Trinity treinada do zero em parceria com Datology.
Eles lançaram 2 modelos, um modelo MoE de 8 bilhões de parâmetros com 1 bilhão de parâmetros ativos chamado Trinity Nano, e um modelo de 26 bilhões de parâmetros com 3 bilhões de parâmetros ativos chamado Trinity Mini.
Eles também lançarão Trinity Large, que é um modelo de 420B parâmetros com 13B ativos, em janeiro.
O modelo Nano é apenas um lançamento de preview, e não tem benchmarks sobre ele que a Arcee ou qualquer outra pessoa tenha lançado. A Arcee diz que terá uma versão atualizada e sairá do status de preview quando o modelo Large for lançado.
Dado seu tamanho e arquitetura, espero que ele compita com o modelo Liquid 8B MoE que cobrimos há um tempo atrás.
É também um modelo instruct (não-reasoning) o que significa que seus tempos de resposta também devem ser muito rápidos.
O modelo Mini parece ser mais polido, sendo um modelo de reasoning que é competitivo com o modelo Qwen 30B MoE.
Verde-azulado: Arcee Mini; roxo: Qwen 3 30B; azul: gpt-oss 20B; laranja: Mistral Small; rosa: Olmo 3 32B
O modelo passou no meu teste preliminar de sensação, e também a Arcee já fez modelos anteriormente que são mais fortes do que os benchmarks indicam (porque eles não fazem benchmaxx) então espere que este modelo performe um pouco acima de onde os benchmarks o colocam.
Eu recomendaria ler o relatório inicial que eles publicaram para aprender mais sobre os modelos e como eles conseguiram treiná-los em apenas 6 meses.
Estou animado para ver mais desta equipe e definitivamente ficarei de olho neles no futuro para ver o que eles lançam.
Rnj-1
Outro laboratório de IA americano, Essential AI lançou seu primeiro modelo, um modelo instruct denso de 8B parâmetros chamado Rnj-1.
A empresa é jovem, mas seus fundadores estão no espaço de IA há algum tempo, já que sua equipe é liderada por Ashish Vaswani, que é o primeiro autor do paper Attention is All You Need, que introduziu a arquitetura transformer que os LLMs usam hoje.
Pontuações impressionantes, especialmente quando levando em conta os FLOPs de treinamento
O modelo foi treinado com um foco específico em uso de ferramentas e desempenho de codificação, razão pela qual eles fazem benchmark dele nessas tarefas especificamente.
Ele se sai bem nessas apesar de não ter aprendizado por reforço aplicado e apenas uma pequena passagem de ajuste fino supervisionado.
Isso significa que a equipe está em algo grande, ou eles estão fazendo overfitting nos benchmarks.
Ainda não o testei eu mesmo, já que ele foi lançado há menos de um dia no momento em que escrevo, então teremos que esperar para ver.
De qualquer forma, similar à equipe Arcee, estou animado para ver onde esta equipe vai no futuro.
Runway 4.5
Há um novo modelo líder de texto para vídeo, sendo o Runway 4.5.
Pontuações da Artificial Analysis
A equipe Runway está liberando acesso ao longo dos próximos dias/semanas em sua plataforma, que parece ser a única maneira de usar o modelo.
Algumas amostras da Equipe Runway
Nenhuma mudança real de passo em termos de capacidades versus outros modelos, apenas outra melhoria incremental no espaço de geração de vídeo.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quer receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Estilo inspirado em Claude no Midjourney — do Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Mistral 3
El mayor entrenador de LLM de la UE, Mistral, está de vuelta después de otro considerable receso, lanzando 4 nuevos modelos esta semana.
Los modelos varían en tamaño, con 3 modelos densos llamados Ministral 3 con 3B, 8B y 14B parámetros, y luego Mistral Large 3, que es un modelo MoE de 675B con 41B parámetros activos, convirtiéndolo en uno de los modelos de código abierto de frontera más grandes en este momento, solo superado por Kimi K2 con un billón de parámetros.
Los modelos Ministral vienen todos en variantes base, instruct y reasoning, mientras que el modelo Large es solo instruct por ahora, pero dicen que lanzarán una variante reasoning en el futuro.
También todos vienen con capacidades de visión multimodal, pero no son muy buenos en tareas de visión, lo cual se destaca por el hecho de que ni siquiera se molestaron en publicar ningún benchmark de visión.
Puntuación LMArena, básicamente qué tan amigable y adulador es el modelo
El sentimiento general de las personas que usan estos modelos es casi universalmente negativo por lo que he visto, con casi todos diciendo que los modelos funcionan peor que cualquiera de sus contrapartes de tamaño similar en todos los tipos de tareas.
Una falla muy evidente de los modelos es su muy pobre rendimiento agéntico, que es uno de los principales usos de los LLM hoy en día.
Mi suposición es que Mistral no está entrenando con datos sintéticos de llamadas a herramientas y código (llamado mid-training), lo cual realmente ayuda a los modelos con razonamiento, uso de herramientas y tareas agénticas.
Debido a esto, te aconsejaría no usar ninguno de los modelos de Mistral en este momento, ya que hay opciones universalmente mejores disponibles para usar en su lugar.
Basándome en estos modelos, diría que Mistral está un poco atrasado en este momento, y necesitará ponerse al día si quieren seguir siendo relevantes en el ecosistema actual de IA.
En el benchmark de LLM de Artificial Analysis, Mistral Large (600B parámetros) obtuvo una puntuación similar a Qwen3 30B, lo cual es francamente abismal
Kling O1
Tenemos muchos modelos de edición de imágenes y también modelos de generación de video. Pero ha habido una sorprendente falta de modelos de edición de video. Una sorprendente falta de modelos de edición de video que se hayan lanzado, siendo Wan VACE y Runway Aleph los únicos modelos en el espacio de edición de video.
Ahora tenemos un nuevo participante en este espacio escasamente poblado, con el lanzamiento de Kling O1.
El equipo de Kling ha estado mejorando sus modelos de generación de video de manera algo silenciosa, con su actual insignia Kling 2.5 Turbo estando en el top 3 para texto a video y siendo el mejor para imagen a video según Artificial Analysis.
Su modelo O1 hace un buen trabajo manteniendo las características del video de referencia original, y puede llenar los vacíos bastante bien para cualquier cosa que pueda faltar en la imagen (como eliminar objetos de un video). Para edición de video, parece ser el mejor modelo disponible en este momento.
Prompt: Eliminar el tren — de Nucleus en Twitter
Otro ejemplo de un hilo en Twitter
Comparación entre múltiples modelos de edición de video
El precio es de $0.17 por segundo de video editado (precio obtenido de Fal).
El modelo debería estar disponible donde sea que obtengas tus modelos de generación de video, incluyendo Replicate y Fal, o también directamente en el sitio web de Kling AI.
Modelos Arcee Trinity
Arcee AI, un laboratorio estadounidense que ha tenido muchas contribuciones de código abierto en el pasado, ha lanzado su familia de modelos Trinity entrenados desde cero en asociación con Datology.
Han lanzado 2 modelos, un modelo MoE de 8 mil millones de parámetros con 1 mil millones de parámetros activos llamado Trinity Nano, y un modelo de 26 mil millones de parámetros con 3 mil millones activos llamado Trinity Mini.
También lanzarán Trinity Large, que es un modelo de 420B parámetros con 13B activos, en enero.
El modelo Nano es solo un lanzamiento de vista previa, y no hay benchmarks sobre él que Arcee o cualquier otra persona haya publicado. Arcee dice que tendrá una versión actualizada y saldrá del estado de vista previa cuando se lance el modelo Large.
Dado su tamaño y arquitectura, espero que compita con el modelo Liquid 8B MoE que cubrimos hace un tiempo.
También es un modelo instruct (no reasoning) lo que significa que sus tiempos de respuesta también deberían ser muy rápidos.
El modelo Mini parece estar más pulido, siendo un modelo de razonamiento que es competitivo con el modelo Qwen 30B MoE.
Verde azulado: Arcee Mini; morado: Qwen 3 30B; azul: gpt-oss 20B; naranja: Mistral Small; rosa: Olmo 3 32B
El modelo pasó mi prueba preliminar de vibra, y también Arcee ha creado modelos anteriormente que son más fuertes de lo que los benchmarks implican (porque no hacen benchmaxx) así que espera que este modelo golpee un poco por encima de donde los benchmarks lo ubican.
Recomendaría leer su informe inicial que publicaron para aprender más sobre los modelos y cómo pudieron entrenarlos en solo 6 meses.
Estoy emocionado de ver más de este equipo y definitivamente estaré vigilándolos en el futuro para ver qué lanzan.
Rnj-1
Otro laboratorio de IA estadounidense, Essential AI, ha lanzado su primer modelo, un modelo instruct denso de 8B parámetros llamado Rnj-1.
La compañía es joven, pero sus fundadores han estado en el espacio de IA durante un tiempo, ya que su equipo está liderado por Ashish Vaswani, quien es el primer autor del artículo Attention is All You Need, que introdujo la arquitectura transformer que los LLM usan hoy.
Puntuaciones impresionantes, especialmente al tener en cuenta los FLOPs de entrenamiento
El modelo fue entrenado con un enfoque específico en el uso de herramientas y rendimiento de codificación, por lo que lo evalúan en esas tareas específicamente.
Lo hace bien en estas a pesar de no tener aprendizaje por refuerzo y solo un pequeño pase de ajuste fino supervisado.
Esto significa que el equipo está en algo grande, o están sobreajustando en benchmarks.
Aún no lo he probado yo mismo ya que salió hace menos de un día en el momento de escribir esto, así que tendremos que esperar y ver.
De cualquier manera, similar al equipo de Arcee, estoy emocionado de ver hacia dónde va este equipo en el futuro.
Runway 4.5
Hay un nuevo modelo líder de texto a video, siendo ese Runway 4.5.
Puntuaciones de Artificial Analysis
El equipo de Runway está lanzando el acceso durante los próximos días/semanas en su plataforma, que parece ser la única forma de usar el modelo.
Algunas muestras del equipo de Runway
No hay un cambio real de paso en términos de capacidades versus otros modelos, solo otra mejora incremental en el espacio de generación de video.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Estilo inspirado en Claude en Midjourney — de Twitter