Releases
GPT 5.4 Mini and Nano
OpenAI has neglected to update their smaller models, GPT Mini and Nano, for the last 3 versions.
This week we finally got an upgrade for them with the release of GPT 5.4 Mini and Nano.
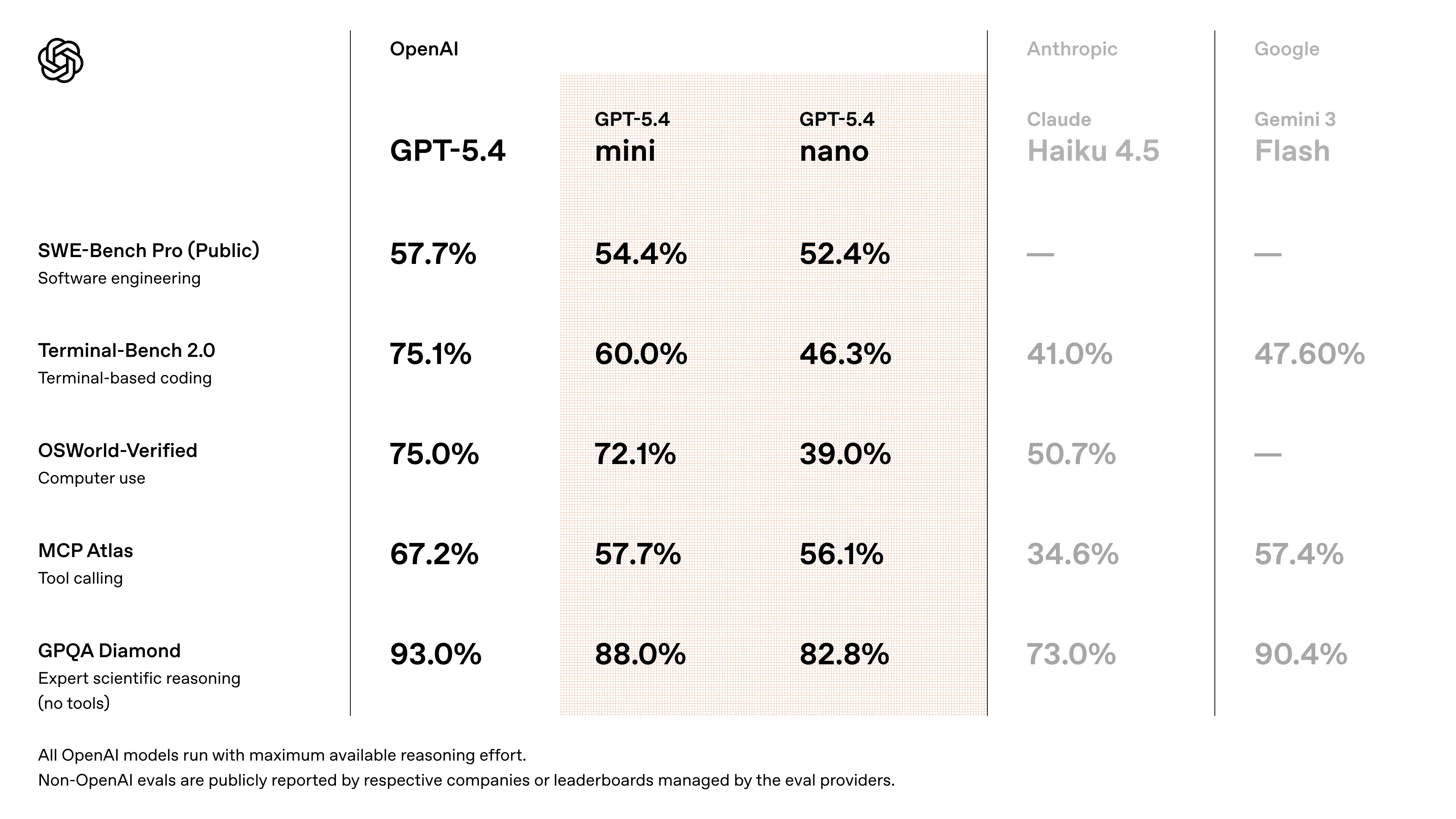
The benchmarks they released focus heavily on coding and agentic use cases
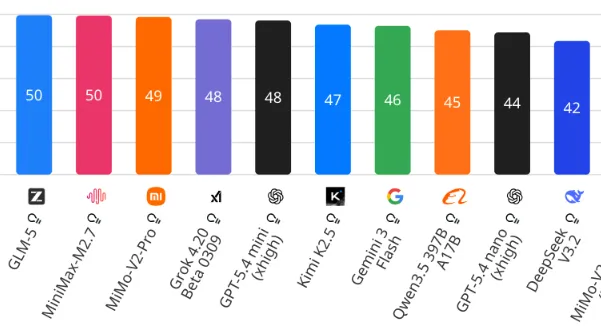 The neighborhood of models they are in from the Artificial Analysis Intelligence benchmark.
The neighborhood of models they are in from the Artificial Analysis Intelligence benchmark.
The mini model (when using extra high reasoning) sits around Gemini 3 Flash and the Chinese frontier models in terms of benchmark capabilities.
The issue is that when you have reasoning turned up this high, the number of tokens used starts to get ridiculous.
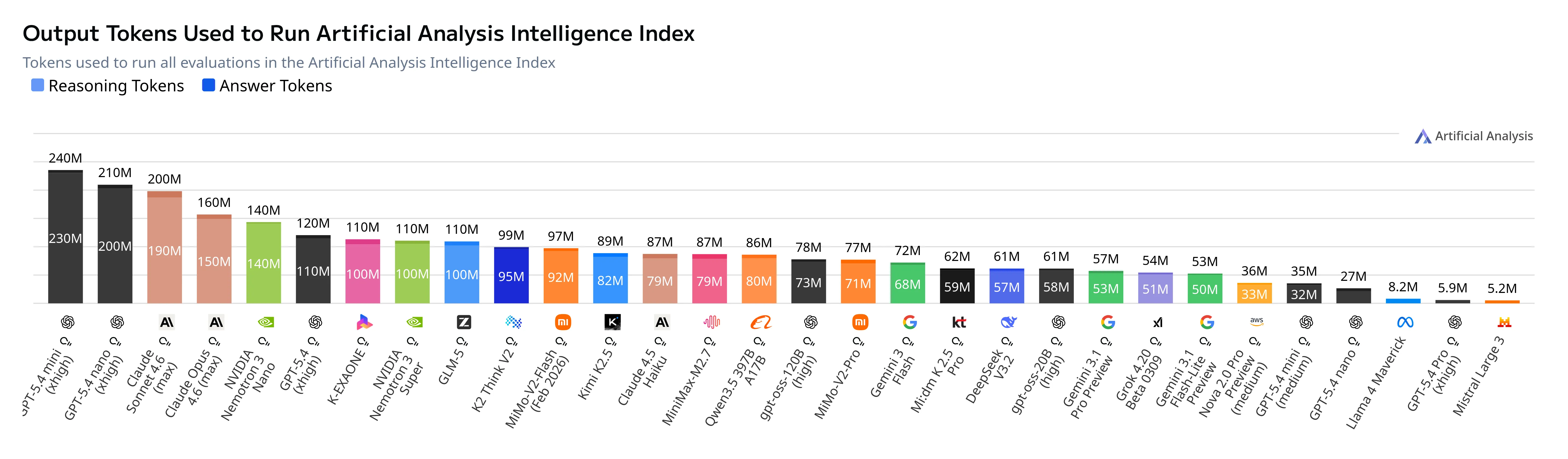 Tokens used to run the Artificial Analysis Intelligence benchmark. GPT 5.4 Mini and Nano can be seen all the way on the left.
Tokens used to run the Artificial Analysis Intelligence benchmark. GPT 5.4 Mini and Nano can be seen all the way on the left.
With a more sane medium reasoning, the models perform noticeably worse than their counterparts in the “cheap but good” model category.
This gap is further exacerbated when you look at the pricing for these “affordable” OpenAI models, which have ~doubled in price versus the GPT 5 Mini and Nano models.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| GPT 5.4 | $2.50 | $15 | 50 |
| GPT 5.4 Mini | $0.75 | $4.5 | 62 |
| GPT 5.4 Nano | $0.20 | $1.25 | 57 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Gemini 3 Flash | $0.50 | $3 | 80 |
| GLM 5 | $1 | $3.20 | 30 |
| MiniMax M2.7 | $0.30 | $1.20 | 34 |
GPT 5.4 Mini uses 3x more tokens per question to have the same performance as MiniMax M2.7, while being 3x more expensive (not counting the extra costs of 3x more tokens).
This also means that even though it looks 2x faster based on tokens per second, it is actually 50% to generate a response.
Because of this, my recommendation is to generally avoid these models, as you can get better models from other domestic providers (Gemini 3 Flash) or from Chinese labs.
This also asks the question: is OpenAI really that far ahead? Or have they just scaled their models more than the Chinese labs have, since it seems that in the <1 trillion parameter category the open models are keeping up or even exceeding what OpenAI can do.
MiniMax M2.7
Speaking of Chinese labs, let’s talk about MiniMax’s new model which we teased earlier.
MiniMax M2.7 builds on their previous popular cost effective M2.5 model, being a relatively lightweight 220B parameter mixture of experts model.
Unlike OpenAI, they are not increasing the model’s due its increased performance.
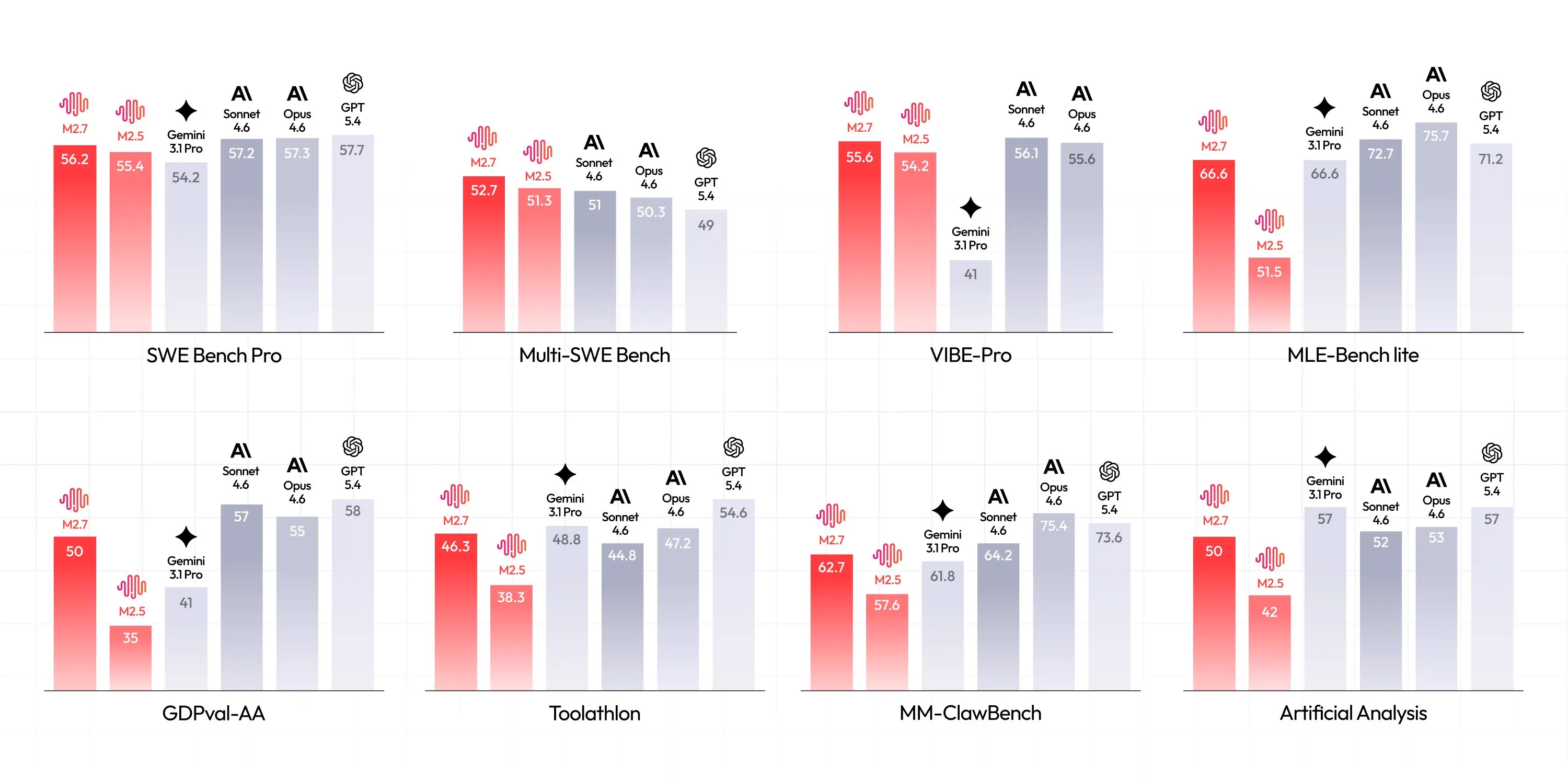
Similar to GPT 5.3 Codex M2.7 was used to help build itself, with an early checkpoint helping with 30-50% of the reinforcement learning teams workflows, highlighting its abilities for coding and general agentic tasks.
They also have been working on the model’s character and personality, making it much more pleasant to talk with.
I do not think it is at the same personality level of Claude or Kimi, but it is right below them and they seem to be making big strides.
Because of the improved agentic capabilities, personality, and very low cost, it is probably the best model to use with OpenClaw (see pricing table above).
If you are a true power user, or just prefer a monthly subscription plan instead of using the API, they have a $10/month plan that gives you 1500 requests every 5 hours (4 requests per minute).
If you want a strong, cost effective agentic model, MiniMax M2.7 looks like the go to.
I will probably be using this as my default for agentic projects now instead of Gemini 3 Flash go forward.
Quick Hits
Cursor Composer 2
Cursor released their own trained in house agentic coding model Composer 2.
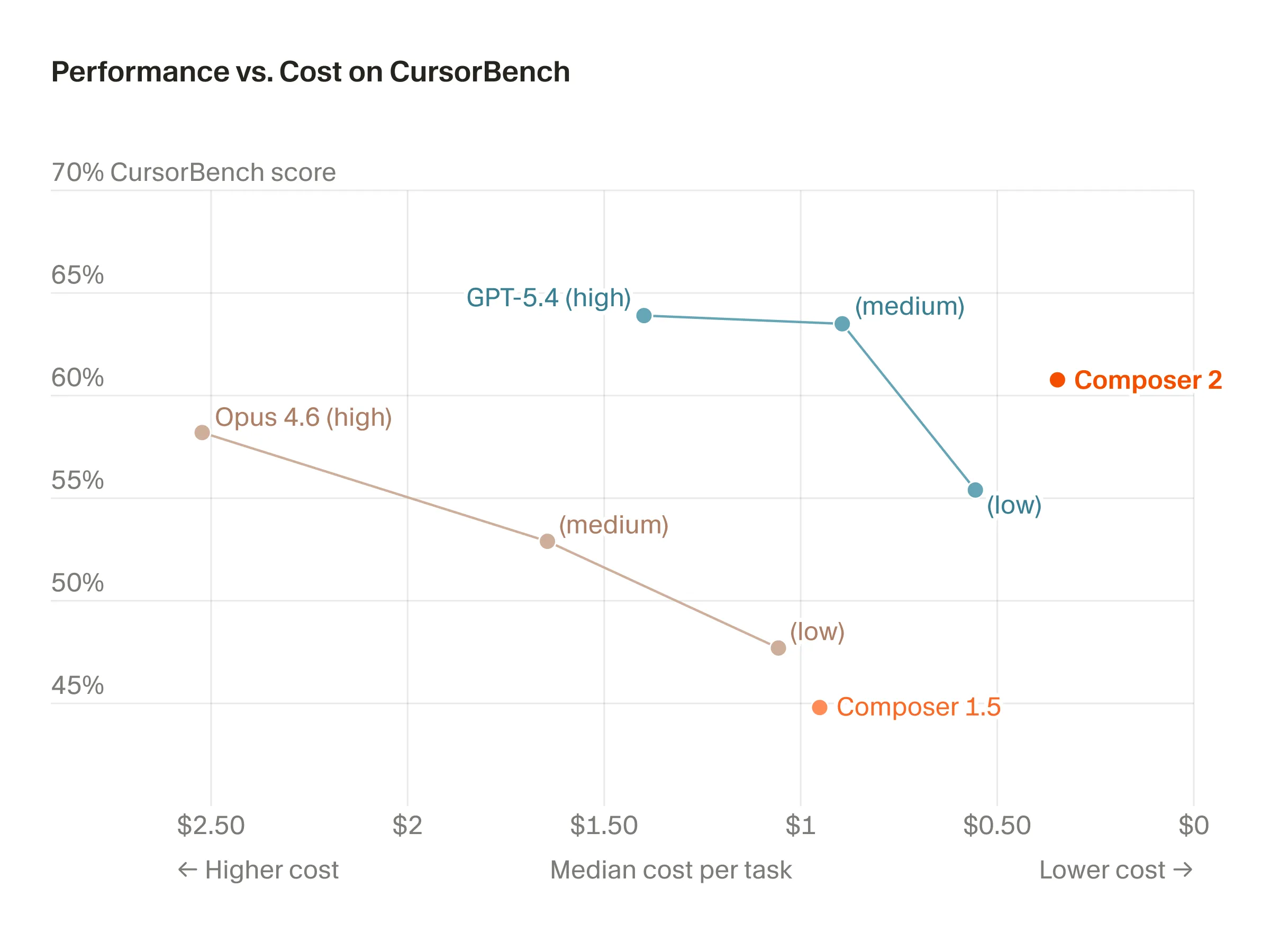
Cursor bench is an internal company benchmark that we know nothing about, “shockingly” Cursor’s model is the best as it
They did not train the model from scratch, instead starting from Kimi K2.5 as a base, doing continued pretraining on it and then their own finetuning as well.
This was a bit controversial at the start, since they did not disclose this, but the community was able to figure it out from some internal model naming, and Cursor has confirmed this themselves as well now.
Because of all of the drama surrounding the model, I have seen very little about its capabilities at this point (I also don’t have a Cursor subscription).
If you do, I would say check it out, it is very cheap (although only accessible through Cursor, no API access available) and a few of the other benchmarks I have seen for it seem to imply that the model is fairly decent.
Mistral 4 Small
Mistral released the first model in their Mistral 4 lineup, called Mistral 4 Small.
It is a 110B parameter MoE model, with 6.5B active params.
The small naming is very apt, since it is competitive with the new Qwen3.5 Small models.
The only thing is that the Qwen 3.5 models are 100x smaller.
Sadly for Mistral this model is very dead on arrival, not even beating models half its size from 3 months ago.
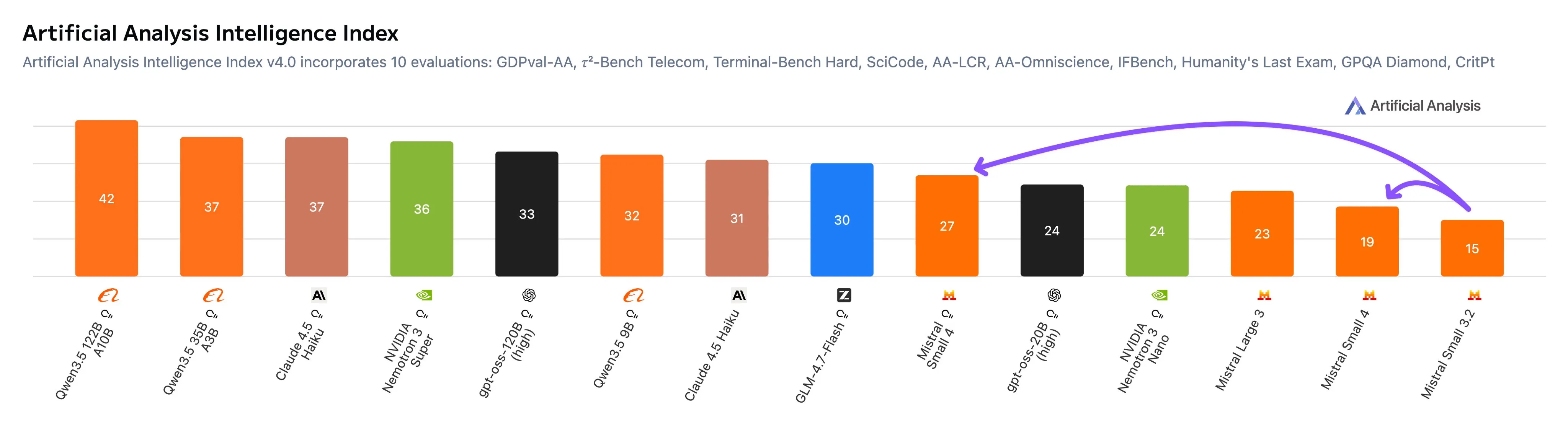
AA bench scores. 110B model losing to Qwen 3.5 9B. Yikes.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
the endless fight by Nicolas Daniel on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
GPT 5.4 Mini e Nano
A OpenAI negligenciou a atualização de seus modelos menores, o GPT Mini e o Nano, nas últimas 3 versões.
Esta semana finalmente recebemos uma atualização para eles com o lançamento do GPT 5.4 Mini e Nano.
Os benchmarks divulgados focam fortemente em casos de uso de programação e agentes
O grupo de modelos em que se encontram segundo o benchmark da Artificial Analysis Intelligence.
O modelo mini (com raciocínio extra elevado ativado) fica próximo do Gemini 3 Flash e dos modelos chineses de fronteira em termos de capacidades de benchmark.
O problema é que quando o raciocínio está tão elevado, o número de tokens utilizados começa a ficar absurdo.
Tokens utilizados para executar o benchmark da Artificial Analysis Intelligence. O GPT 5.4 Mini e Nano podem ser vistos bem à esquerda.
Com um nível de raciocínio médio mais sensato, os modelos apresentam desempenho visivelmente inferior ao de seus equivalentes na categoria de modelos “baratos, mas bons”.
Essa diferença é ainda maior quando se observa o preço desses modelos OpenAI “acessíveis”, que custam aproximadamente o dobro em relação aos modelos GPT 5 Mini e Nano.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| GPT 5.4 | $2,50 | $15 | 50 |
| GPT 5.4 Mini | $0,75 | $4,50 | 62 |
| GPT 5.4 Nano | $0,20 | $1,25 | 57 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Gemini 3 Flash | $0,50 | $3 | 80 |
| GLM 5 | $1 | $3,20 | 30 |
| MiniMax M2.7 | $0,30 | $1,20 | 34 |
O GPT 5.4 Mini usa 3x mais tokens por pergunta para ter o mesmo desempenho que o MiniMax M2.7, sendo 3x mais caro (sem contar os custos adicionais dos 3x mais tokens).
Isso também significa que, embora pareça 2x mais rápido com base em tokens por segundo, na prática é 50% mais lento para gerar uma resposta.
Por causa disso, minha recomendação é evitar esses modelos em geral, já que você pode obter modelos melhores de outros provedores domésticos (Gemini 3 Flash) ou de laboratórios chineses.
Isso também levanta a questão: a OpenAI está realmente tão à frente? Ou será que eles apenas escalaram seus modelos mais do que os laboratórios chineses, já que parece que na categoria de menos de 1 trilhão de parâmetros os modelos abertos estão se mantendo ou até superando o que a OpenAI consegue fazer.
MiniMax M2.7
Falando em laboratórios chineses, vamos falar sobre o novo modelo da MiniMax que mencionamos anteriormente.
O MiniMax M2.7 aprimora o popular e eficiente modelo M2.5, sendo um modelo de mistura de especialistas relativamente leve com 220B de parâmetros.
Ao contrário da OpenAI, eles não estão aumentando o preço do modelo por conta de seu desempenho superior.
Semelhante ao GPT 5.3 Codex, o M2.7 foi utilizado para ajudar a construir a si mesmo, com um checkpoint inicial contribuindo com 30-50% dos fluxos de trabalho das equipes de aprendizado por reforço, destacando suas capacidades para programação e tarefas agênticas em geral.
Eles também trabalharam no caráter e na personalidade do modelo, tornando-o muito mais agradável para conversar.
Não acho que ele esteja no mesmo nível de personalidade do Claude ou do Kimi, mas está logo abaixo deles e parece que estão avançando bastante.
Por causa das melhores capacidades agênticas, personalidade e custo muito baixo, é provavelmente o melhor modelo para usar com o OpenClaw (veja a tabela de preços acima).
Se você é um usuário avançado, ou apenas prefere um plano de assinatura mensal em vez de usar a API, eles têm um plano de $10/mês que oferece 1500 requisições a cada 5 horas (4 requisições por minuto).
Se você quer um modelo agêntico robusto e econômico, o MiniMax M2.7 parece ser a melhor opção.
Provavelmente vou usá-lo como meu padrão para projetos agênticos daqui para frente, em vez do Gemini 3 Flash.
Destaques Rápidos
Cursor Composer 2
A Cursor lançou seu próprio modelo de programação agêntica desenvolvido internamente, o Composer 2.
O Cursor bench é um benchmark interno da empresa sobre o qual não sabemos nada — “surpreendentemente”, o modelo da Cursor é o melhor nele
Eles não treinaram o modelo do zero, partindo em vez disso do Kimi K2.5 como base, realizando pré-treinamento continuado sobre ele e também seu próprio ajuste fino.
Isso foi um pouco controverso no início, já que eles não divulgaram isso, mas a comunidade conseguiu descobrir a partir de alguns nomes internos de modelos, e a própria Cursor confirmou isso agora também.
Por causa de toda a polêmica em torno do modelo, vi muito pouco sobre suas capacidades até agora (também não tenho uma assinatura do Cursor).
Se você tiver, eu diria para experimentá-lo: é muito barato (embora acessível apenas pelo Cursor, sem acesso via API) e alguns dos outros benchmarks que vi parecem indicar que o modelo é razoavelmente bom.
Mistral 4 Small
A Mistral lançou o primeiro modelo de sua linha Mistral 4, chamado Mistral 4 Small.
É um modelo MoE com 110B de parâmetros e 6,5B de parâmetros ativos.
O nome “small” é bastante adequado, já que é competitivo com os novos modelos Qwen3.5 Small.
O único detalhe é que os modelos Qwen 3.5 são 100x menores.
Infelizmente para a Mistral, este modelo chega muito obsoleto, sem sequer superar modelos metade do seu tamanho lançados há 3 meses.
Pontuações do AA bench. Um modelo de 110B perdendo para o Qwen 3.5 9B. Que vergonha.
Encerramento
Espero que você tenha gostado das novidades desta semana. Se quiser receber as notícias toda semana, não deixe de se inscrever em nossa lista de e-mails abaixo.
the endless fight por Nicolas Daniel no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
GPT 5.4 Mini y Nano
OpenAI ha descuidado la actualización de sus modelos más pequeños, GPT Mini y Nano, durante las últimas 3 versiones.
Esta semana finalmente obtuvimos una actualización para ellos con el lanzamiento de GPT 5.4 Mini y Nano.
Los benchmarks que publicaron se centran fuertemente en casos de uso de programación y agentes
El grupo de modelos en el que se encuentran según el benchmark de Artificial Analysis Intelligence.
El modelo mini (al usar razonamiento extra alto) se sitúa cerca de Gemini 3 Flash y los modelos frontera chinos en términos de capacidades de benchmark.
El problema es que cuando el razonamiento está tan elevado, la cantidad de tokens utilizados empieza a volverse ridícula.
Tokens utilizados para ejecutar el benchmark de Artificial Analysis Intelligence. GPT 5.4 Mini y Nano se pueden ver al extremo izquierdo.
Con un razonamiento medio más sensato, los modelos rinden notablemente peor que sus contrapartes en la categoría de modelos “baratos pero buenos”.
Esta brecha se agrava aún más cuando se observa el precio de estos modelos “asequibles” de OpenAI, que han ~duplicado su precio en comparación con los modelos GPT 5 Mini y Nano.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| GPT 5.4 | $2.50 | $15 | 50 |
| GPT 5.4 Mini | $0.75 | $4.5 | 62 |
| GPT 5.4 Nano | $0.20 | $1.25 | 57 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Gemini 3 Flash | $0.50 | $3 | 80 |
| GLM 5 | $1 | $3.20 | 30 |
| MiniMax M2.7 | $0.30 | $1.20 | 34 |
GPT 5.4 Mini usa 3 veces más tokens por pregunta para tener el mismo rendimiento que MiniMax M2.7, siendo además 3 veces más caro (sin contar los costos adicionales de 3 veces más tokens).
Esto también significa que, aunque parezca 2 veces más rápido en tokens por segundo, en realidad es un 50% más lento para generar una respuesta.
Por todo esto, mi recomendación es evitar estos modelos en general, ya que se pueden obtener mejores modelos de otros proveedores nacionales (Gemini 3 Flash) o de laboratorios chinos.
Esto también plantea la pregunta: ¿realmente está OpenAI tan por delante? ¿O simplemente han escalado sus modelos más que los laboratorios chinos, dado que parece que en la categoría de menos de 1 billón de parámetros los modelos abiertos están igualando o incluso superando lo que OpenAI puede hacer?
MiniMax M2.7
Hablando de laboratorios chinos, hablemos del nuevo modelo de MiniMax que mencionamos antes.
MiniMax M2.7 se basa en su popular y rentable modelo anterior M2.5, siendo un modelo de mezcla de expertos relativamente ligero de 220B parámetros.
A diferencia de OpenAI, no están aumentando el precio del modelo debido a su mayor rendimiento.
De manera similar a GPT 5.3 Codex, M2.7 fue utilizado para ayudar a construirse a sí mismo, con un checkpoint temprano ayudando en el 30-50% de los flujos de trabajo del equipo de aprendizaje por refuerzo, destacando sus capacidades para programación y tareas agentivas generales.
También han trabajado en el carácter y la personalidad del modelo, haciéndolo mucho más agradable para conversar.
No creo que esté al mismo nivel de personalidad que Claude o Kimi, pero está justo por debajo de ellos y parecen estar dando grandes pasos.
Gracias a las mejoras en las capacidades agentivas, la personalidad y el muy bajo costo, probablemente sea el mejor modelo para usar con OpenClaw (ver tabla de precios arriba).
Si eres un usuario avanzado, o simplemente prefieres un plan de suscripción mensual en lugar de usar la API, tienen un plan de $10/mes que te da 1500 solicitudes cada 5 horas (4 solicitudes por minuto).
Si buscas un modelo agentivo potente y rentable, MiniMax M2.7 parece ser la opción predilecta.
Probablemente lo usaré como mi opción predeterminada para proyectos agentivos de ahora en adelante, en lugar de Gemini 3 Flash.
Noticias Rápidas
Cursor Composer 2
Cursor lanzó su propio modelo de programación agentiva entrenado internamente, Composer 2.
Cursor bench es un benchmark interno de la empresa del que no sabemos nada, y “sorprendentemente” el modelo de Cursor es el mejor en él
No entrenaron el modelo desde cero, sino que partieron de Kimi K2.5 como base, realizando preentrenamiento continuo sobre él y luego su propio ajuste fino.
Esto fue algo polémico al principio, ya que no lo divulgaron, pero la comunidad pudo descubrirlo a partir de algunos nombres internos del modelo, y Cursor lo ha confirmado ellos mismos también.
Debido a todo el revuelo alrededor del modelo, he visto muy poco sobre sus capacidades hasta ahora (además, no tengo una suscripción a Cursor).
Si la tienes, diría que lo pruebes: es muy barato (aunque solo accesible a través de Cursor, sin acceso por API) y algunos otros benchmarks que he visto parecen indicar que el modelo es bastante decente.
Mistral 4 Small
Mistral lanzó el primer modelo de su línea Mistral 4, llamado Mistral 4 Small.
Es un modelo MoE de 110B parámetros, con 6.5B parámetros activos.
El nombre “small” es muy acertado, ya que es competitivo con los nuevos modelos Qwen3.5 Small.
El único detalle es que los modelos Qwen 3.5 son 100 veces más pequeños.
Lamentablemente para Mistral, este modelo llega muy muerto, sin siquiera superar a modelos de la mitad de su tamaño de hace 3 meses.
Puntuaciones del benchmark de AA. Un modelo de 110B perdiendo ante Qwen 3.5 9B. Escalofriante.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
the endless fight por Nicolas Daniel en Twitter