Releases
Claude Haiku 4.5
It has been almost a year since the last Claude Haiku release, so I don’t blame you if you have forgotten about this model. Haiku is the smallest member of the Claude Trinity, and its most recent update had been from the Claude 3.5 series of models, which, depending on how you count it, means its 5 versions behind its brothers Opus and Sonnet.
Haiku 4.5 is being billed as a Sonnet 4 replacement, which puts it squarely against the GLM 4.6 model, so how does it stack up?
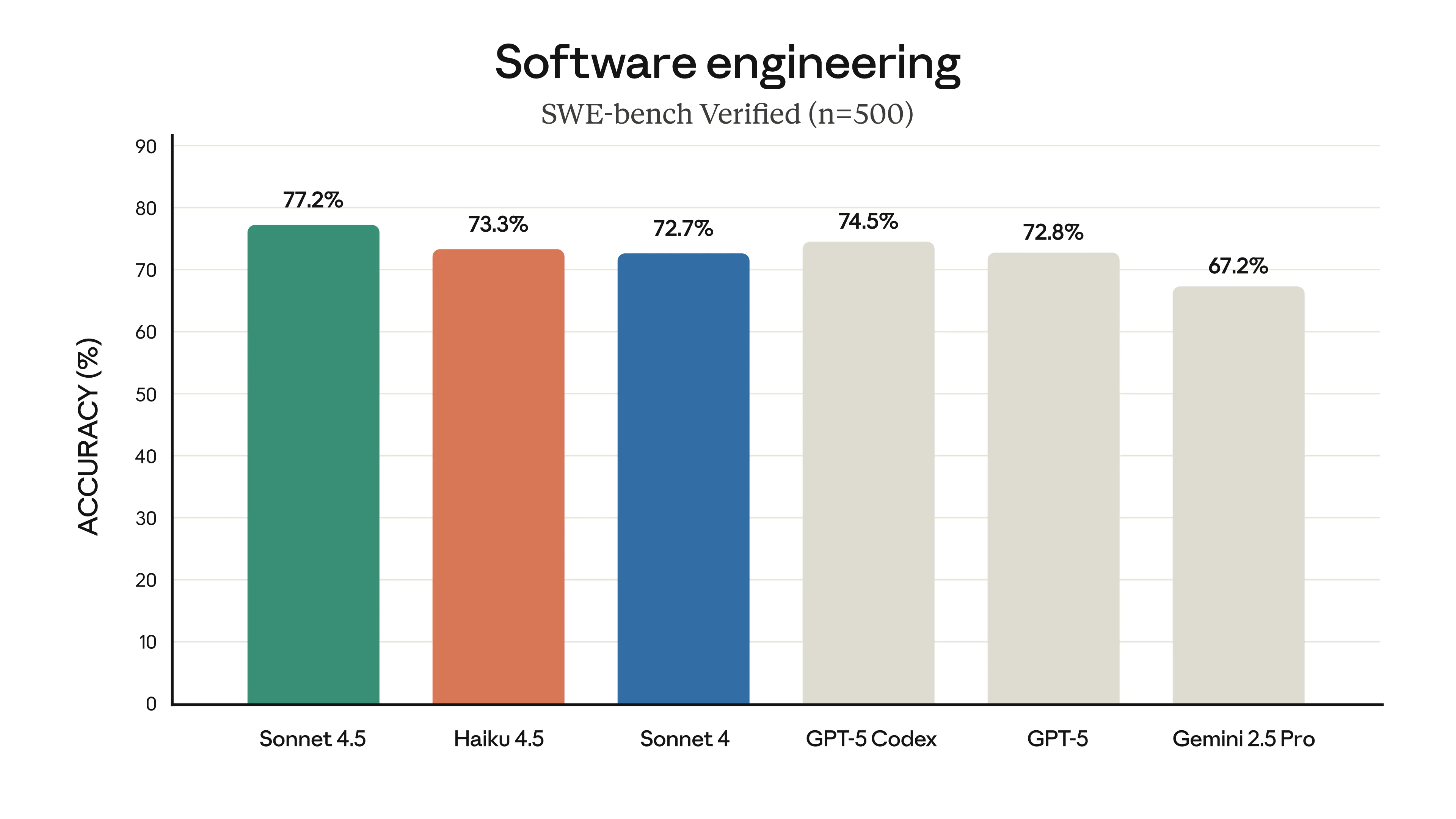
SWE Bench is not a very interesting or meaningful benchmark (its mostly Django) but companies still like pushing is anyways
Not very impressively, is the answer. Its one main selling point over GLM 4.6 is that it’s a bit faster, but otherwise it’s about two times more expensive to use.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| GLM 4.6 | $0.60 | $2.20 | 46 |
| Claude Haiku 4.5 | $1 | $5 | 106 |
Data from OpenRouter
Also, the public consensus seems to put it a bit below Sonnet 4, whereas for GLM 4.6, people tend to prefer it to Sonnet 4.
It is currently unknown how the rate limits are for it in Claude code with the anthropic subscription. But the limits are going to have to be extremely generous to make it a better value than GLM 4.6, especially considering the subscription is almost 10 times more expensive.
Because of this, I don’t think it’s a very interesting or unique release and does not change the LLM landscape at all.
Qwen3 VL 4B and 8B
Qwen continues to release models in their vision lineup, dropping a 4 and 8 billion parameter VLMs based on their Qwen3 models.
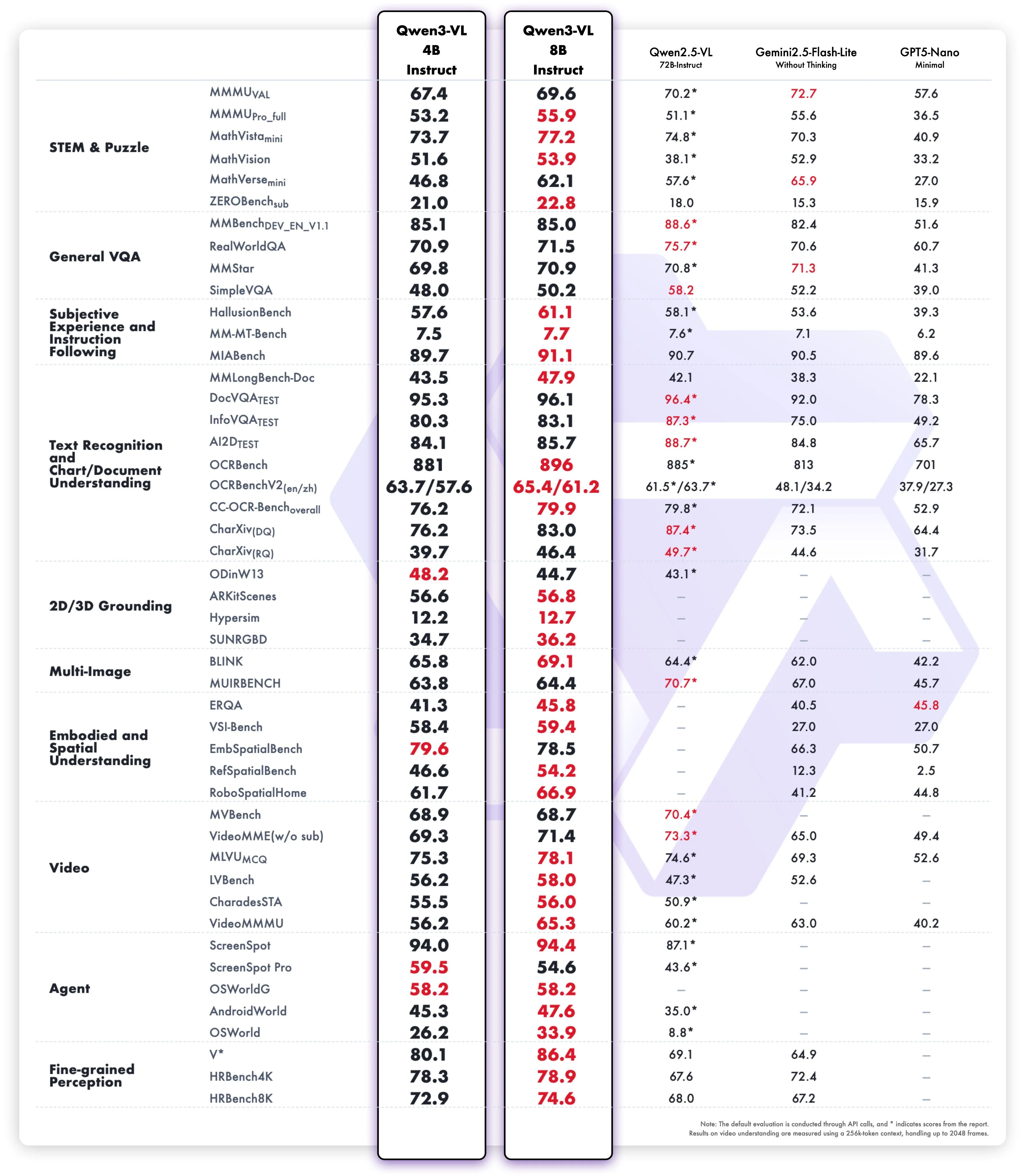
Vision benchmarks
As expected, they are number one for their given sizes. Not that that really means much given that there is not much competition in the open source VLM space right now. Despite this, they are still strong models that are good enough to make them usable in the real world for basic tasks while being able to be deployed on device.
Of note: non-vision benchmarks decreased a bit more than they did for the larger variants, but the difference is still relatively small (1-2% drop in absolute performance)
Another interesting aspect is the release of an 8 billion parameter model. Previously, in their Qwen 3 refreshes, they had neglected to update their 8 billion parameter model along with a couple others. But now with this release, they have updated the post-training of their 8 billion parameter model and also added vision capabilities to it, which is good to see since the eight billion parameter size is ideal for small at-home GPU deployments.
Veo 3.1
Google has released a new version of their already very strong Veo 3 model.
For this version, they have greatly improved the image to text performance and ability to do proper video creations for the likes of tv shows or movies. For instance you can upload an image of a location, and then ask the model to generate video of a helicopter flying over it.
The usual benchmarks have yet to release scores for the model, but from what I have been seeing, it looks to be near the top for image to video generation.
Research
New Long Context Benchmarks
Long context is usually very hard for models. Only with some of the recent frontier releases like GPT-5 have models been able to even remotely use their full context window.
The “hardest” long context benchmarks only tested to see how good a model is at retrieving information from its context; none of the benchmarks made the model to anything complex with this information.
We now have a new benchmark that looks to fill this gap. LongCodeEdit is a benchmark that looks to measure an LLM’s ability to find, diagnose and fix bugs across a large file.
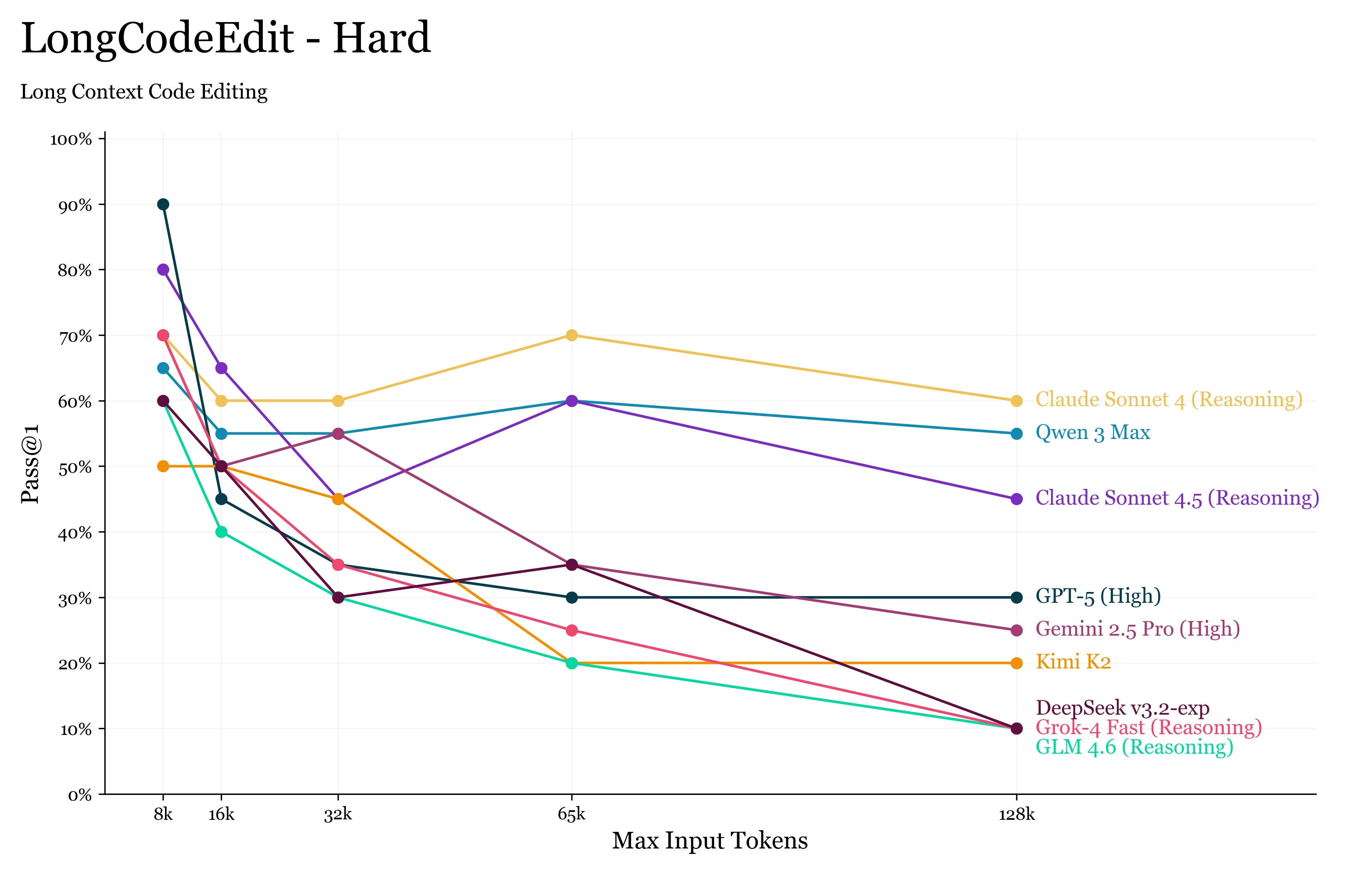
What we find is more of the same from the previous long context benchmarks: that LLM’s are remarkably bad at using their reported context window, as even at 16k tokens we see non-trivial performance degradation on the tasks.
The benchmark takes a number of working functions from existing code benchmarks, corrupts a single one of them, and then passes all of them together into a single “file” to the LLM.
Surprisingly, we find that GPT-5 degrades significantly, while Sonnet 4 and 4.5 are able to roughly maintain their capabilities.
Also of note is the Qwen team being number 2, with their flagship Qwen3 Max model.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

OpenAI Stargate datacenter — from NunoSempere on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
resumo
- Claude Haiku recebe uma atualização depois de quase um ano
- Veo 3.1 é bom em conversão de imagem para vídeo
- Novos benchmarks mostram o quão ruins os LLMs são em tarefas de contexto longo
- E mais modelos Qwen3 VL
Lançamentos
Claude Haiku 4.5
Já faz quase um ano desde o último lançamento do Claude Haiku, então não te culpo se você esqueceu deste modelo. Haiku é o membro menor da Trindade Claude, e sua atualização mais recente tinha sido da série Claude 3.5 de modelos, que, dependendo de como você conta, significa que está 5 versões atrás de seus irmãos Opus e Sonnet.
Haiku 4.5 está sendo divulgado como um substituto do Sonnet 4, o que o coloca diretamente contra o modelo GLM 4.6, então como ele se compara?
SWE Bench não é um benchmark muito interessante ou significativo (é principalmente Django) mas as empresas ainda gostam de divulgá-lo de qualquer forma
Não muito impressionante, é a resposta. Seu principal ponto de venda sobre o GLM 4.6 é que é um pouco mais rápido, mas por outro lado é cerca de duas vezes mais caro de usar.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| GLM 4.6 | $0.60 | $2.20 | 46 |
| Claude Haiku 4.5 | $1 | $5 | 106 |
Dados do OpenRouter
Além disso, o consenso público parece colocá-lo um pouco abaixo do Sonnet 4, enquanto para o GLM 4.6, as pessoas tendem a preferi-lo ao Sonnet 4.
Atualmente não se sabe quais são os limites de taxa para ele no Claude code com a assinatura anthropic. Mas os limites terão que ser extremamente generosos para torná-lo um valor melhor que o GLM 4.6, especialmente considerando que a assinatura é quase 10 vezes mais cara.
Por causa disso, não acho que seja um lançamento muito interessante ou único e não muda o cenário de LLM de forma alguma.
Qwen3 VL 4B e 8B
Qwen continua a lançar modelos em sua linha de visão, liberando VLMs de 4 e 8 bilhões de parâmetros baseados em seus modelos Qwen3.
Benchmarks de visão
Como esperado, eles são número um para seus respectivos tamanhos. Não que isso realmente signifique muito, dado que não há muita competição no espaço VLM de código aberto agora. Apesar disso, eles ainda são modelos fortes o suficiente para torná-los utilizáveis no mundo real para tarefas básicas, podendo ser implantados no dispositivo.
Nota importante: os benchmarks sem visão diminuíram um pouco mais do que nas variantes maiores, mas a diferença ainda é relativamente pequena (queda de 1-2% no desempenho absoluto)
Outro aspecto interessante é o lançamento de um modelo de 8 bilhões de parâmetros. Anteriormente, em suas atualizações do Qwen 3, eles haviam negligenciado atualizar seu modelo de 8 bilhões de parâmetros junto com alguns outros. Mas agora com este lançamento, eles atualizaram o pós-treinamento de seu modelo de 8 bilhões de parâmetros e também adicionaram capacidades de visão a ele, o que é bom de ver, já que o tamanho de 8 bilhões de parâmetros é ideal para pequenas implantações de GPU domésticas.
Veo 3.1
Google lançou uma nova versão de seu já muito forte modelo Veo 3.
Para esta versão, eles melhoraram muito o desempenho de imagem para texto e a capacidade de fazer criações de vídeo adequadas para programas de TV ou filmes. Por exemplo, você pode enviar uma imagem de um local e então pedir ao modelo para gerar vídeo de um helicóptero voando sobre ele.
Os benchmarks usuais ainda não lançaram pontuações para o modelo, mas pelo que tenho visto, parece estar perto do topo para geração de imagem para vídeo.
Pesquisa
Novos Benchmarks de Contexto Longo
Contexto longo geralmente é muito difícil para os modelos. Apenas com alguns dos lançamentos de fronteira recentes como GPT-5 os modelos conseguiram usar remotamente sua janela de contexto completa.
Os benchmarks de contexto longo “mais difíceis” apenas testavam quão bom um modelo é em recuperar informações de seu contexto; nenhum dos benchmarks fazia o modelo fazer algo complexo com essas informações.
Agora temos um novo benchmark que busca preencher essa lacuna. LongCodeEdit é um benchmark que busca medir a capacidade de um LLM de encontrar, diagnosticar e corrigir bugs em um arquivo grande.
O que encontramos é mais do mesmo dos benchmarks de contexto longo anteriores: que os LLMs são notavelmente ruins em usar sua janela de contexto reportada, já que mesmo com 16k tokens vemos degradação de desempenho não trivial nas tarefas.
O benchmark pega várias funções funcionais de benchmarks de código existentes, corrompe uma única delas e então passa todas elas juntas em um único “arquivo” para o LLM.
Surpreendentemente, descobrimos que o GPT-5 degrada significativamente, enquanto Sonnet 4 e 4.5 conseguem manter aproximadamente suas capacidades.
Também digno de nota é a equipe Qwen ficando em segundo lugar, com seu modelo carro-chefe Qwen3 Max.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Datacenter OpenAI Stargate — de NunoSempere no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
En resumen
- Claude Haiku recibe una actualización después de casi un año
- Veo 3.1 es bueno en imagen a video
- Nuevos benchmarks muestran qué tan malos son los LLM en tareas de contexto largo
- Y más modelos Qwen3 VL
Lanzamientos
Claude Haiku 4.5
Ha pasado casi un año desde el último lanzamiento de Claude Haiku, así que no te culpo si te has olvidado de este modelo. Haiku es el miembro más pequeño de la Trinidad Claude, y su actualización más reciente había sido de la serie de modelos Claude 3.5, lo que, dependiendo de cómo lo cuentes, significa que está 5 versiones detrás de sus hermanos Opus y Sonnet.
Haiku 4.5 se está promocionando como un reemplazo de Sonnet 4, lo que lo coloca directamente contra el modelo GLM 4.6, entonces ¿cómo se compara?
SWE Bench no es un benchmark muy interesante o significativo (es principalmente Django) pero a las empresas todavía les gusta promocionarlo de todos modos
La respuesta es: no muy impresionantemente. Su principal punto de venta sobre GLM 4.6 es que es un poco más rápido, pero por lo demás es aproximadamente dos veces más caro de usar.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| GLM 4.6 | $0.60 | $2.20 | 46 |
| Claude Haiku 4.5 | $1 | $5 | 106 |
Datos de OpenRouter
Además, el consenso público parece colocarlo un poco por debajo de Sonnet 4, mientras que para GLM 4.6, la gente tiende a preferirlo sobre Sonnet 4.
Actualmente se desconoce cuáles son los límites de tasa para él en Claude code con la suscripción de Anthropic. Pero los límites tendrán que ser extremadamente generosos para que sea un mejor valor que GLM 4.6, especialmente considerando que la suscripción es casi 10 veces más cara.
Debido a esto, no creo que sea un lanzamiento muy interesante o único y no cambia el panorama de LLM en absoluto.
Qwen3 VL 4B y 8B
Qwen continúa lanzando modelos en su línea de visión, publicando VLMs de 4 y 8 mil millones de parámetros basados en sus modelos Qwen3.
Benchmarks de visión
Como era de esperar, son número uno para sus tamaños respectivos. No es que eso realmente signifique mucho dado que no hay mucha competencia en el espacio de VLM de código abierto en este momento. A pesar de esto, siguen siendo modelos sólidos que son lo suficientemente buenos como para hacerlos utilizables en el mundo real para tareas básicas mientras pueden ser desplegados en el dispositivo.
De nota: los benchmarks sin visión disminuyeron un poco más de lo que lo hicieron para las variantes más grandes, pero la diferencia sigue siendo relativamente pequeña (caída del 1-2% en rendimiento absoluto)
Otro aspecto interesante es el lanzamiento de un modelo de 8 mil millones de parámetros. Anteriormente, en sus actualizaciones de Qwen 3, habían descuidado actualizar su modelo de 8 mil millones de parámetros junto con un par de otros. Pero ahora con este lanzamiento, han actualizado el post-entrenamiento de su modelo de 8 mil millones de parámetros y también le han agregado capacidades de visión, lo cual es bueno ver ya que el tamaño de ocho mil millones de parámetros es ideal para pequeños despliegues de GPU en casa.
Veo 3.1
Google ha lanzado una nueva versión de su ya muy potente modelo Veo 3.
Para esta versión, han mejorado enormemente el rendimiento de imagen a texto y la capacidad de hacer creaciones de video adecuadas para programas de televisión o películas. Por ejemplo, puedes subir una imagen de una ubicación y luego pedirle al modelo que genere video de un helicóptero volando sobre ella.
Los benchmarks habituales aún no han publicado puntuaciones para el modelo, pero por lo que he estado viendo, parece estar cerca de la cima para generación de imagen a video.
Investigación
Nuevos Benchmarks de Contexto Largo
El contexto largo suele ser muy difícil para los modelos. Solo con algunos de los lanzamientos de frontera recientes como GPT-5 han podido los modelos usar remotamente su ventana de contexto completa.
Los benchmarks de contexto largo “más difíciles” solo probaron qué tan bueno es un modelo para recuperar información de su contexto; ninguno de los benchmarks hizo que el modelo hiciera algo complejo con esta información.
Ahora tenemos un nuevo benchmark que busca llenar este vacío. LongCodeEdit es un benchmark que busca medir la capacidad de un LLM para encontrar, diagnosticar y corregir errores en un archivo grande.
Lo que encontramos es más de lo mismo de los benchmarks de contexto largo anteriores: que los LLM son notablemente malos usando su ventana de contexto reportada, ya que incluso a 16k tokens vemos degradación de rendimiento no trivial en las tareas.
El benchmark toma una serie de funciones que funcionan de benchmarks de código existentes, corrompe una sola de ellas, y luego las pasa todas juntas en un solo “archivo” al LLM.
Sorprendentemente, encontramos que GPT-5 se degrada significativamente, mientras que Sonnet 4 y 4.5 son capaces de mantener aproximadamente sus capacidades.
También es de notar que el equipo de Qwen está en el número 2, con su modelo insignia Qwen3 Max.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Centro de datos Stargate de OpenAI — de NunoSempere en Twitter