Releases
GPT 5.4
OpenAI released an update to their GPT 5 series of models this week.
GPT 5.4 is their latest reasoning model, skipping GPT 5.3 as its increased capabilities warrant a more than 0.1 version bump according to OpenAI.
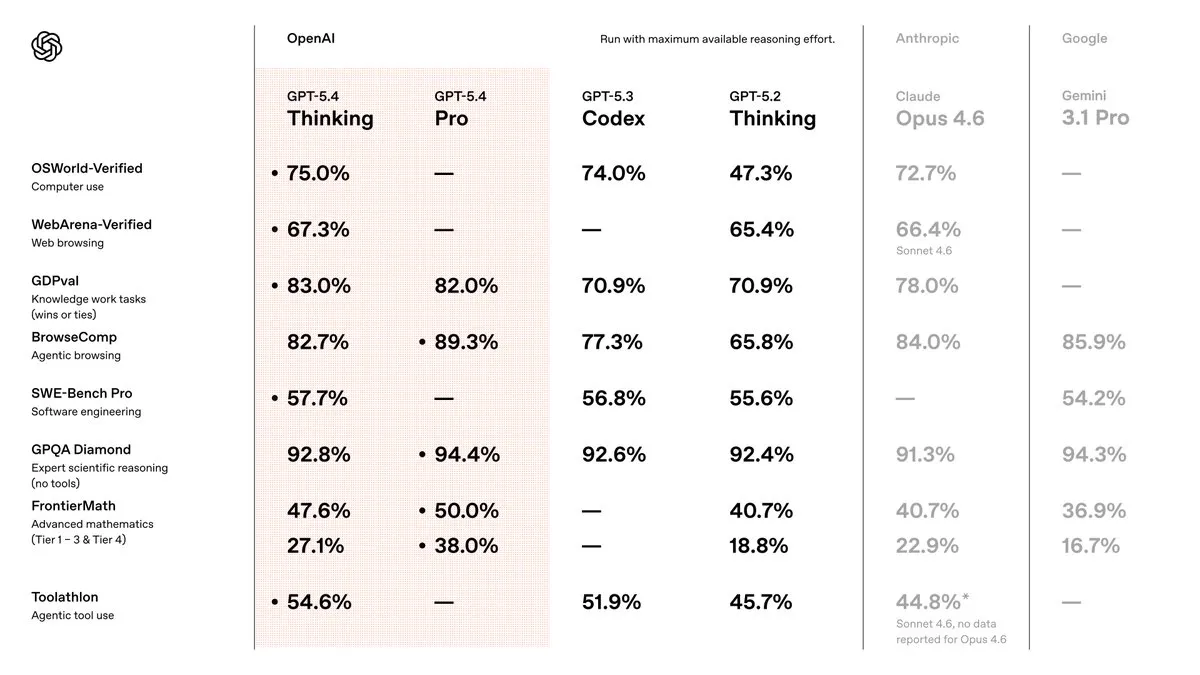
New benchmarking hack: grey-out your competitors
GPT 5.3 Codex was already tied with Opus 4.6 for coding use cases, but fell behind for more general day to day use cases.
GPT 5.4 looks to correct these issues to be the best model to use, and outside of a couple use cases, they seem to have succeeded.
In terms of raw intelligence, and ability to get things done, GPT 5.4 is the best model out there right now.
Its strong in reasoning, web browsing, agent use cases, and coding.
It also has the lowest hallucination rate of any model right now as well.
The few places we see it falter are the same places where GPT has been weak and Claude has been strong: personality, writing style, and design.
We can see this in benchmarks like Design Arena, where GPT 5.4 places 18th, behind Claude, Gemini, and even some of the Chinese LLMs as well.
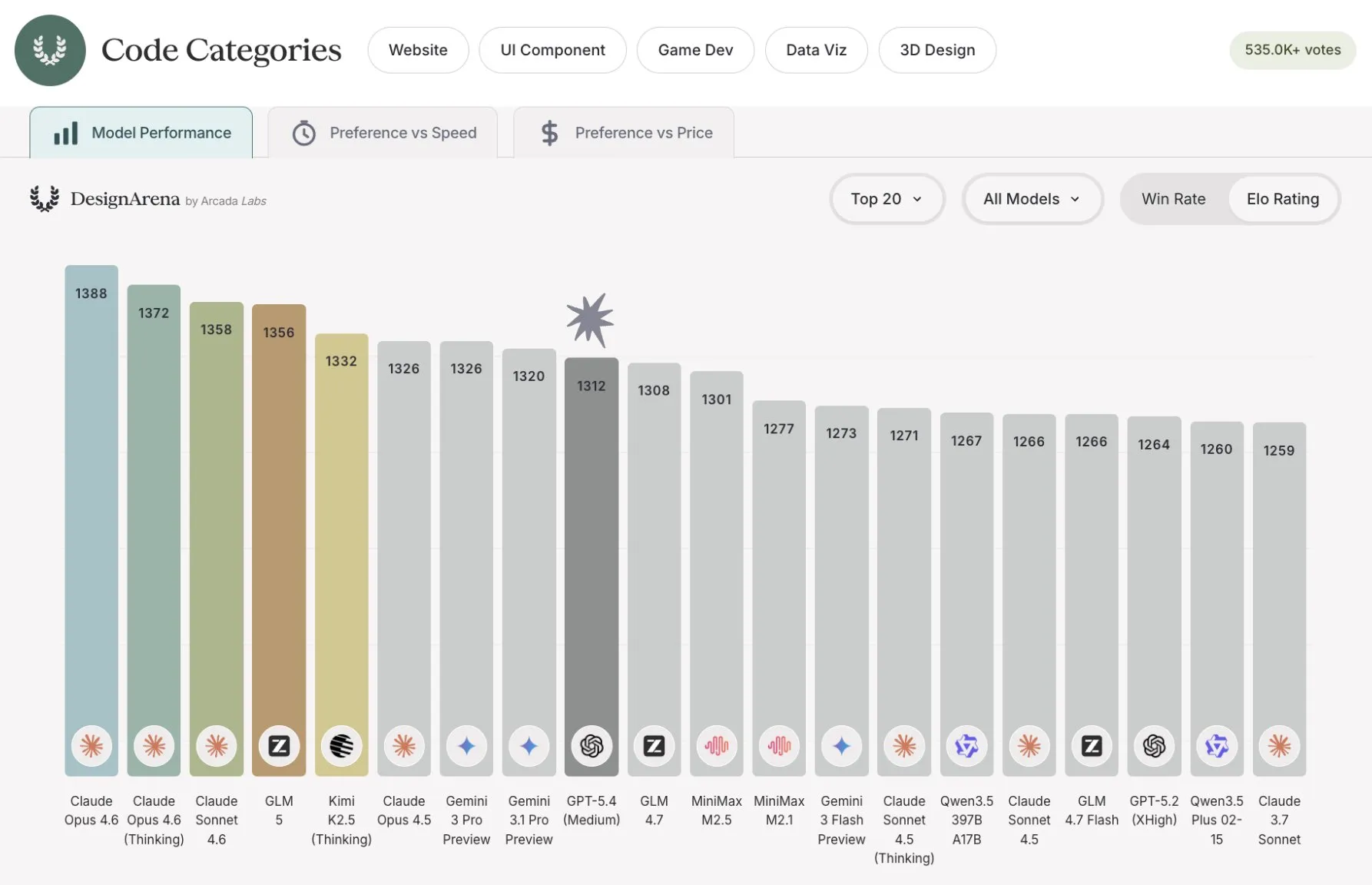
It also falters to its coding focused predecessor, GPT 5.3 Codex, as well.
It has better code writing style and intent understanding (although still not as good as Claude for vibe coding), but it does not seem to have the same allergy to bugs that 5.3 had.
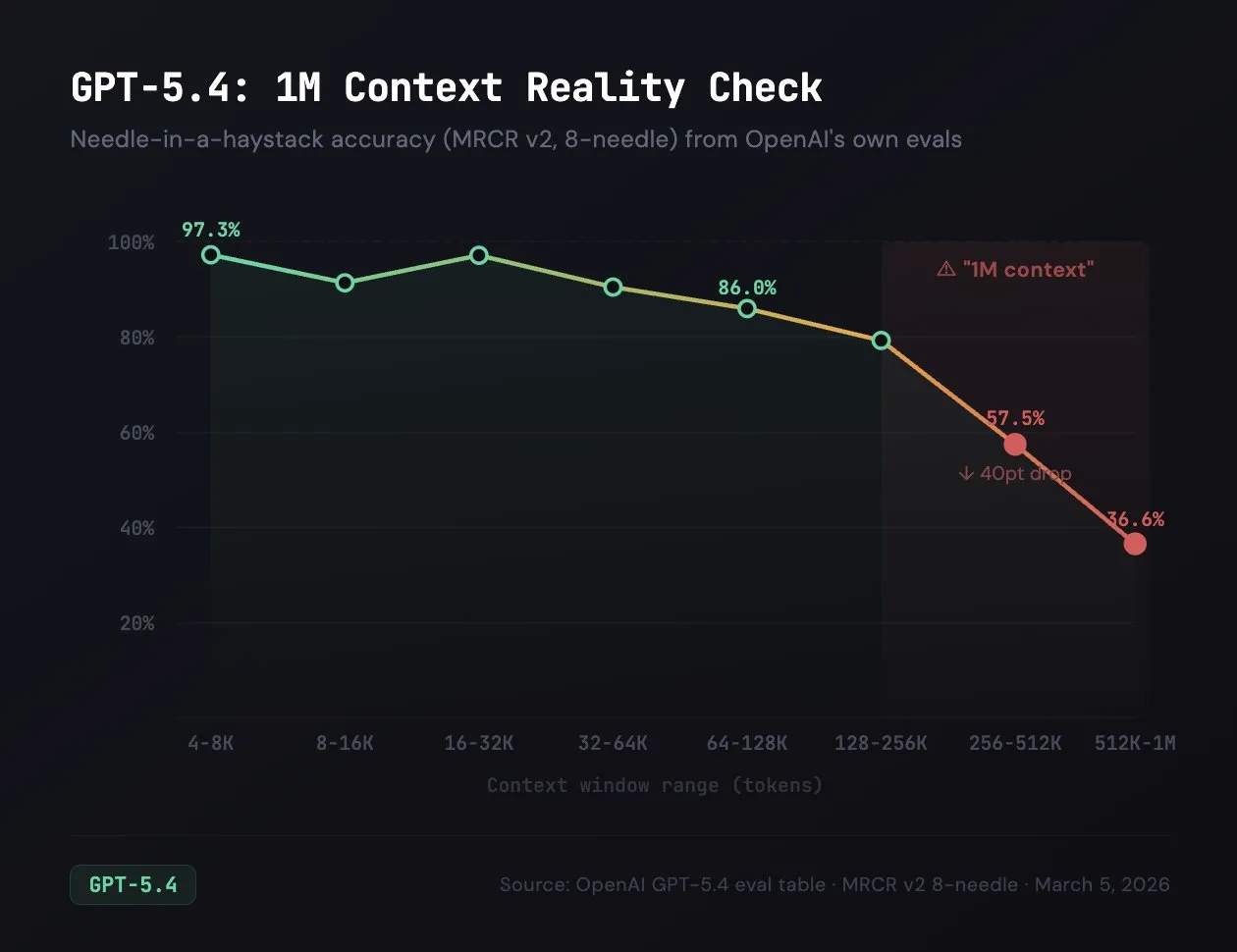
OpenAI are also releasing an experimental 1 million context length version of the model as well, roughly quadrupling the number of tokens you can feed into the model.
Just because they have this feature though does not mean it is good, as even OpenAI’s benchmarks show that there is massive quality dropoff once you pass the 256k threshold.
Because of this I would recommend staying away from the one million context version, especially since tokens over 256k are charged double.
Speaking of pricing, that is another thing that has changed.
Due to “increased model capabilities”, OpenAI has decided to raise the prices for the model similar to what they did for GPT 5.2.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| GPT 5.4 | $2.50 | $15 | 50 |
| GPT 5.2 | $1.75 | $14 | 46 |
| GPT 5 | $1.25 | $10 | 46 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| Gemini 3.1 Pro | $2 | $12 | 80 |
| Gemini 3 Flash | $0.50 | $3 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
This means that since the original GPT 5 release, input token pricing has doubled and output pricing has gone up 50%.
They are still much cheaper than Opus, but are now priced similarly to Sonnet, opening the door a bit for Anthropic to compete.
Overall GPT 5.4 is a very strong model, and I highly recommend checking it out for regular day to day tasks, agentic uses, and for coding.
Qwen 3.5 Small
Qwen released the models for its final size in its new Qwen 3.5 lineup, being the Qwen 3.5 small models.
We are getting 4 different models, with sizes 0.8B, 2B, 4B, and 9 billion parameters, all of which are regular non-mixture-of-experts models.
Like all of the other models in the Qwen 3.5 lineup, they are hybrid reasoning models (you can turn reasoning on and off) and also naively support multimodal inputs.
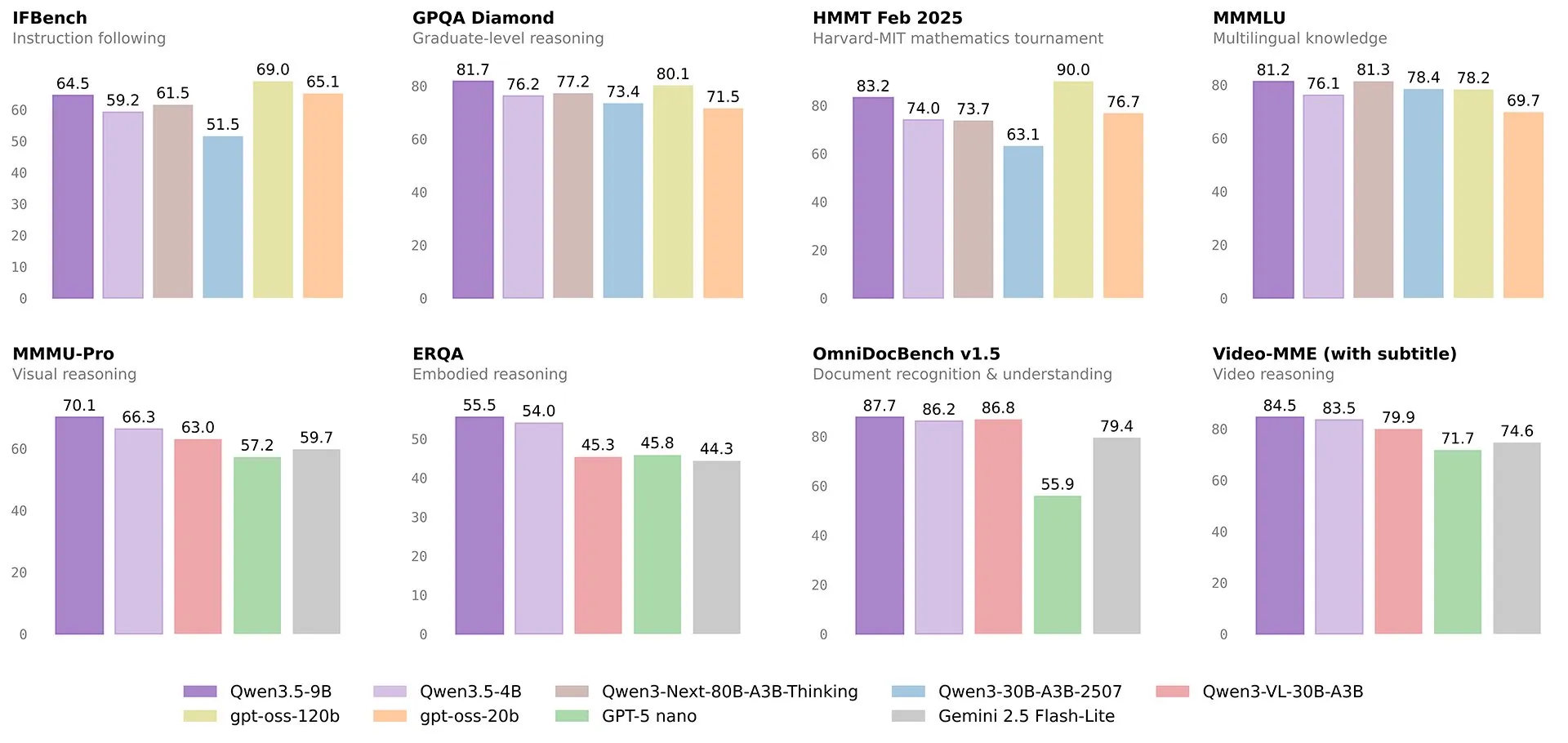
They have been drawing comparisons to GPT 4o (a trillion+ param model that was state of the art 2 years ago), specifically about how they are straight up better than it across most intelligence benchmarks, while also being far stronger agentic models as well.
The somewhat awkward thing for them however, is that they are not actually the best small model out there right now.
That title is still given to Nanbeige, which on benchmarks that have been released in the previous 2 weeks (they can’t overfit on benchmarks that were not released yet) it handily beats the new Qwen 4B and 9B models, all while its only 3B params itself.
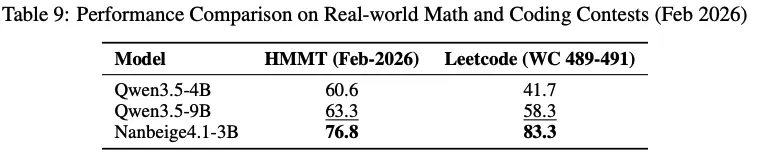
That is not to say that the Qwen models are useless.
NanBeige tends to think for a long time before answering even simple queries (with no way of turning reasoning off) and also does not have multimodal support.
So if you enjoy running models at home (or on your phone) I would still check out these new small Qwen 3.5 models.
Quick Hits
GPT 5.3 Instant
In a perplexing turn of events, OpenAI released both GPT 5.4 and 5.3 this week.
This is because it is their instant model, which is primarily seen if you are on the ChatGPT free plan.
This is the non reasoning model for the GPT 5 family (previously called minimal reasoning), and has historically been far worse than its contemplative brothers.
With this release, I think OpenAI is trying to show that this model is completely separate from their GPT 5.4 model, and not just a lower reasoning level, but rather an entirely different (smaller) model.
The model is nothing to write home about, whenever you see ChatGPT acting stupid, it is usually the instant model.
This release seems to improve the personality and writing style of the model a bit, and they also claim that they have lowered the hallucination rate of the model (with no benchmarks to back this up).
For the benchmarks they do release, there is little to no change from previous versions of the model.
Because of this, I implore you to use GPT 5.4 whenever you can and to avoid the instant model for all but your simplest queries.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
The shape store by a.i.solation on TikTok Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
GPT 5.4
A OpenAI lançou uma atualização para sua série de modelos GPT 5 esta semana.
O GPT 5.4 é o seu mais recente modelo de raciocínio, pulando o GPT 5.3, pois suas capacidades ampliadas justificam um salto de versão maior que 0.1, segundo a OpenAI.
Novo truque de benchmark: deixe os concorrentes em cinza
O GPT 5.3 Codex já estava empatado com o Opus 4.6 para casos de uso em programação, mas ficou para trás em casos de uso mais gerais do dia a dia.
O GPT 5.4 parece corrigir esses problemas para ser o melhor modelo disponível, e, salvo alguns casos de uso específicos, eles parecem ter conseguido.
Em termos de inteligência bruta e capacidade de realizar tarefas, o GPT 5.4 é o melhor modelo disponível no momento.
É forte em raciocínio, navegação na web, casos de uso com agentes e programação.
Também possui a menor taxa de alucinação de qualquer modelo atualmente.
Os poucos pontos onde o modelo falha são os mesmos onde o GPT tem sido fraco e o Claude tem se destacado: personalidade, estilo de escrita e design.
Podemos ver isso em benchmarks como o Design Arena, onde o GPT 5.4 ocupa o 18º lugar, atrás do Claude, do Gemini e até de alguns LLMs chineses.
Ele também fica atrás de seu predecessor focado em programação, o GPT 5.3 Codex.
Tem um melhor estilo de escrita de código e compreensão de intenção (embora ainda não tão bom quanto o Claude para vibe coding), mas não parece ter a mesma aversão a bugs que o 5.3 tinha.
A OpenAI também está lançando uma versão experimental do modelo com 1 milhão de tokens de contexto, aproximadamente quadruplicando o número de tokens que podem ser fornecidos ao modelo.
Porém, só porque possuem esse recurso não significa que ele seja bom, pois até mesmo os benchmarks da própria OpenAI mostram uma queda massiva de qualidade após ultrapassar o limite de 256k tokens.
Por isso, recomendo evitar a versão de um milhão de contexto, especialmente porque os tokens acima de 256k são cobrados em dobro.
Falando em preços, esse é outro aspecto que mudou.
Devido ao “aumento nas capacidades do modelo”, a OpenAI decidiu elevar os preços de forma semelhante ao que fez com o GPT 5.2.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| GPT 5.4 | $2,50 | $15 | 50 |
| GPT 5.2 | $1,75 | $14 | 46 |
| GPT 5 | $1,25 | $10 | 46 |
| Claude Sonnet 4.5 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GLM 5 | $1 | $3,20 | 21 |
| MiniMax M2.5 | $0,30 | $1,20 | 27 |
Isso significa que, desde o lançamento original do GPT 5, o preço dos tokens de entrada dobrou e o preço dos tokens de saída subiu 50%.
Ainda são muito mais baratos que o Opus, mas agora têm preços similares ao Sonnet, abrindo um pouco mais espaço para a Anthropic competir.
No geral, o GPT 5.4 é um modelo muito forte, e recomendo fortemente experimentá-lo para tarefas do dia a dia, usos agênticos e programação.
Qwen 3.5 Small
A Qwen lançou os modelos para o último tamanho de sua nova linha Qwen 3.5, sendo os modelos Qwen 3.5 small.
Estamos recebendo 4 modelos diferentes, com tamanhos de 0,8B, 2B, 4B e 9 bilhões de parâmetros, todos modelos regulares sem mistura de especialistas (non-mixture-of-experts).
Assim como todos os outros modelos da linha Qwen 3.5, são modelos de raciocínio híbrido (é possível ativar e desativar o raciocínio) e também suportam entradas multimodais nativamente.
Eles têm sido comparados ao GPT 4o (um modelo com mais de um trilhão de parâmetros que era o estado da arte há 2 anos), especificamente sobre como são simplesmente melhores que ele na maioria dos benchmarks de inteligência, além de serem modelos agênticos muito mais robustos.
O aspecto um tanto incômodo, porém, é que eles não são realmente os melhores modelos pequenos disponíveis no momento.
Esse título ainda pertence ao Nanbeige, que em benchmarks lançados nas últimas 2 semanas (impossível de ajustar para benchmarks que ainda não existiam) ele supera com folga os novos modelos Qwen de 4B e 9B, tudo isso com apenas 3B de parâmetros.
Isso não significa que os modelos Qwen sejam inúteis.
O NanBeige tende a pensar por um longo tempo antes de responder até mesmo consultas simples (sem possibilidade de desativar o raciocínio) e também não possui suporte multimodal.
Portanto, se você gosta de executar modelos em casa (ou no celular), ainda recomendo conferir esses novos modelos pequenos Qwen 3.5.
Destaques Rápidos
GPT 5.3 Instant
Em um desdobramento intrigante, a OpenAI lançou tanto o GPT 5.4 quanto o 5.3 esta semana.
Isso porque o 5.3 é o modelo instant, visto principalmente por quem usa o plano gratuito do ChatGPT.
Este é o modelo sem raciocínio da família GPT 5 (anteriormente chamado de raciocínio mínimo), e historicamente tem sido muito inferior aos seus irmãos contemplativos.
Com este lançamento, acredito que a OpenAI está tentando mostrar que esse modelo é completamente separado do GPT 5.4, e não apenas um nível de raciocínio mais baixo, mas sim um modelo inteiramente diferente (e menor).
O modelo não tem nada de especial; sempre que você vê o ChatGPT agindo de forma estranha, geralmente é o modelo instant.
Este lançamento parece melhorar um pouco a personalidade e o estilo de escrita do modelo, e eles também afirmam ter reduzido a taxa de alucinação (sem benchmarks para comprovar).
Para os benchmarks que divulgam, há pouca ou nenhuma mudança em relação às versões anteriores do modelo.
Por isso, imploro que você use o GPT 5.4 sempre que possível e evite o modelo instant para tudo, exceto suas consultas mais simples.
Encerramento
Espero que você tenha gostado das novidades desta semana. Se quiser receber as notícias toda semana, não deixe de se inscrever em nossa lista de e-mails abaixo.
The shape store por a.i.solation no TikTok Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
GPT 5.4
OpenAI lanzó una actualización de su serie de modelos GPT 5 esta semana.
GPT 5.4 es su último modelo de razonamiento, saltándose GPT 5.3 ya que sus mayores capacidades justifican un incremento de versión superior a 0.1, según OpenAI.
Nuevo truco de benchmarking: deja en gris a tus competidores
GPT 5.3 Codex ya estaba empatado con Opus 4.6 en casos de uso de programación, pero quedaba rezagado en casos de uso más generales del día a día.
GPT 5.4 busca corregir estos problemas para convertirse en el mejor modelo disponible y, salvo en algunos pocos casos de uso, parece haberlo logrado.
En términos de inteligencia bruta y capacidad para hacer las cosas, GPT 5.4 es el mejor modelo disponible ahora mismo.
Es sólido en razonamiento, navegación web, casos de uso agénticos y programación.
También tiene la tasa de alucinaciones más baja de cualquier modelo en este momento.
Los pocos puntos débiles que observamos son los mismos en los que GPT ha sido débil y Claude ha sido fuerte: personalidad, estilo de escritura y diseño.
Podemos verlo en benchmarks como Design Arena, donde GPT 5.4 ocupa el puesto 18, por detrás de Claude, Gemini e incluso algunos de los LLMs chinos.
También queda por detrás de su predecesor enfocado en código, GPT 5.3 Codex.
Tiene un mejor estilo de escritura de código y mayor comprensión de la intención (aunque todavía no tan bueno como Claude para el vibe coding), pero no parece tener la misma aversión a los bugs que tenía el 5.3.
OpenAI también está lanzando una versión experimental del modelo con un contexto de 1 millón de tokens, lo que cuadruplica aproximadamente la cantidad de tokens que se pueden introducir en el modelo.
Sin embargo, el hecho de que tengan esta característica no significa que sea buena, ya que incluso los propios benchmarks de OpenAI muestran una caída masiva de calidad una vez que se supera el umbral de 256k tokens.
Por ello, recomendaría mantenerse alejado de la versión de un millón de contexto, especialmente porque los tokens por encima de 256k se cobran al doble.
Hablando de precios, eso es otra cosa que ha cambiado.
Debido a las “mayores capacidades del modelo”, OpenAI ha decidido subir los precios de forma similar a lo que hizo con GPT 5.2.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| GPT 5.4 | $2.50 | $15 | 50 |
| GPT 5.2 | $1.75 | $14 | 46 |
| GPT 5 | $1.25 | $10 | 46 |
| Claude Sonnet 4.5 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
Esto significa que desde el lanzamiento original de GPT 5, el precio de los tokens de entrada se ha duplicado y el precio de salida ha aumentado un 50%.
Siguen siendo mucho más baratos que Opus, pero ahora tienen un precio similar a Sonnet, lo que abre un poco la puerta para que Anthropic compita.
En general, GPT 5.4 es un modelo muy sólido, y lo recomiendo ampliamente para tareas cotidianas, usos agénticos y programación.
Qwen 3.5 Small
Qwen lanzó los modelos del tamaño final de su nueva línea Qwen 3.5, los modelos Qwen 3.5 small.
Obtenemos 4 modelos diferentes, con tamaños de 0.8B, 2B, 4B y 9 mil millones de parámetros, todos ellos modelos regulares sin mezcla de expertos.
Al igual que todos los demás modelos de la línea Qwen 3.5, son modelos de razonamiento híbrido (puedes activar y desactivar el razonamiento) y también soportan entradas multimodales de forma nativa.
Se han estado comparando con GPT 4o (un modelo de más de un billón de parámetros que era el estado del arte hace 2 años), específicamente en cuanto a cómo son directamente superiores en la mayoría de los benchmarks de inteligencia, además de ser modelos agénticos mucho más potentes.
Sin embargo, lo algo incómodo para ellos es que en realidad no son el mejor modelo pequeño disponible en este momento.
Ese título sigue siendo de Nanbeige, que en los benchmarks publicados en las últimas 2 semanas (no pueden sobreajustarse a benchmarks que aún no habían sido lanzados) supera con claridad a los nuevos modelos Qwen 4B y 9B, y todo ello con solo 3B de parámetros.
Esto no quiere decir que los modelos Qwen sean inútiles.
NanBeige tiende a pensar durante mucho tiempo antes de responder incluso a consultas simples (sin posibilidad de desactivar el razonamiento) y tampoco tiene soporte multimodal.
Así que si disfrutas ejecutando modelos en casa (o en tu teléfono), te recomiendo que pruebes estos nuevos modelos pequeños Qwen 3.5.
Noticias Rápidas
GPT 5.3 Instant
En un giro desconcertante, OpenAI lanzó tanto GPT 5.4 como 5.3 esta semana.
Esto se debe a que es su modelo instant, que se utiliza principalmente si estás en el plan gratuito de ChatGPT.
Este es el modelo sin razonamiento de la familia GPT 5 (anteriormente denominado razonamiento mínimo), y históricamente ha sido mucho peor que sus hermanos más reflexivos.
Con este lanzamiento, creo que OpenAI está intentando mostrar que este modelo es completamente independiente de su modelo GPT 5.4, y no simplemente un nivel de razonamiento inferior, sino un modelo completamente diferente (y más pequeño).
El modelo no es nada del otro mundo; cuando ves a ChatGPT comportándose de forma torpe, generalmente es el modelo instant.
Este lanzamiento parece mejorar un poco la personalidad y el estilo de escritura del modelo, y también afirman haber reducido la tasa de alucinaciones (sin benchmarks que lo respalden).
En cuanto a los benchmarks que sí publican, hay muy pocos o ningún cambio respecto a versiones anteriores del modelo.
Por todo esto, te imploro que uses GPT 5.4 siempre que puedas y que evites el modelo instant para todo excepto tus consultas más simples.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
The shape store por a.i.solation en TikTok