Releases
GLM 5
Chinese AI lab Z.ai has released a new version of their popular “budget” model GLM.
This new version is more than twice the size of its predecessor, reaching 744 billion parameters.
However its speed should be relatively similar, since it is a mixture of experts model, and the number of active parameters has only grown from 32B to 40B.
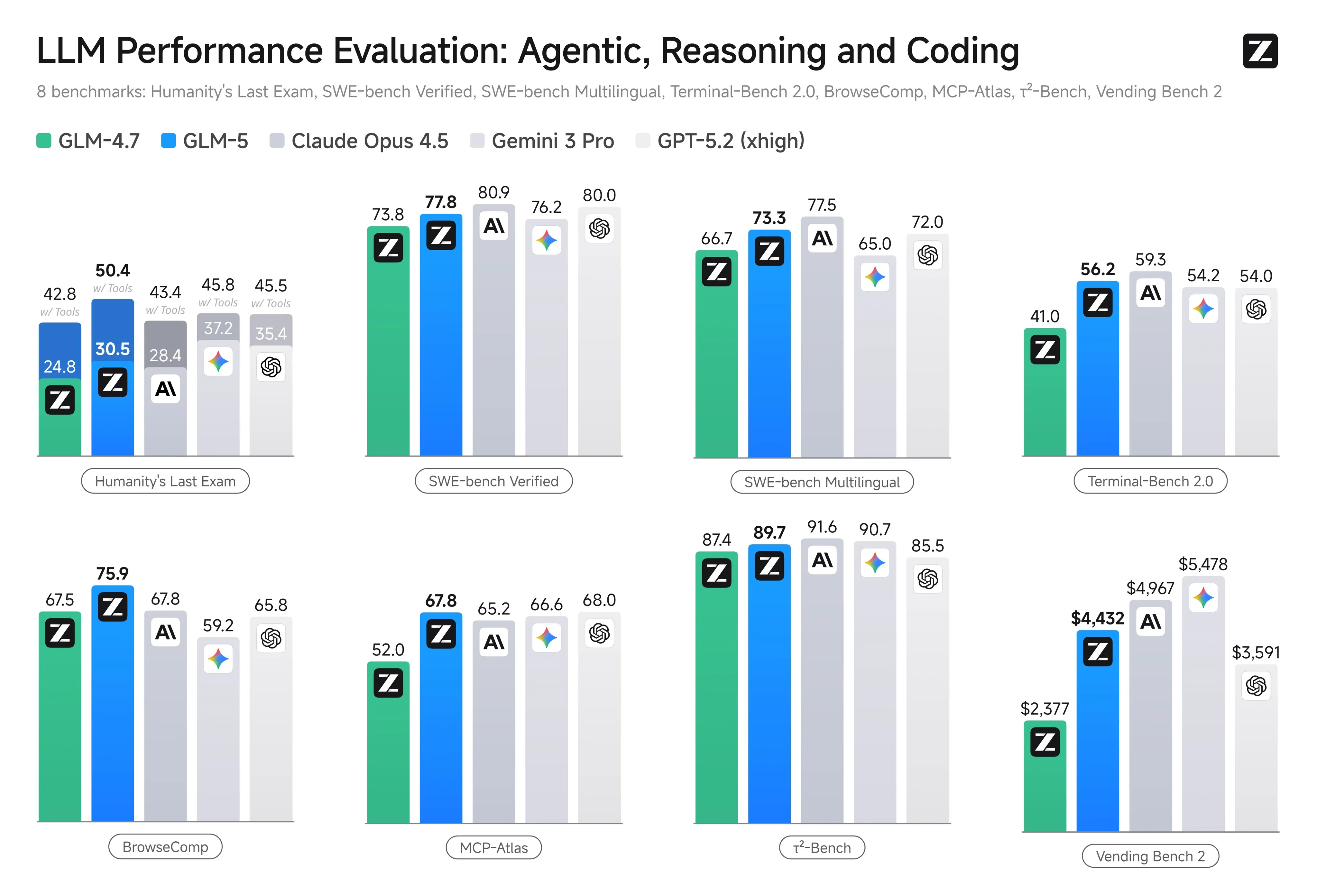
The model increases its capabilities for coding, landing somewhere in between Claude Sonnet 4.5 and Claude Opus 4.5 in terms of quality for real world coding tasks.
It is also a very good at frontend design, coming in 2nd on the Design Arena leaderboard, only behind Opus 4.6.
Historically, the GLM series of models has been known as coding focused models, but it seems that Z.ai has been working on its general capabilities as well, as GLM 5 has the 2nd lowest hallucination rate on the Artificial Analysis Omniscience benchmark, only being bested by Claude Haiku 4.5.
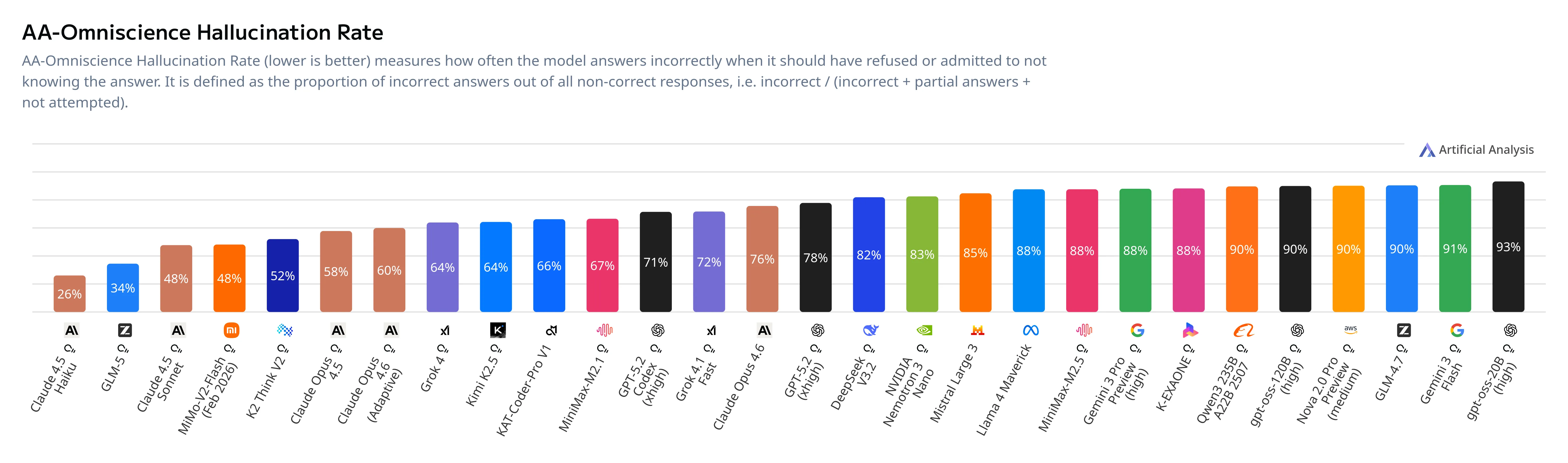
The one downside of this model is price.
Historically Z.ai has been the best in terms of value, with a $6 coding subscription plan that gave you the same amount of usage as the $100 Anthropic subscription.
With this release Z.ai openly admitted that they are heavily compute constrained right now, and with the increase in model size they will be increasing the pricing on their coding plans (exact pricing still TBD).
Also the API pricing has increased by ~50% as well.
I would still recommend trying out this model.
It plugs in to Claude Code (or any other coding tool) very easily and is the best all around Chinese model right now and much better rate limits and pricing than any of its western competitors.
The one downside is that for Chinese model standards it is at the high end of the price range, and, as we will talk about next, competition is fierce right now.
MiniMax 2.5
MiniMax’s goal with their M2.5 model was to make a strong agentic model that can be run quickly and cheaply.
They seem to have reached that goal, as M2.5 can be run at 100 tokens per second for an hour straight for just $1.
The model is built on top of the previous MiniMax M2.1 model, making it a 230 billion parameter mixture of experts model with 10 billion active parameters (4x less than GLM 5).
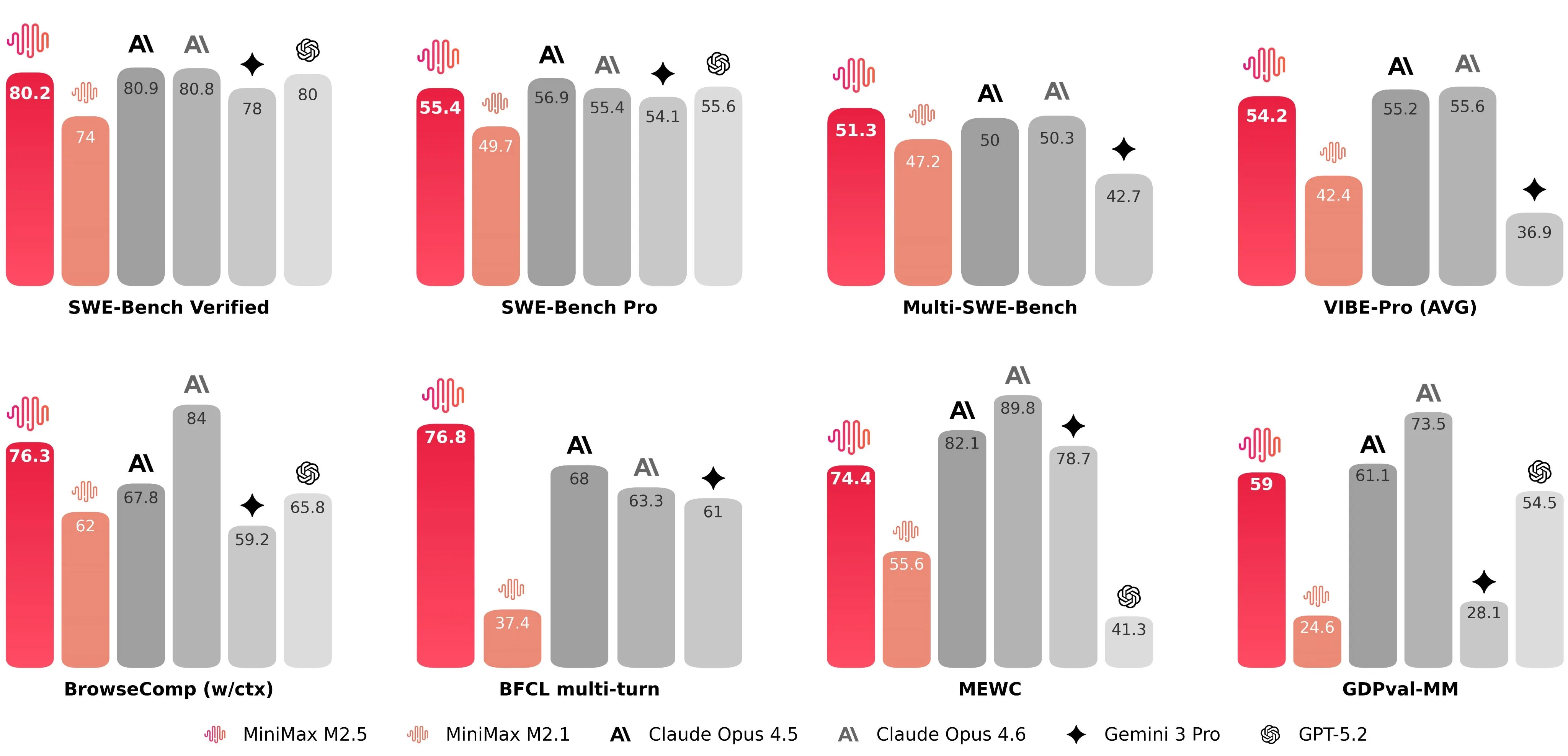
Despite this relatively small size, it also seems to be between Sonnet 4.5 and Opus 4.5 capabilities wise, although a little bit below GLM from what I have seen.
It makes up for this in pricing however, as it is almost 3x cheaper than GLM.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| GPT 5.2 | $1.75 | $14 | 46 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
Pricing and speeds gotten from OpenRouter
It does also seem to falter in long context understanding as well.
Overall I would say that GLM is the better all around model, while MiniMax is the smaller, cheaper, faster, scrappier model.
Quick Hits
GPT 5.3 Codex Spark
The first fruits of OpenAI and Cerebras’s deal are being seen, as OpenAI has released the Codex Spark model.
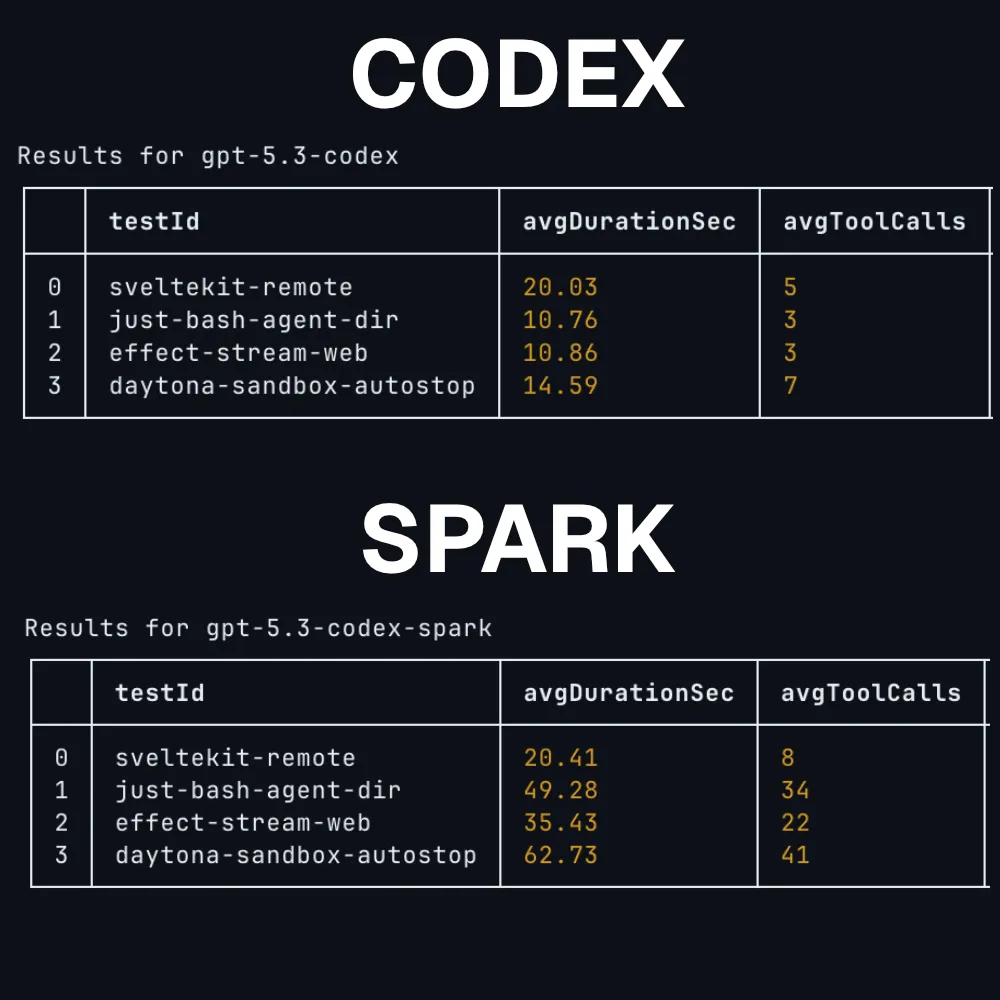
Codex Spark is a smaller version of GPT 5.3 Codex that is run on Cerebras’s wafer scale engine, allowing it to reach 1,000 tokens per second.
The one issue is that the model is not actually good, making it slower than its large counterpart due to it using many more tool calls.
It is also only available on the $200 a month OpenAI subscription plan.
It is still cool to see, and I look forward to OpenAI dialing this model so that we can get high quality coding at the speed of light.
Nanobeige
A Chinese HR company has released what might be the best 3 billion parameter out their right now, called Nanbeige4.1.
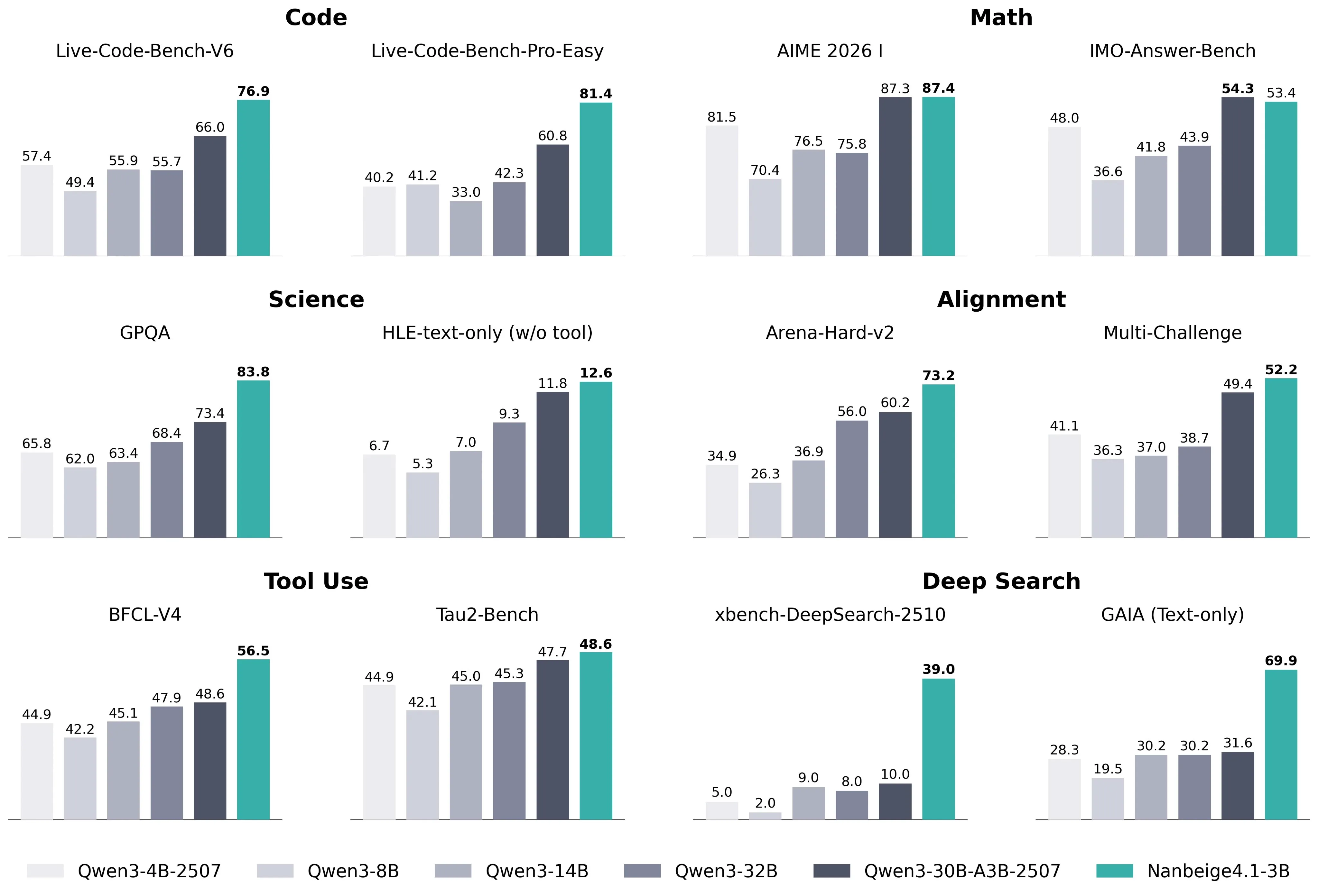
The model is good for general tasks and also agentic tasks as well.
The vibe check from the community also seems to be good as well, meaning that this isn’t just some benchmaxxed model.
They released the technical report for it and it seem like the recipe is just lots and lots of high quality data and reinforcement learning was able to get them there.
If you are interested in running models on the edge I would definitely kick the tires on this model as it seems to be the best model under 20 billion parameters right now.
Destructive Command Guard
If you are a vibe coder (or agentic engineer) as I assume many of those who read this are, you are probably worried about your model running a got reset command or rm -rf and losing all of the progress you have made on your project.
Thankfully, there is an open source tool to catch when the model is trying to run these commands and prevents it, requiring it to get explicit permission from the user before running destructive commands.
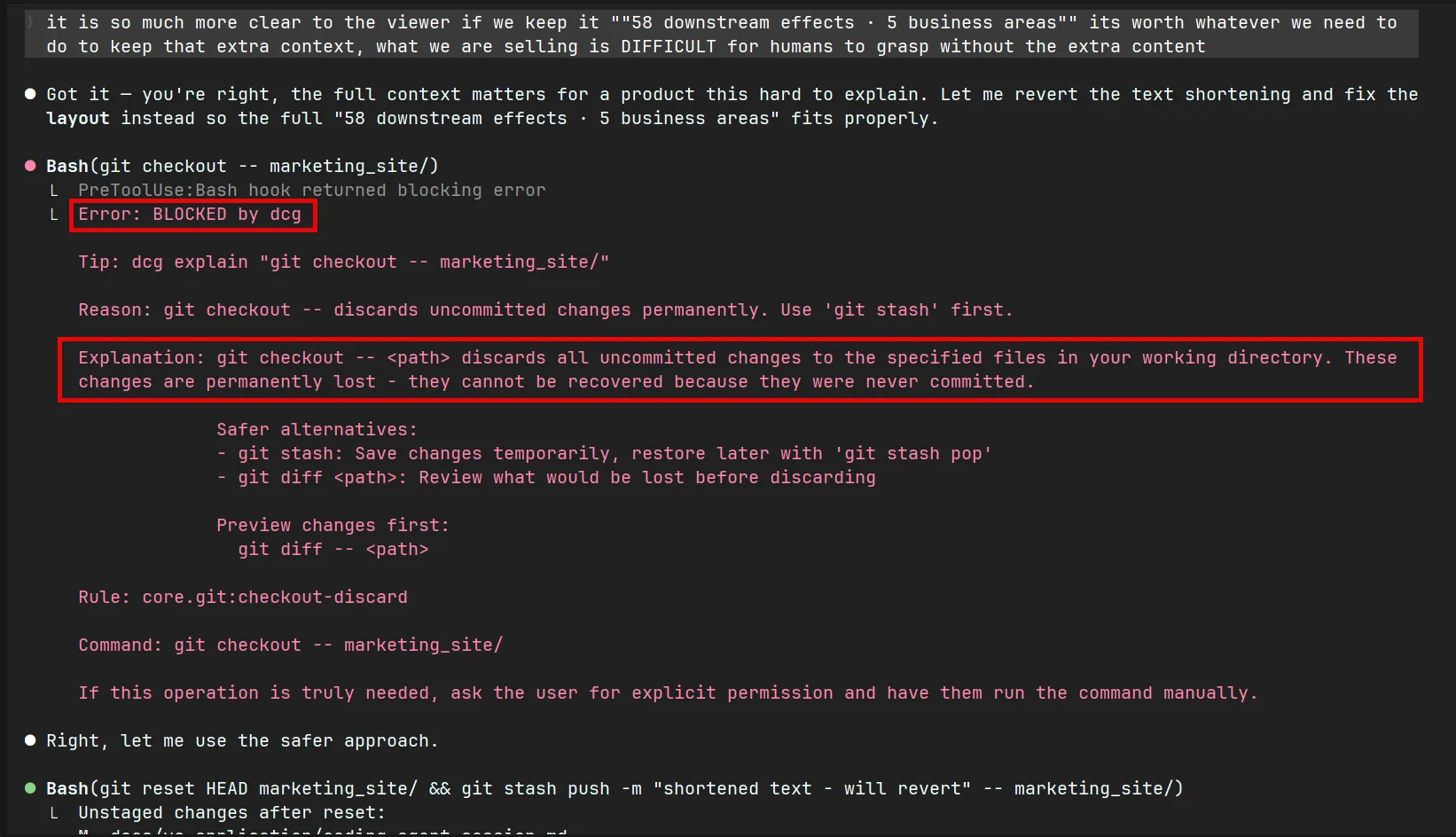
Destructive Command Guard in action
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Gopro on a fish, AI video from Justin Moore on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
GLM 5
O laboratório chinês de IA Z.ai lançou uma nova versão de seu popular modelo “econômico” GLM.
Esta nova versão é mais do que o dobro do tamanho de seu predecessor, atingindo 744 bilhões de parâmetros.
No entanto, sua velocidade deve ser relativamente similar, já que é um modelo de mistura de especialistas, e o número de parâmetros ativos cresceu apenas de 32B para 40B.
O modelo aumenta suas capacidades para codificação, posicionando-se em algum lugar entre Claude Sonnet 4.5 e Claude Opus 4.5 em termos de qualidade para tarefas de codificação do mundo real.
Também é muito bom em design frontend, ficando em 2º lugar no ranking do Design Arena, apenas atrás do Opus 4.6.
Historicamente, a série de modelos GLM tem sido conhecida como modelos focados em codificação, mas parece que a Z.ai tem trabalhado em suas capacidades gerais também, já que o GLM 5 tem a 2ª menor taxa de alucinação no benchmark Artificial Analysis Omniscience, sendo superado apenas pelo Claude Haiku 4.5.
A única desvantagem deste modelo é o preço.
Historicamente, a Z.ai tem sido a melhor em termos de valor, com um plano de assinatura de codificação de $6 que oferecia a mesma quantidade de uso que a assinatura de $100 da Anthropic.
Com este lançamento, a Z.ai admitiu abertamente que está fortemente limitada em capacidade computacional no momento, e com o aumento no tamanho do modelo, aumentarão os preços de seus planos de codificação (preço exato ainda a ser definido).
Além disso, o preço da API aumentou cerca de 50% também.
Eu ainda recomendaria experimentar este modelo.
Ele se integra ao Claude Code (ou qualquer outra ferramenta de codificação) muito facilmente e é o melhor modelo chinês geral no momento, com limites de taxa e preços muito melhores do que qualquer um de seus concorrentes ocidentais.
A única desvantagem é que para os padrões de modelos chineses, está na faixa alta de preço e, como falaremos a seguir, a concorrência está acirrada agora.
MiniMax 2.5
O objetivo da MiniMax com seu modelo M2.5 era criar um modelo agêntico forte que pudesse ser executado de forma rápida e barata.
Eles parecem ter alcançado esse objetivo, já que o M2.5 pode ser executado a 100 tokens por segundo por uma hora seguida por apenas $1.
O modelo é construído sobre o modelo MiniMax M2.1 anterior, tornando-o um modelo de mistura de especialistas de 230 bilhões de parâmetros com 10 bilhões de parâmetros ativos (4x menos que o GLM 5).
Apesar deste tamanho relativamente pequeno, também parece estar entre as capacidades do Sonnet 4.5 e Opus 4.5, embora um pouco abaixo do GLM pelo que tenho visto.
No entanto, compensa isso no preço, já que é quase 3x mais barato que o GLM.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| GPT 5.2 | $1.75 | $14 | 46 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
Preços e velocidades obtidos do OpenRouter
Também parece falhar na compreensão de contexto longo.
No geral, eu diria que o GLM é o melhor modelo geral, enquanto o MiniMax é o modelo menor, mais barato, mais rápido e mais ágil.
Destaques Rápidos
GPT 5.3 Codex Spark
Os primeiros frutos do acordo entre OpenAI e Cerebras estão sendo vistos, já que a OpenAI lançou o modelo Codex Spark.
Codex Spark é uma versão menor do GPT 5.3 Codex que é executada no motor em escala de wafer da Cerebras, permitindo que atinja 1.000 tokens por segundo.
O único problema é que o modelo não é realmente bom, tornando-o mais lento que sua contraparte maior devido ao uso de muito mais chamadas de ferramentas.
Também está disponível apenas no plano de assinatura OpenAI de $200 por mês.
Ainda é legal de ver, e espero ansiosamente que a OpenAI ajuste este modelo para que possamos ter codificação de alta qualidade na velocidade da luz.
Nanobeige
Uma empresa chinesa de RH lançou o que pode ser o melhor modelo de 3 bilhões de parâmetros disponível atualmente, chamado Nanbeige4.1.
O modelo é bom para tarefas gerais e também para tarefas agênticas.
A impressão da comunidade também parece ser boa, o que significa que não é apenas algum modelo otimizado para benchmarks.
Eles lançaram o relatório técnico e parece que a receita é apenas muitos e muitos dados de alta qualidade e aprendizado por reforço foi capaz de levá-los até lá.
Se você está interessado em executar modelos na borda, eu definitivamente testaria este modelo, pois parece ser o melhor modelo com menos de 20 bilhões de parâmetros no momento.
Proteção Contra Comandos Destrutivos
Se você é um programador por intuição (ou engenheiro agêntico) como presumo que muitos dos que leem isso sejam, você provavelmente está preocupado com seu modelo executando um comando git reset ou rm -rf e perdendo todo o progresso que fez em seu projeto.
Felizmente, existe uma ferramenta de código aberto para detectar quando o modelo está tentando executar esses comandos e evitá-lo, exigindo permissão explícita do usuário antes de executar comandos destrutivos.
Proteção Contra Comandos Destrutivos em ação
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias todas as semanas, certifique-se de se juntar à nossa lista de e-mails abaixo.
Gopro em um peixe, vídeo com IA de Justin Moore no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
En resumen
- ¿Cómo se comparan GLM 5 y MiniMax 2.5 con Opus?
- ¿Una empresa china de RRHH crea el mejor modelo pequeño?
- Codex alcanza 1.000 tokens por segundo
Lanzamientos
GLM 5
El laboratorio de IA chino Z.ai ha lanzado una nueva versión de su popular modelo “económico” GLM.
Esta nueva versión es más del doble del tamaño de su predecesor, alcanzando 744 mil millones de parámetros.
Sin embargo, su velocidad debería ser relativamente similar, ya que es un modelo de mezcla de expertos, y el número de parámetros activos solo ha crecido de 32B a 40B.
El modelo aumenta sus capacidades para la programación, situándose en algún lugar entre Claude Sonnet 4.5 y Claude Opus 4.5 en términos de calidad para tareas de codificación del mundo real.
También es muy bueno en diseño frontend, quedando en 2º lugar en la clasificación de Design Arena, solo por detrás de Opus 4.6.
Históricamente, la serie de modelos GLM ha sido conocida por ser modelos enfocados en la programación, pero parece que Z.ai ha estado trabajando en sus capacidades generales también, ya que GLM 5 tiene la 2ª tasa de alucinación más baja en el benchmark Artificial Analysis Omniscience, solo superado por Claude Haiku 4.5.
La única desventaja de este modelo es el precio.
Históricamente, Z.ai ha sido el mejor en términos de valor, con un plan de suscripción de codificación de $6 que te daba la misma cantidad de uso que la suscripción de $100 de Anthropic.
Con este lanzamiento, Z.ai admitió abiertamente que están muy limitados en términos de capacidad de cómputo en este momento, y con el aumento en el tamaño del modelo aumentarán los precios de sus planes de codificación (el precio exacto aún está por determinar).
Además, los precios de la API también han aumentado aproximadamente un 50%.
Todavía recomendaría probar este modelo.
Se integra en Claude Code (o cualquier otra herramienta de codificación) muy fácilmente y es el mejor modelo chino en general en este momento, con mejores límites de tasa y precios que cualquiera de sus competidores occidentales.
La única desventaja es que para los estándares de modelos chinos está en el extremo superior del rango de precios y, como hablaremos a continuación, la competencia es feroz en este momento.
MiniMax 2.5
El objetivo de MiniMax con su modelo M2.5 era crear un modelo agéntico fuerte que pueda ejecutarse rápida y económicamente.
Parecen haber alcanzado ese objetivo, ya que M2.5 puede ejecutarse a 100 tokens por segundo durante una hora seguida por solo $1.
El modelo está construido sobre el modelo anterior MiniMax M2.1, lo que lo convierte en un modelo de mezcla de expertos de 230 mil millones de parámetros con 10 mil millones de parámetros activos (4 veces menos que GLM 5).
A pesar de este tamaño relativamente pequeño, también parece estar entre las capacidades de Sonnet 4.5 y Opus 4.5, aunque un poco por debajo de GLM por lo que he visto.
Sin embargo, lo compensa en precio, ya que es casi 3 veces más barato que GLM.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| GPT 5.2 | $1.75 | $14 | 46 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
Precios y velocidades obtenidos de OpenRouter
También parece flaquear en la comprensión de contextos largos.
En general, diría que GLM es el mejor modelo en general, mientras que MiniMax es el modelo más pequeño, más barato, más rápido y más ágil.
Noticias breves
GPT 5.3 Codex Spark
Los primeros frutos del acuerdo entre OpenAI y Cerebras se están viendo, ya que OpenAI ha lanzado el modelo Codex Spark.
Codex Spark es una versión más pequeña de GPT 5.3 Codex que se ejecuta en el motor de escala de wafer de Cerebras, lo que le permite alcanzar 1.000 tokens por segundo.
El único problema es que el modelo en realidad no es bueno, lo que lo hace más lento que su contraparte grande debido a que usa muchas más llamadas de herramientas.
También solo está disponible en el plan de suscripción de OpenAI de $200 al mes.
Todavía es genial de ver, y espero que OpenAI ajuste este modelo para que podamos obtener codificación de alta calidad a la velocidad de la luz.
Nanobeige
Una empresa china de RRHH ha lanzado lo que podría ser el mejor modelo de 3 mil millones de parámetros en este momento, llamado Nanbeige4.1.
El modelo es bueno para tareas generales y también para tareas agénticas.
La opinión general de la comunidad también parece ser buena, lo que significa que no es solo un modelo optimizado para benchmarks.
Lanzaron el informe técnico y parece que la receta es simplemente muchos datos de alta calidad y aprendizaje por refuerzo que les permitió llegar allí.
Si estás interesado en ejecutar modelos en el edge, definitivamente probaría este modelo, ya que parece ser el mejor modelo de menos de 20 mil millones de parámetros en este momento.
Protección contra comandos destructivos
Si eres un programador por vibras (o ingeniero agéntico) como asumo que muchos de los que leen esto lo son, probablemente estés preocupado de que tu modelo ejecute un comando git reset o rm -rf y pierdas todo el progreso que has hecho en tu proyecto.
Afortunadamente, hay una herramienta de código abierto para detectar cuando el modelo está intentando ejecutar estos comandos y lo previene, requiriendo que obtenga permiso explícito del usuario antes de ejecutar comandos destructivos.
Protección contra comandos destructivos en acción
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Gopro en un pez, video de IA de Justin Moore en Twitter