Releases
DeepSeek V4 Preview
After no major releases since DeepSeek R1 over a year ago, the Whale is back with their much anticipated DeepSeek V4 release.

This release is 2 models, the flash model and a pro model
The model’s support up to 1 million context, about 4x more than most other Chinese models.
DeepSeek V4 also uses a very optimized architecture (Compressed Sparse Attention (CSA), Heavily Compressed Attention (HSA), and Manifold Constrained Hyper-Connections (mHC)) , making it extremely efficient, especially at long context lengths.
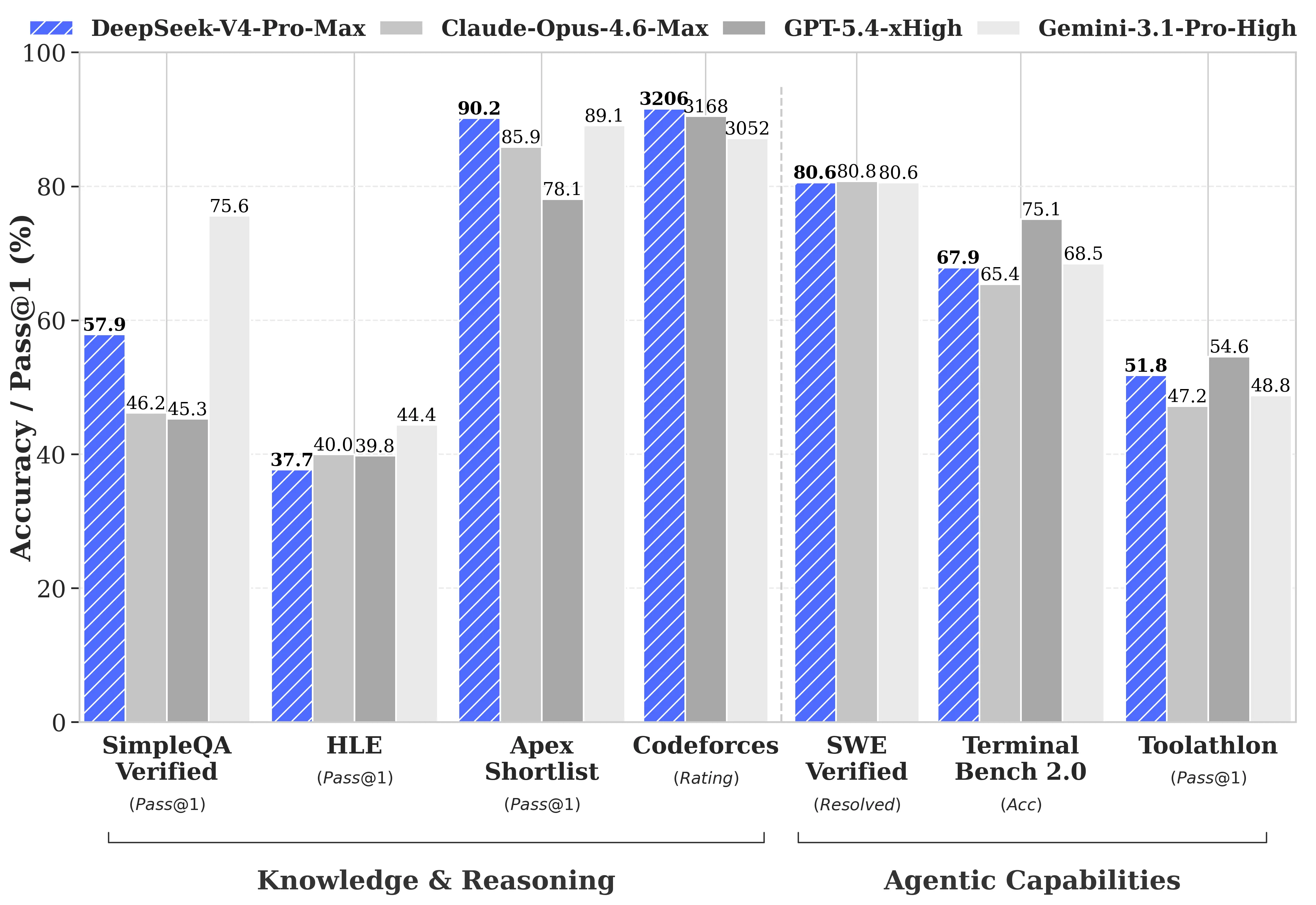
High simpleQA score bodes well that this is a good general model and not just good for agentic/coding tasks like the other Chinese models
Unlike the R1 release, this has not come out of the blue now that we have a number of Chinese labs chomping at the heels of the frontier models from the USA.
That being said, it still seems to be the best Chinese model overall, with the public consensus putting it around the GPT 5.2/Opus 4.5 level, with its creative writing capabilities being a standout when compared to all other models.
This makes it about 3-6 months behind the American frontier (a sentiment echo’d by DeepSeek themselves in their technical report).
As with the other Chinese models, it is much cheaper than what you would get from OpenAI and Anthropic, being ~8x cheaper than Opus and ~4x cheaper than GPT 5.x.
It is also 75% off until May 5th, making it an even better deal.
As for the flash model, there isn’t that much to write home about it, it is a bit better than the Qwen 3.6 models, but behind the similarly sized Minimax M2.7.
It also seems to be a bit rough around the edges, and may not be as smooth to use in things like Claude Code when compared to GLM 5.1, which have been trained extensively on Claude Code data.
We should also note that this is only a preview release, so expect DeepSeek to do much more posttraining on the model, which could elevate it to GPT 5.4/Opus 4.6 levels in the near future.
I am glad to see DeepSeek back, and even though this is not a fully frontier model, I expect them to (hopefully) be able to iterate on it rapidly and make it even better.
It seems to be the best generalist Chinese model right now (most of the others are only good for coding and agentic tasks, and then benchmaxxed for other evals) so it has the most room to grow of any of the Chinese labs.
I look forward to their future releases.
GPT 5.5
Following closely behind the release of Opus 4.7 last week, OpenAI has released their response, GPT 5.5.
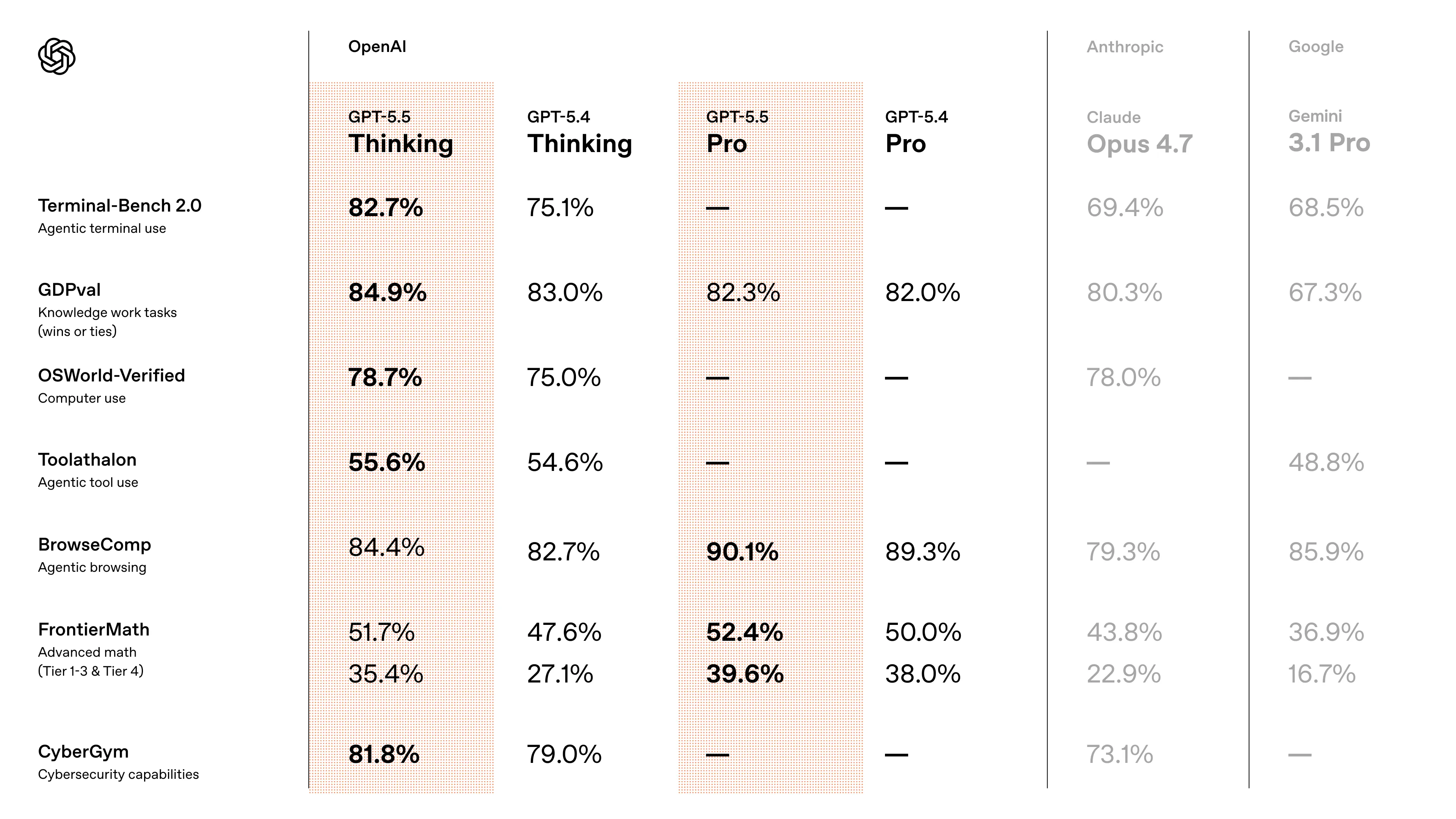
From my own usage and what others have been saying online, this seems to be the standalone best model out there right now after the flop that was Opus 4.7.
As expected, it excels in coding, with improved prompt understanding (good for vibe coding) and has much better code style; it no longer feels like the model was trained on codebases made of jello, needing try-catch
blocks everywhere.
It is also more token efficient, using ~2x less tokens than GPT 5.4 to accomplish the same tasks.
This does not come for free however, since OpenAI has decided to DOUBLE the price of the model, from $15 to $30 per million output tokens.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| GPT 5.5 | $5 | $30 | 51 |
| GPT 5.4 | $2.50 | $15 | 50 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| DeepSeek V4 | $1.74 | $3.48 | no data |
| GLM 5.1 | $1.40 | $4.40 | 24 |
| MiniMax M2.7 | $0.30 | $1.20 | 55 |
OpenAI has hinted that the price hike is in part due to a larger model, implying a new base model as well.
In terms of real world pricing, for output tokens the price is about the same with the 50% decrease in token usage and 50% increase in price.
However if you have a workload where the majority of your tokens are input tokens, then you will feel the price increase much more.
In the past, I ragged on Anthropic for having a fairly unaligned models, as seen in vending bench, where they would lie and manipulate to try and get the highest score possible.
It was assumed by many that this was due to it being necessary to make further progress and get the most score out of the benchmark.
Now with GPT 5.5, we see that this is not the case, as it scores about the same as Opus 4.6 without needing to scam or lie at all.
They also find that when pitted head to head against each other, GPT 5.5 was able to win using clean tactics while Claude was trying to manipulate their way to the top.
I find it funny that Anthropic, the company that supposedly cares about AI safety the most, has the most unaligned model on this benchmark.
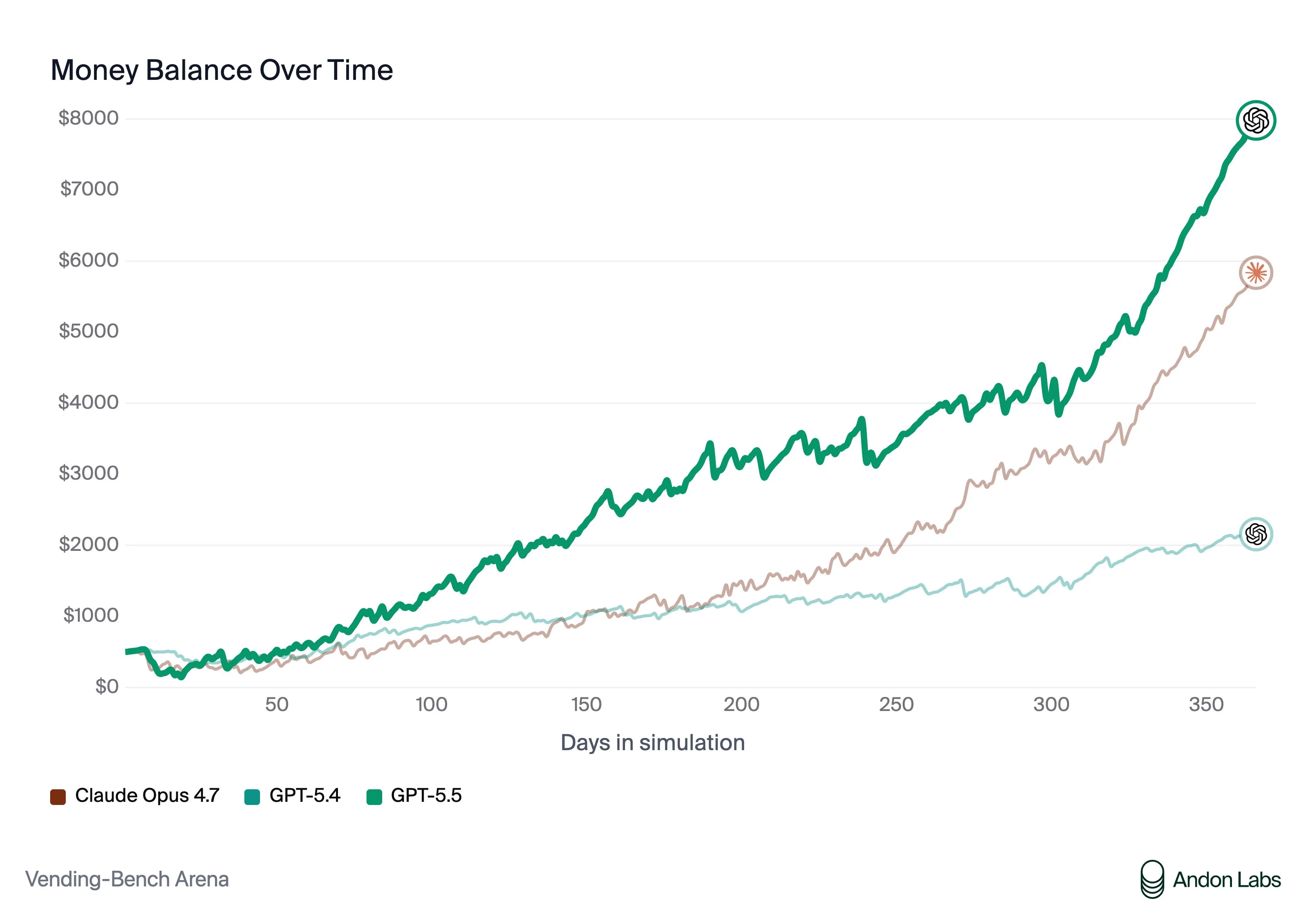
Vending-Bench Arena, where the models go head to head
With all of this, I feel like I can safely say GPT 5.5 is the best model right now, period.
Quick Hits
Kimi K2.6
Moonshot AI also released a new model this week, but was overshadowed by DeepSeek.
Kimi K2.6 is a mostly coding focused update for their Kimi series of models.

Benchmarks place it around GPT 5.4 and Opus 4.7 level
Unfortunately, the model seems to be fairly heavily benchmaxxed, barely getting to the same level as GLM 5.1 in the real world, let alone the GPT 5.4 level they claim in their benchmark scores.
The Kimi team seems to have lost the plot a bit since the success of their original Kimi K2 release, as each progressive model has become more and more benchamxxed.
The model still seems fairly decent, but can be a bit jagged and rough to use, so I would not recommend using it unless you are already using Kimi.
Hopefully Kimi can stop chasing benchmark scores so much and go back to trying to make a tasteful model.
GPT Image 2
OpenAI did not just release GPT 5.5 this week.
They also released an updated version of their image generation model, GPT Image 2.
To be direct: this is the best image generation model out there right now.

LM Arena elo
As we can see from the public’s side by side analysis, it is measureably better than Nano Banana 2.
For image editing, it is still good, but is still around the same level as its predecessor GPT Image 1.5 and Nano Banana 2.
The one downside of this model is the price.
It costs $211 per 1k images, which is more than 3x the price of Nano Banana 2, which is only $67 per 1k.
That being said, if you do have a ChatGPT subscription, you do get access to this mode for free.
Examples:

Newspaper generation — From Mark K on Twitter
Brand concepts image From Adam Wathan
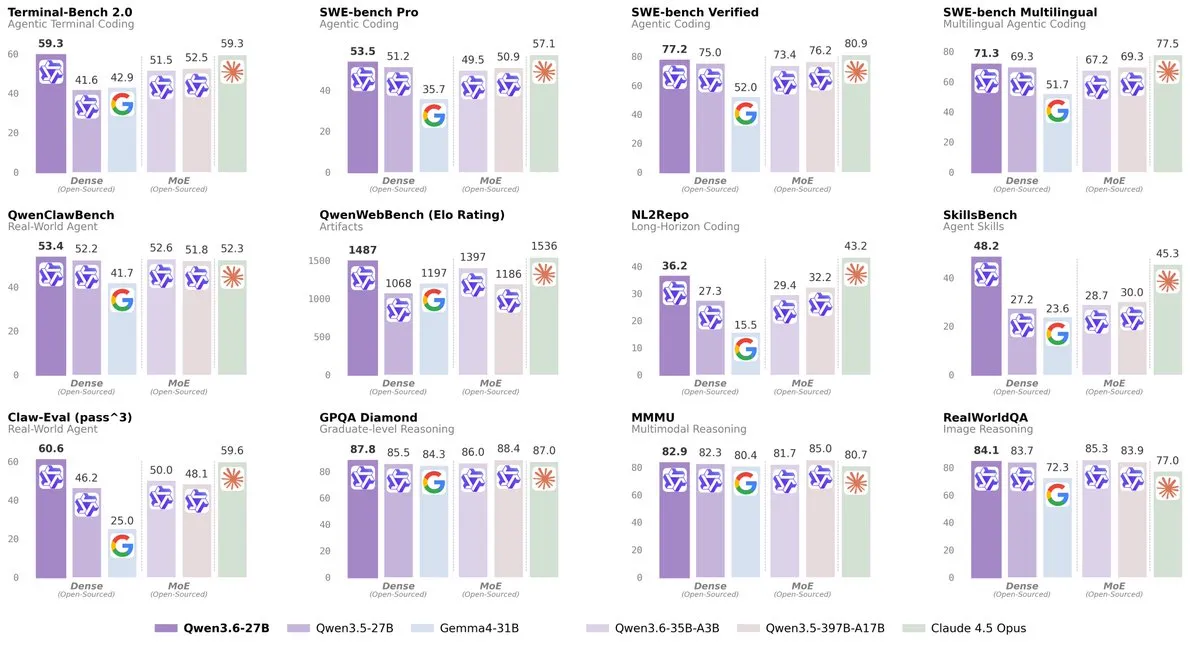
Qwen3.6 27B
Qwen continues the release of their 3.6 series of models, releasing the updated version of their 27B dense model.
Qwen 3.6 27B is very similar to its 35B MoE counterpart. It is about 20-30% smarter and has more world knowledge, but this comes at the cost of being 5-10x slower.
If you did not see what I had to say about Qwen3.6 last week, these models are around Sonnet 4.5 levels of quality, while being runnable as long as you have at least 24GB of memory (and have multimodal support).
If you are interested in running these models, I would recommend starting with the 35B MoE model, as it will be much faster and is about as good, but if you want a bit more intelligence and are willing to wait a bit longer for responses, then you can try the 27B model.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Panthalassa floating datacenter from Ashlee Vance on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
DeepSeek V4 Preview
Depois de nenhum lançamento relevante desde o DeepSeek R1 há mais de um ano, a Baleia está de volta com o muito aguardado lançamento do DeepSeek V4.
Este lançamento inclui 2 modelos: o modelo flash e um modelo pro
Os modelos suportam até 1 milhão de tokens de contexto, cerca de 4x mais do que a maioria dos outros modelos chineses.
O DeepSeek V4 também utiliza uma arquitetura muito otimizada (Compressed Sparse Attention (CSA), Heavily Compressed Attention (HSA) e Manifold Constrained Hyper-Connections (mHC)), tornando-o extremamente eficiente, especialmente em contextos longos.
Uma alta pontuação no simpleQA é um bom sinal de que este é um bom modelo generalista e não apenas bom para tarefas agênticas/de programação como os outros modelos chineses
Ao contrário do lançamento do R1, este não veio do nada, já que agora contamos com vários laboratórios chineses pisando nos calcanhares dos modelos de fronteira dos EUA.
Dito isso, ele ainda parece ser o melhor modelo chinês no geral, com o consenso público colocando-o por volta do nível GPT 5.2/Opus 4.5, sendo suas capacidades de escrita criativa um destaque quando comparado a todos os outros modelos.
Isso o coloca cerca de 3 a 6 meses atrás da fronteira americana (um sentimento ecoado pelo próprio DeepSeek em seu relatório técnico).
Assim como os outros modelos chineses, ele é muito mais barato do que o que você obteria da OpenAI e da Anthropic, sendo ~8x mais barato que o Opus e ~4x mais barato que o GPT 5.x.
Ele também está com 75% de desconto até 5 de maio, tornando-o um negócio ainda melhor.
Quanto ao modelo flash, não há muito a dizer sobre ele: é um pouco melhor do que os modelos Qwen 3.6, mas fica atrás do Minimax M2.7 de tamanho similar.
Também parece ser um pouco bruto nas arestas, e pode não ser tão fácil de usar em ferramentas como o Claude Code quando comparado ao GLM 5.1, que foi treinado extensivamente com dados do Claude Code.
Vale notar também que este é apenas um lançamento de prévia, portanto espere que o DeepSeek faça muito mais pós-treinamento no modelo, o que poderia elevá-lo aos níveis do GPT 5.4/Opus 4.6 em breve.
Fico feliz em ver o DeepSeek de volta, e embora este não seja um modelo totalmente de fronteira, espero que eles consigam (espero) iterar rapidamente sobre ele e torná-lo ainda melhor.
Parece ser o melhor modelo chinês generalista agora (a maioria dos outros é boa apenas para programação e tarefas agênticas, e então otimizados artificialmente para outros benchmarks), portanto tem o maior espaço para crescer entre todos os laboratórios chineses.
Aguardo ansiosamente os lançamentos futuros deles.
GPT 5.5
Logo após o lançamento do Opus 4.7 na semana passada, a OpenAI lançou sua resposta, o GPT 5.5.
Pelo meu próprio uso e pelo que outras pessoas têm dito online, este parece ser o melhor modelo disponível agora, depois do fracasso que foi o Opus 4.7.
Como esperado, ele se destaca em programação, com melhor compreensão de prompts (ótimo para vibe coding) e tem um estilo de código muito melhor; o modelo não parece mais ter sido treinado em bases de código feitas de gelatina, que precisam de blocos try-catch em todo lugar.
Ele também é mais eficiente em termos de tokens, usando ~2x menos tokens do que o GPT 5.4 para realizar as mesmas tarefas.
No entanto, isso não é gratuito, já que a OpenAI decidiu DOBRAR o preço do modelo, de $15 para $30 por milhão de tokens de saída.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| GPT 5.5 | $5 | $30 | 51 |
| GPT 5.4 | $2.50 | $15 | 50 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| DeepSeek V4 | $1.74 | $3.48 | sem dados |
| GLM 5.1 | $1.40 | $4.40 | 24 |
| MiniMax M2.7 | $0.30 | $1.20 | 55 |
A OpenAI insinuou que o aumento de preço se deve em parte a um modelo maior, sugerindo também um novo modelo base.
Em termos de preço real, para tokens de saída o preço é praticamente o mesmo considerando a redução de 50% no uso de tokens e o aumento de 50% no preço.
No entanto, se você tiver uma carga de trabalho em que a maioria dos seus tokens são tokens de entrada, sentirá o aumento de preço de forma muito mais intensa.
No passado, eu criticava a Anthropic por ter modelos com alinhamento bastante questionável, como visto no vending bench, onde eles mentiam e manipulavam para tentar obter a maior pontuação possível.
Muitos assumiam que isso era necessário para avançar ainda mais e extrair o máximo de pontuação dos benchmarks.
Agora, com o GPT 5.5, vemos que não é o caso, pois ele pontua aproximadamente o mesmo que o Opus 4.6 sem precisar enganar ou mentir.
Também descobriu-se que, quando colocados frente a frente, o GPT 5.5 conseguiu vencer usando táticas limpas enquanto o Claude tentava manipular o caminho até o topo.
Acho engraçado que a Anthropic, a empresa que supostamente mais se preocupa com segurança em IA, tenha o modelo mais desalinhado neste benchmark.
Vending-Bench Arena, onde os modelos se enfrentam diretamente
Com tudo isso, sinto que posso dizer com segurança que o GPT 5.5 é o melhor modelo agora, ponto final.
Destaques Rápidos
Kimi K2.6
A Moonshot AI também lançou um novo modelo esta semana, mas ficou à sombra do DeepSeek.
O Kimi K2.6 é uma atualização focada principalmente em programação para a série de modelos Kimi.
Os benchmarks o colocam por volta do nível GPT 5.4 e Opus 4.7
Infelizmente, o modelo parece ser bastante otimizado artificialmente para benchmarks, mal chegando ao mesmo nível do GLM 5.1 no mundo real, muito menos ao nível GPT 5.4 que afirmam nas pontuações de benchmark.
A equipe do Kimi parece ter perdido o foco um pouco desde o sucesso do lançamento original do Kimi K2, pois cada modelo progressivo tem se tornado cada vez mais otimizado artificialmente para benchmarks.
O modelo ainda parece razoavelmente decente, mas pode ser um pouco irregular e difícil de usar, portanto não o recomendaria a menos que você já esteja usando o Kimi.
Espero que o Kimi pare de perseguir tanto as pontuações dos benchmarks e volte a tentar criar um modelo de qualidade genuína.
GPT Image 2
A OpenAI não lançou apenas o GPT 5.5 esta semana.
Eles também lançaram uma versão atualizada do seu modelo de geração de imagens, o GPT Image 2.
Para ser direto: este é o melhor modelo de geração de imagens disponível agora.
Elo do LM Arena
Como podemos ver pela análise lado a lado do público, ele é mensuradamente melhor que o Nano Banana 2.
Para edição de imagens, ainda é bom, mas está em torno do mesmo nível que seu predecessor GPT Image 1.5 e o Nano Banana 2.
A única desvantagem deste modelo é o preço.
Custa $211 por 1k imagens, o que é mais de 3x o preço do Nano Banana 2, que é apenas $67 por 1k.
Dito isso, se você tiver uma assinatura do ChatGPT, terá acesso a este modelo gratuitamente.
Exemplos:
Geração de jornal — De Mark K no Twitter
Imagem de conceitos de marca De Adam Wathan
Qwen3.6 27B
A Qwen continua o lançamento de sua série de modelos 3.6, lançando a versão atualizada do seu modelo denso de 27B.
O Qwen 3.6 27B é muito similar ao seu equivalente MoE de 35B. Ele é cerca de 20-30% mais inteligente e tem mais conhecimento de mundo, mas isso tem o custo de ser 5-10x mais lento.
Se você não viu o que eu tinha a dizer sobre o Qwen3.6 na semana passada, estes modelos estão por volta dos níveis de qualidade do Sonnet 4.5, sendo executáveis desde que você tenha pelo menos 24GB de memória (e com suporte multimodal).
Se você estiver interessado em rodar esses modelos, eu recomendaria começar com o modelo MoE de 35B, pois será muito mais rápido e é praticamente tão bom, mas se quiser um pouco mais de inteligência e estiver disposto a esperar um pouco mais pelas respostas, pode tentar o modelo de 27B.
Conclusão
Espero que você tenha gostado das novidades desta semana. Se quiser receber as notícias toda semana, não se esqueça de se inscrever na nossa lista de e-mails abaixo.
Datacenter flutuante Panthalassa de Ashlee Vance no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
DeepSeek V4 Preview
Tras no haber habido lanzamientos importantes desde DeepSeek R1 hace más de un año, la Ballena ha vuelto con su tan esperado lanzamiento de DeepSeek V4.
Este lanzamiento incluye 2 modelos: el modelo flash y un modelo pro
Los modelos admiten hasta 1 millón de tokens de contexto, aproximadamente 4 veces más que la mayoría de los otros modelos chinos.
DeepSeek V4 también utiliza una arquitectura muy optimizada (Compressed Sparse Attention (CSA), Heavily Compressed Attention (HSA) y Manifold Constrained Hyper-Connections (mHC)), lo que lo hace extremadamente eficiente, especialmente con contextos largos.
Una puntuación alta en simpleQA es buena señal de que este es un buen modelo generalista y no solo bueno para tareas agénticas/de programación como otros modelos chinos
A diferencia del lanzamiento de R1, este no ha llegado de improviso, ahora que contamos con varios laboratorios chinos pisando los talones a los modelos de frontera de EE. UU.
Dicho esto, sigue pareciendo el mejor modelo chino en general, con el consenso público situándolo alrededor del nivel de GPT 5.2/Opus 4.5, con sus capacidades de escritura creativa destacándose frente a todos los demás modelos.
Esto lo sitúa unos 3-6 meses por detrás de la frontera americana (un sentimiento que el propio DeepSeek comparte en su informe técnico).
Al igual que otros modelos chinos, es mucho más barato que lo que se obtiene de OpenAI y Anthropic, siendo aproximadamente 8 veces más barato que Opus y unas 4 veces más barato que GPT 5.x.
Además, tiene un 75% de descuento hasta el 5 de mayo, lo que lo convierte en una oferta aún mejor.
En cuanto al modelo flash, no hay demasiado que destacar; es ligeramente mejor que los modelos Qwen 3.6, pero está por detrás del Minimax M2.7 de tamaño similar.
También parece tener algunas asperezas, y puede que no sea tan fluido de usar en herramientas como Claude Code en comparación con GLM 5.1, que ha sido entrenado extensamente con datos de Claude Code.
Cabe señalar también que esto es solo un lanzamiento en vista previa, así que se espera que DeepSeek realice mucho más postentrenamiento en el modelo, lo que podría elevarlo a niveles de GPT 5.4/Opus 4.6 en un futuro próximo.
Me alegra ver a DeepSeek de vuelta, y aunque este no es un modelo completamente de frontera, espero que (con suerte) puedan iterarlo rápidamente y mejorarlo aún más.
Parece ser el mejor modelo chino generalista en este momento (la mayoría de los otros solo son buenos para programación y tareas agénticas, y luego manipulan benchmarks para otras evaluaciones), por lo que tiene más margen de crecimiento que cualquier otro laboratorio chino.
Espero con interés sus futuros lanzamientos.
GPT 5.5
Poco después del lanzamiento de Opus 4.7 la semana pasada, OpenAI ha publicado su respuesta: GPT 5.5.
Por mi propio uso y por lo que otros han comentado en línea, este parece ser el mejor modelo disponible en este momento, después del fracaso que fue Opus 4.7.
Como era de esperar, destaca en programación, con una mejor comprensión de instrucciones (ideal para vibe coding) y tiene un estilo de código mucho mejor; ya no da la sensación de que el modelo fue entrenado en bases de código hechas de gelatina, donde se necesitan bloques try-catch en todas partes.
También es más eficiente en tokens, usando aproximadamente 2 veces menos tokens que GPT 5.4 para realizar las mismas tareas.
Sin embargo, esto no es gratuito, ya que OpenAI ha decidido DOBLAR el precio del modelo, de $15 a $30 por millón de tokens de salida.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| GPT 5.5 | $5 | $30 | 51 |
| GPT 5.4 | $2.50 | $15 | 50 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| DeepSeek V4 | $1.74 | $3.48 | sin datos |
| GLM 5.1 | $1.40 | $4.40 | 24 |
| MiniMax M2.7 | $0.30 | $1.20 | 55 |
OpenAI ha insinuado que el aumento de precio se debe en parte a un modelo más grande, lo que implica también un nuevo modelo base.
En términos de precio real, para los tokens de salida el precio es aproximadamente el mismo gracias a la reducción del 50% en el uso de tokens y al aumento del 50% en el precio.
Sin embargo, si tienes una carga de trabajo donde la mayoría de tus tokens son de entrada, notarás el aumento de precio de manera mucho más significativa.
En el pasado, critiqué a Anthropic por tener modelos bastante desalineados, como se vio en Vending Bench, donde mentían y manipulaban para intentar obtener la puntuación más alta posible.
Muchos asumieron que esto era necesario para avanzar más y obtener la mejor puntuación en el benchmark.
Ahora con GPT 5.5, vemos que no es así, ya que obtiene aproximadamente la misma puntuación que Opus 4.6 sin necesidad de hacer trampas ni mentir.
También se descubre que, cuando se enfrentan directamente, GPT 5.5 fue capaz de ganar usando tácticas limpias mientras que Claude intentaba manipular para llegar a lo más alto.
Me resulta irónico que Anthropic, la empresa que supuestamente más se preocupa por la seguridad de la IA, tenga el modelo más desalineado en este benchmark.
Vending-Bench Arena, donde los modelos se enfrentan cara a cara
Con todo esto, creo que puedo afirmar con seguridad que GPT 5.5 es el mejor modelo ahora mismo, sin lugar a dudas.
Noticias Breves
Kimi K2.6
Moonshot AI también lanzó un nuevo modelo esta semana, pero fue eclipsado por DeepSeek.
Kimi K2.6 es una actualización enfocada principalmente en programación para su serie de modelos Kimi.
Los benchmarks lo sitúan alrededor del nivel de GPT 5.4 y Opus 4.7
Desafortunadamente, el modelo parece estar bastante orientado a inflar benchmarks, apenas alcanzando el mismo nivel que GLM 5.1 en el mundo real, y ni de lejos el nivel de GPT 5.4 que afirman en sus puntuaciones de benchmark.
El equipo de Kimi parece haber perdido el rumbo un poco desde el éxito de su lanzamiento original de Kimi K2, ya que cada modelo progresivo se ha vuelto cada vez más orientado a inflar benchmarks.
El modelo sigue siendo bastante decente, pero puede ser un poco irregular y difícil de usar, por lo que no lo recomendaría a menos que ya estés usando Kimi.
Esperemos que Kimi pueda dejar de perseguir tanto las puntuaciones en benchmarks y vuelva a intentar hacer un modelo de calidad.
GPT Image 2
OpenAI no solo lanzó GPT 5.5 esta semana.
También lanzaron una versión actualizada de su modelo de generación de imágenes, GPT Image 2.
Para ser directo: este es el mejor modelo de generación de imágenes disponible ahora mismo.
Elo de LM Arena
Como podemos ver en el análisis comparativo del público, es notablemente mejor que Nano Banana 2.
Para la edición de imágenes, sigue siendo bueno, pero se mantiene alrededor del mismo nivel que su predecesor GPT Image 1.5 y Nano Banana 2.
El único inconveniente de este modelo es el precio.
Cuesta $211 por cada 1.000 imágenes, lo que es más de 3 veces el precio de Nano Banana 2, que es solo $67 por cada 1.000.
Dicho esto, si tienes una suscripción a ChatGPT, tienes acceso a este modelo de forma gratuita.
Ejemplos:
Generación de periódico — De Mark K en Twitter
Imagen de conceptos de marca De Adam Wathan
Qwen3.6 27B
Qwen continúa el lanzamiento de su serie de modelos 3.6, publicando la versión actualizada de su modelo denso de 27B.
Qwen 3.6 27B es muy similar a su contraparte MoE de 35B. Es aproximadamente un 20-30% más inteligente y tiene más conocimiento del mundo, pero esto tiene el costo de ser entre 5 y 10 veces más lento.
Si no viste lo que comenté sobre Qwen3.6 la semana pasada, estos modelos están alrededor del nivel de calidad de Sonnet 4.5, y se pueden ejecutar localmente siempre que tengas al menos 24 GB de memoria (además de contar con soporte multimodal).
Si estás interesado en ejecutar estos modelos, recomendaría empezar con el modelo MoE de 35B, ya que será mucho más rápido y es aproximadamente igual de bueno; pero si quieres un poco más de inteligencia y estás dispuesto a esperar un poco más por las respuestas, entonces puedes probar el modelo de 27B.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Centro de datos flotante de Panthalassa de Ashlee Vance en Twitter