Releases
Custom Coding Agent Models
I have said before that the winners of the agent framework battle will be those that control both the harness the model uses and also the model itself, since they will be able to coadapt the harness and the model together. Thus their model will work the best with their harness, giving the best results.
Previously Anthropic and OpenAI were the only major names that had both of these things (along with widespread adoption). The model wrappers, Cursor and Windsurf, did not have such an advantage, which is why I did not recommend using them. This week however, they came out with their own offerings, so lets see how they stack up to GPT-5 and Claude 4.5, and if they are worth switching over to their platforms for.
Windsurf SWE-1.5
For both of the models, their main selling point is not necessarily their quality, but rather their speed. GPT-5 in Codex is the biggest example of slow and good, often taking over 30 minutes to complete a single request. Having a faster iteration loop with the AI is good, especially when you have underspecified criteria where the model won’t be able to get it right the first try no matter how smart it is. If you are going to need to have a back and forth with a model to make a feature, would you rather wait 10 seconds or 15 minutes between responses.
For SWE-1.5, it appears to be trained from the Z.ai GLM 4.5 model (not 4.6, most likely due to training starting before the 4.6 release).
The model is hosted on Cerebras, which offers the fastest LLM inference of any platform by far, allowing for inference speeds exceeding 1.8k tokens per second.
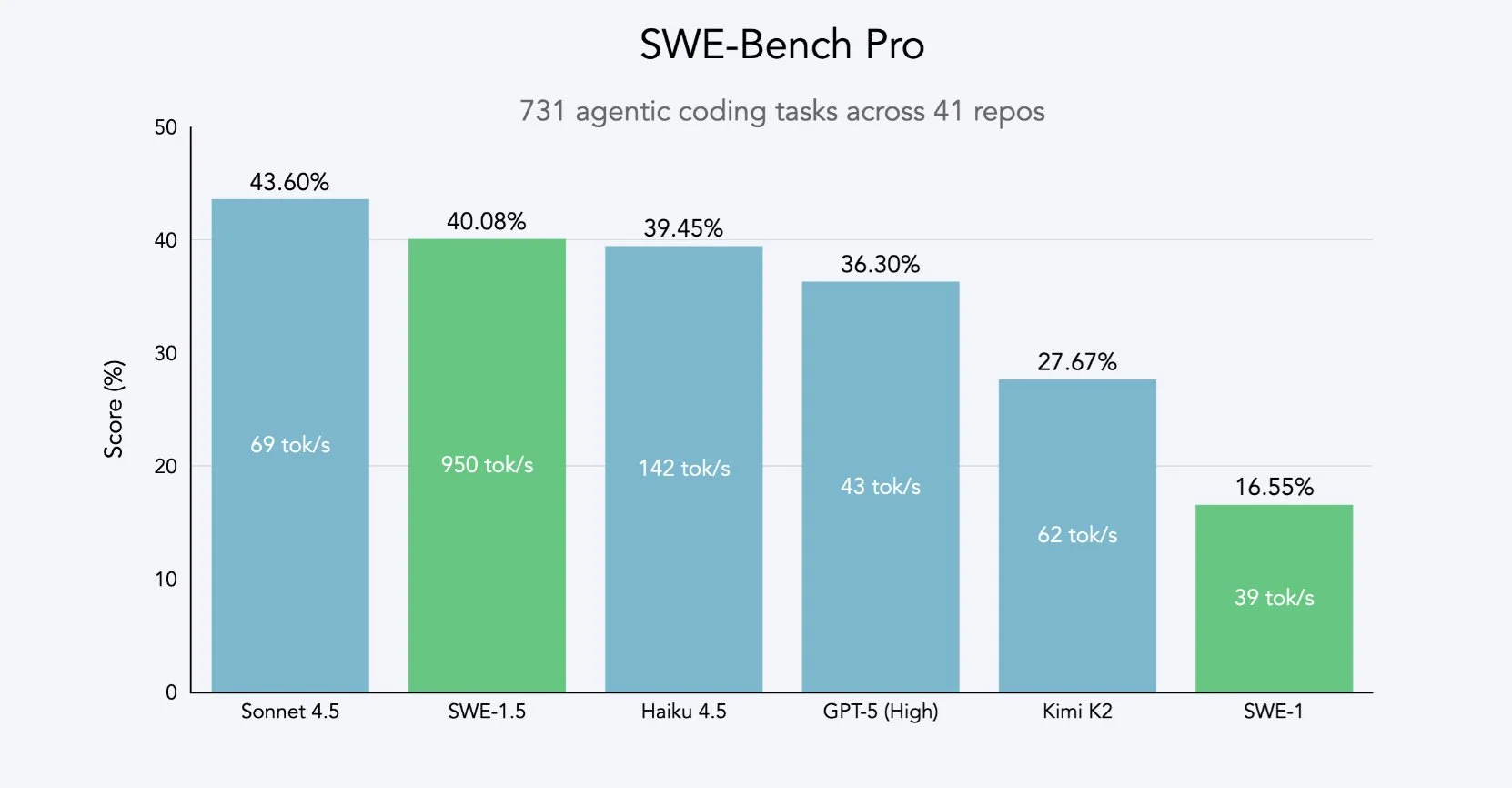
SWE-Bench Pro is a bit better than the usual SWE-Bench. However it is made by Scale AI, who often provide the data for these models, so there may be a conflict of interest there.
In terms of quality, the model seems to be around GLM 4.6 level, so definitely usable, but not near the frontier level of intelligence that Claude 4.5 and GPT-5 have. Also Cerebras will be offering GLM 4.6 directly in the near future, so I don’t see any need to lock yourself in the Windsurf world to use this model.
It will be interesting to see if Windsurf will be able to tune the model to the point where it is at the same level as GPT and Claude, because then there is significant incentive with the inference speed + quality to go to Windsurf.
Cursor Composer
The headlining feature for the Cursor 2.0 release is their new Cursor Composer model. Similar to SWE-1.5, we do not know for certain what the model they are using is, although it is definitely a fine tune on top of an already existing model. There is evidence that it may be based on Deepseek, but it is not as clear as it is for SWE-1.5.
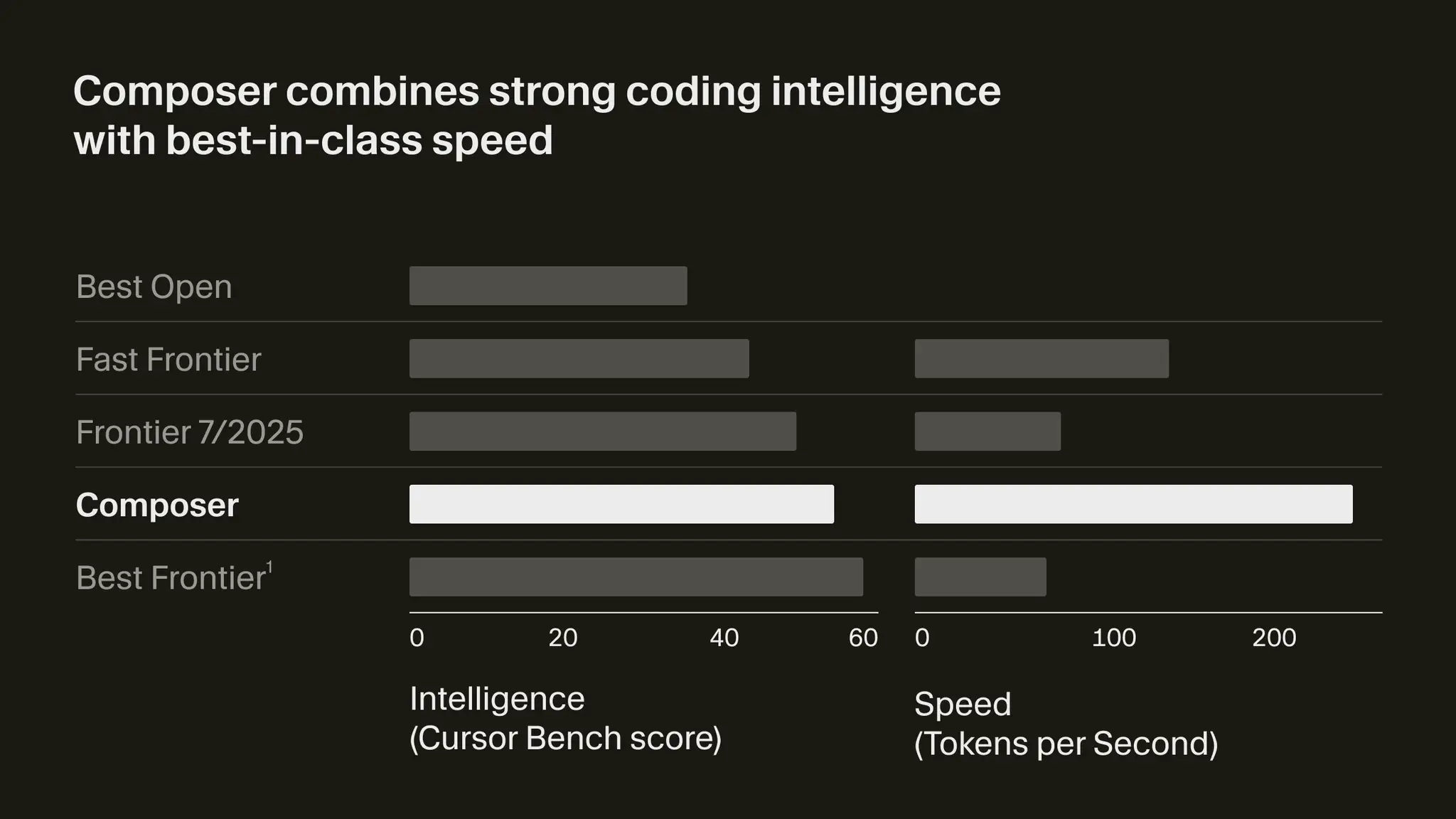
Very vague benchmarks are a good sign
Composer is not hosted on Cerebras, so it is unable to hit the 4 digit token per second speeds that SWE-1.5 can, but it is still fast for a transformer model.
Vibe check on this one is a bit worse than SWE-1.5, probably around Sonnet 3.7 quality.
If SWE-1.5 was a pass, then Cursor Composer with its almost 10x slower speeds and worse quality is a hard no.
Research
Continual Learning from Thinking Machines
When trying to finetune a model for your own use case, the most difficult thing to do is encode new information into the model without having it forget what it previously had known and was capable of. The best way for a model to learn information is during the pre or mid training steps, which is just meant for unstructured text. So if you are fine tuning a model that has already had a chat style post training done to it, you would be essentially overwriting its chatbot behaviours with your new info.
Normally you would add in some of the “original” data, or something akin to it, but the model would still struggle to fully recover what it had known and was a very finicky process.
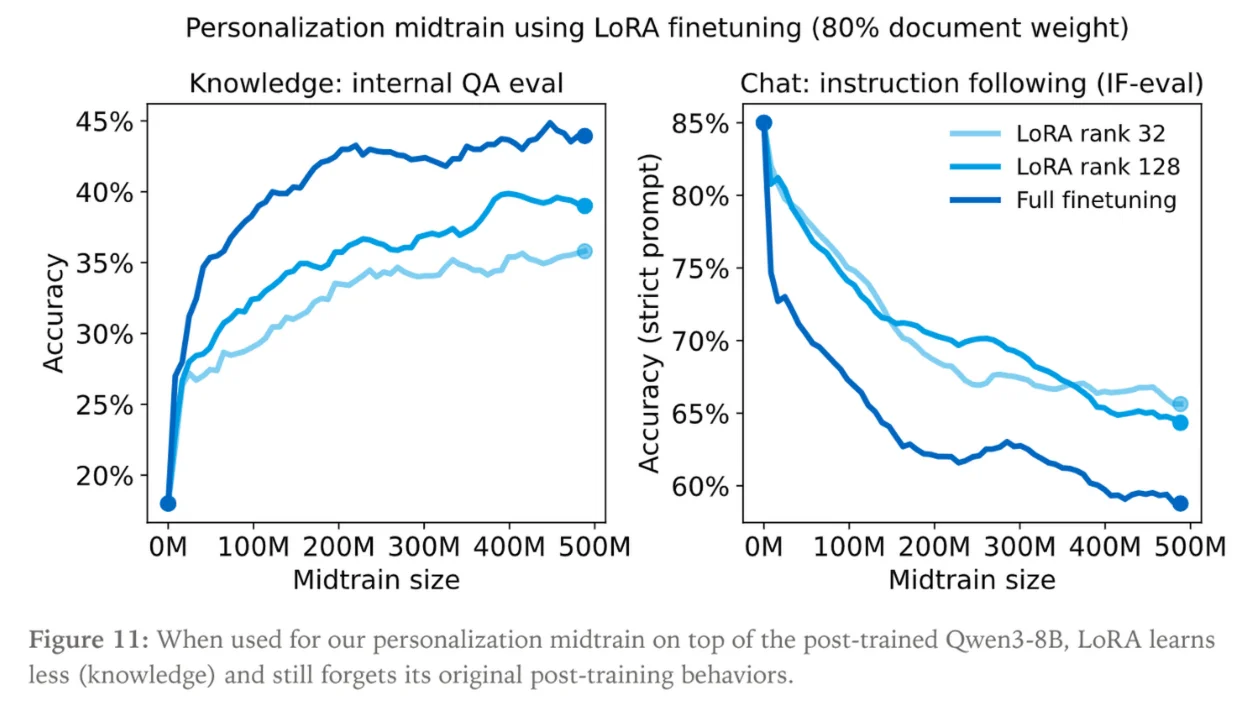
The more you train on new info, the worse the model’s instruction following gets, even adding in data from the original dataset. Also note that even after training on the docs, accuracy was still not above 50%
The researchers at Thinking Machines have a fix for this. They propose a new methodology called On-Policy Distillation which allows you to recover the original model quality very easily after doing continued pretraining on your internal documents.
On-Policy Distillation uses the original model (teacher) as a reward model, giving a reward for each token the fine tuned model (student) produces. This way the model learns to mimic the original distribution of knowledge that it had. The surprising thing about this method is that it doesn’t then cause the student to forget any of the new information that it just learned. It also is much more compute efficient than doing a regular finetune, using 50-100x less compute in the process.
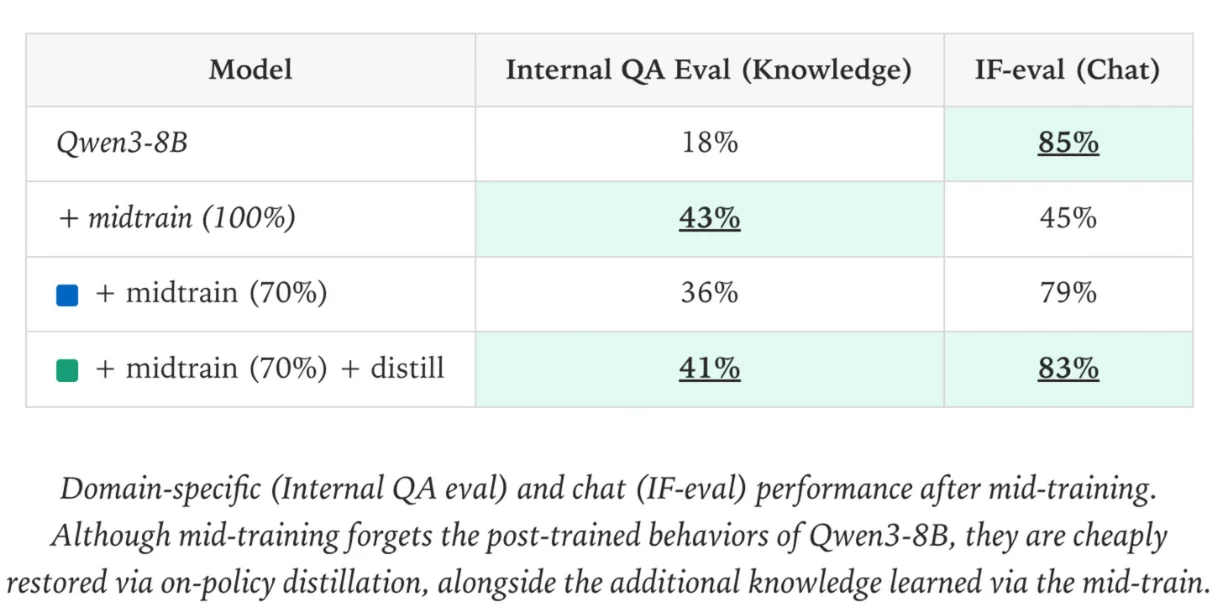
using on policy distillation allows for new knowledge to be added while retaining previous abilities
This is not that groundbreaking in terms of research, most of these concepts existed previously, they have just been brought together into a single report here by Thinky.
What is interesting is that this, coupled with Thinking Machines previous releases of a training service and an in depth Lora analysis, seems to point to what the company will be focused on in the future.
They are not chasing the frontier of intelligence like OpenAI and Anthropic are. Instead they are focusing on small, fast, specially catered models that can be iterated on quickly and easily with updated information. I am a big fan of this direction, as I have been skeptical of how much we really need to be scaling models versus focusing them more narrowly for our tasks. Scaling has just been the easiest method, especially with all of the money pouring into the field recently.
I (think) I share the same vision of the future as Thinking Machines, where we are running our own models at home or in small clusters instead of using proprietary models in large datacenters. We will see if this vision holds. I look forward to more releases from Thinking Machines and will be sure to cover anything interesting here.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
resumo
- Modelos de codificação extremamente rápidos do Cursor e Windsurf
- Thinking Machines estabelece as bases para aprendizado contínuo
Lançamentos
Modelos Personalizados de Agentes de Codificação
Eu já disse antes que os vencedores da batalha de frameworks de agentes serão aqueles que controlam tanto o harness que o modelo usa quanto o próprio modelo, pois eles serão capazes de coadaptar o harness e o modelo juntos. Assim, seu modelo funcionará melhor com seu harness, proporcionando os melhores resultados.
Anteriormente, Anthropic e OpenAI eram os únicos grandes nomes que tinham ambas essas coisas (juntamente com adoção generalizada). Os wrappers de modelos, Cursor e Windsurf, não tinham tal vantagem, razão pela qual eu não recomendava usá-los. Esta semana, no entanto, eles lançaram suas próprias ofertas, então vamos ver como eles se comparam ao GPT-5 e Claude 4.5, e se vale a pena mudar para suas plataformas.
Windsurf SWE-1.5
Para ambos os modelos, seu principal ponto de venda não é necessariamente sua qualidade, mas sim sua velocidade. O GPT-5 no Codex é o maior exemplo de lento e bom, frequentemente levando mais de 30 minutos para completar uma única solicitação. Ter um ciclo de iteração mais rápido com a IA é bom, especialmente quando você tem critérios subespecificados onde o modelo não será capaz de acertar na primeira tentativa, não importa quão inteligente seja. Se você precisar ter uma conversa de ida e volta com um modelo para fazer um recurso, você preferiria esperar 10 segundos ou 15 minutos entre as respostas.
Para o SWE-1.5, parece ser treinado a partir do modelo Z.ai GLM 4.5 (não 4.6, provavelmente devido ao treinamento ter começado antes do lançamento do 4.6).
O modelo está hospedado no Cerebras, que oferece a inferência de LLM mais rápida de qualquer plataforma de longe, permitindo velocidades de inferência superiores a 1,8k tokens por segundo.
SWE-Bench Pro é um pouco melhor que o SWE-Bench usual. No entanto, é feito pela Scale AI, que frequentemente fornece os dados para esses modelos, então pode haver um conflito de interesses ali.
Em termos de qualidade, o modelo parece estar no nível do GLM 4.6, então definitivamente utilizável, mas não perto do nível de fronteira de inteligência que Claude 4.5 e GPT-5 têm. Além disso, o Cerebras oferecerá o GLM 4.6 diretamente em um futuro próximo, então não vejo necessidade de se prender ao mundo Windsurf para usar este modelo.
Será interessante ver se o Windsurf será capaz de ajustar o modelo ao ponto em que esteja no mesmo nível que GPT e Claude, porque então há um incentivo significativo com a velocidade de inferência + qualidade para ir para o Windsurf.
Cursor Composer
O recurso principal do lançamento do Cursor 2.0 é seu novo modelo Cursor Composer. Semelhante ao SWE-1.5, não sabemos com certeza qual é o modelo que eles estão usando, embora seja definitivamente um ajuste fino em cima de um modelo já existente. Há evidências de que pode ser baseado no Deepseek, mas não é tão claro quanto é para o SWE-1.5.
Benchmarks muito vagos são um bom sinal
O Composer não está hospedado no Cerebras, então ele é incapaz de atingir as velocidades de 4 dígitos de tokens por segundo que o SWE-1.5 pode, mas ainda é rápido para um modelo transformer.
A verificação de vibe neste é um pouco pior que o SWE-1.5, provavelmente em torno da qualidade do Sonnet 3.7.
Se o SWE-1.5 foi aprovado, então o Cursor Composer com suas velocidades quase 10x mais lentas e pior qualidade é um não definitivo.
Pesquisa
Aprendizado Contínuo da Thinking Machines
Ao tentar fazer o fine-tuning de um modelo para seu próprio caso de uso, a coisa mais difícil de fazer é codificar novas informações no modelo sem fazê-lo esquecer o que ele conhecia anteriormente e era capaz de fazer. A melhor maneira para um modelo aprender informações é durante as etapas de pré ou mid training, que são destinadas apenas para texto não estruturado. Então, se você está fazendo fine-tuning de um modelo que já teve um pós-treinamento estilo chat feito nele, você estaria essencialmente sobrescrevendo seus comportamentos de chatbot com suas novas informações.
Normalmente você adicionaria alguns dos dados “originais”, ou algo semelhante a isso, mas o modelo ainda teria dificuldade para recuperar totalmente o que ele conhecia e era um processo muito delicado.
Quanto mais você treina em novas informações, pior fica o seguimento de instruções do modelo, mesmo adicionando dados do dataset original. Observe também que mesmo após treinar nos documentos, a precisão ainda não estava acima de 50%
Os pesquisadores da Thinking Machines têm uma solução para isso. Eles propõem uma nova metodologia chamada On-Policy Distillation que permite recuperar a qualidade do modelo original muito facilmente depois de fazer pré-treinamento contínuo em seus documentos internos.
On-Policy Distillation usa o modelo original (professor) como um modelo de recompensa, dando uma recompensa para cada token que o modelo ajustado (aluno) produz. Dessa forma, o modelo aprende a imitar a distribuição original de conhecimento que tinha. A coisa surpreendente sobre este método é que ele não faz com que o aluno esqueça nenhuma das novas informações que acabou de aprender. Também é muito mais eficiente em termos de computação do que fazer um fine-tuning regular, usando 50-100x menos computação no processo.
usar on policy distillation permite que novos conhecimentos sejam adicionados enquanto retém habilidades anteriores
Isso não é tão revolucionário em termos de pesquisa, a maioria desses conceitos existia anteriormente, eles apenas foram reunidos em um único relatório aqui pela Thinky.
O que é interessante é que isso, juntamente com os lançamentos anteriores da Thinking Machines de um serviço de treinamento e uma análise aprofundada de Lora, parece apontar para o que a empresa estará focada no futuro.
Eles não estão perseguindo a fronteira da inteligência como OpenAI e Anthropic estão. Em vez disso, eles estão se concentrando em modelos pequenos, rápidos, especialmente adaptados que podem ser iterados rapidamente e facilmente com informações atualizadas. Sou um grande fã desta direção, pois tenho sido cético sobre quanto realmente precisamos estar escalando modelos versus focando-os mais estritamente para nossas tarefas. Escalar tem sido apenas o método mais fácil, especialmente com todo o dinheiro fluindo para o campo recentemente.
Eu (acho) que compartilho a mesma visão de futuro que a Thinking Machines, onde estamos executando nossos próprios modelos em casa ou em pequenos clusters em vez de usar modelos proprietários em grandes datacenters. Veremos se esta visão se sustenta. Aguardo mais lançamentos da Thinking Machines e certamente cobrirei qualquer coisa interessante aqui.
Fim
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
En resumen
- Modelos de programación ultrarrápidos de Cursor y Windsurf
- Thinking Machines sienta las bases para el aprendizaje continuo
Lanzamientos
Modelos Personalizados de Agentes de Programación
He dicho anteriormente que los ganadores de la batalla de frameworks de agentes serán aquellos que controlen tanto el entorno que usa el modelo como el modelo en sí, ya que podrán coadaptar el entorno y el modelo juntos. Así su modelo funcionará mejor con su entorno, dando los mejores resultados.
Anteriormente Anthropic y OpenAI eran los únicos nombres importantes que tenían ambas cosas (junto con una adopción generalizada). Los wrappers de modelos, Cursor y Windsurf, no tenían tal ventaja, por lo que no recomendaba usarlos. Sin embargo, esta semana salieron con sus propias ofertas, así que veamos cómo se comparan con GPT-5 y Claude 4.5, y si vale la pena cambiar a sus plataformas.
Windsurf SWE-1.5
Para ambos modelos, su principal punto de venta no es necesariamente su calidad, sino su velocidad. GPT-5 en Codex es el mayor ejemplo de lento y bueno, a menudo tomando más de 30 minutos para completar una sola solicitud. Tener un bucle de iteración más rápido con la IA es bueno, especialmente cuando tienes criterios poco especificados donde el modelo no podrá hacerlo bien al primer intento sin importar cuán inteligente sea. Si vas a necesitar tener un ida y vuelta con un modelo para crear una funcionalidad, ¿preferirías esperar 10 segundos o 15 minutos entre respuestas?
Para SWE-1.5, parece estar entrenado a partir del modelo Z.ai GLM 4.5 (no 4.6, muy probablemente debido a que el entrenamiento comenzó antes del lanzamiento de 4.6).
El modelo está alojado en Cerebras, que ofrece la inferencia LLM más rápida de cualquier plataforma por mucho, permitiendo velocidades de inferencia que superan 1.8k tokens por segundo.
SWE-Bench Pro es un poco mejor que el SWE-Bench usual. Sin embargo, está hecho por Scale AI, quienes a menudo proporcionan los datos para estos modelos, por lo que puede haber un conflicto de intereses allí.
En términos de calidad, el modelo parece estar al nivel de GLM 4.6, así que definitivamente utilizable, pero no cerca del nivel fronterizo de inteligencia que Claude 4.5 y GPT-5 tienen. Además, Cerebras ofrecerá GLM 4.6 directamente en un futuro cercano, así que no veo ninguna necesidad de encerrarte en el mundo de Windsurf para usar este modelo.
Será interesante ver si Windsurf podrá ajustar el modelo hasta el punto en que esté al mismo nivel que GPT y Claude, porque entonces hay un incentivo significativo con la velocidad de inferencia + calidad para ir a Windsurf.
Cursor Composer
La característica principal del lanzamiento de Cursor 2.0 es su nuevo modelo Cursor Composer. Similar a SWE-1.5, no sabemos con certeza cuál es el modelo que están usando, aunque definitivamente es un ajuste fino sobre un modelo ya existente. Hay evidencia de que puede estar basado en Deepseek, pero no es tan claro como lo es para SWE-1.5.
Los benchmarks muy vagos son una buena señal
Composer no está alojado en Cerebras, por lo que no puede alcanzar las velocidades de 4 dígitos de tokens por segundo que SWE-1.5 puede, pero aún así es rápido para un modelo transformer.
La impresión general de este es un poco peor que SWE-1.5, probablemente alrededor de la calidad de Sonnet 3.7.
Si SWE-1.5 fue aprobado, entonces Cursor Composer con sus velocidades casi 10x más lentas y peor calidad es un rotundo no.
Investigación
Aprendizaje Continuo de Thinking Machines
Cuando intentas hacer un ajuste fino de un modelo para tu propio caso de uso, lo más difícil de hacer es codificar nueva información en el modelo sin que olvide lo que previamente había conocido y era capaz de hacer. La mejor manera para que un modelo aprenda información es durante los pasos de pre-entrenamiento o entrenamiento intermedio, que está destinado solo para texto no estructurado. Entonces, si estás haciendo un ajuste fino de un modelo que ya ha tenido un post-entrenamiento de estilo chat, esencialmente estarías sobrescribiendo sus comportamientos de chatbot con tu nueva información.
Normalmente agregarías algunos de los datos “originales”, o algo parecido, pero el modelo aún tendría dificultades para recuperar completamente lo que había conocido y era un proceso muy delicado.
Cuanto más entrenas en nueva información, peor se vuelve el seguimiento de instrucciones del modelo, incluso agregando datos del conjunto de datos original. También ten en cuenta que incluso después de entrenar en los documentos, la precisión todavía no estaba por encima del 50%
Los investigadores de Thinking Machines tienen una solución para esto. Proponen una nueva metodología llamada Destilación On-Policy que te permite recuperar la calidad del modelo original muy fácilmente después de hacer un pre-entrenamiento continuo en tus documentos internos.
La Destilación On-Policy usa el modelo original (maestro) como un modelo de recompensa, dando una recompensa por cada token que el modelo ajustado (estudiante) produce. De esta manera, el modelo aprende a imitar la distribución original de conocimiento que tenía. Lo sorprendente de este método es que no causa entonces que el estudiante olvide ninguna de la nueva información que acaba de aprender. También es mucho más eficiente en términos de cómputo que hacer un ajuste fino regular, usando 50-100x menos cómputo en el proceso.
usar destilación on-policy permite agregar nuevo conocimiento mientras se retienen las habilidades previas
Esto no es tan revolucionario en términos de investigación, la mayoría de estos conceptos existían previamente, simplemente han sido reunidos en un solo informe aquí por Thinky.
Lo interesante es que esto, junto con los lanzamientos previos de Thinking Machines de un servicio de entrenamiento y un análisis en profundidad de Lora, parece apuntar a en qué se enfocará la compañía en el futuro.
No están persiguiendo la frontera de la inteligencia como lo hacen OpenAI y Anthropic. En cambio, se están enfocando en modelos pequeños, rápidos y especialmente diseñados que pueden iterarse rápida y fácilmente con información actualizada. Soy un gran fanático de esta dirección, ya que he sido escéptico sobre cuánto realmente necesitamos escalar modelos versus enfocarlos más estrechamente para nuestras tareas. El escalado ha sido simplemente el método más fácil, especialmente con todo el dinero que está fluyendo hacia el campo recientemente.
Yo (creo que) comparto la misma visión del futuro que Thinking Machines, donde ejecutamos nuestros propios modelos en casa o en pequeños clústeres en lugar de usar modelos propietarios en grandes centros de datos. Veremos si esta visión se mantiene. Espero con ansias más lanzamientos de Thinking Machines y me aseguraré de cubrir cualquier cosa interesante aquí.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.