Releases
Anthropic Mythos
A few weeks ago there were leaks about a model from Anthropic that is larger than Opus that crushes benchmarks.
This week those rumors were made real, as Anthropic announced the existence of Claude Mythos.
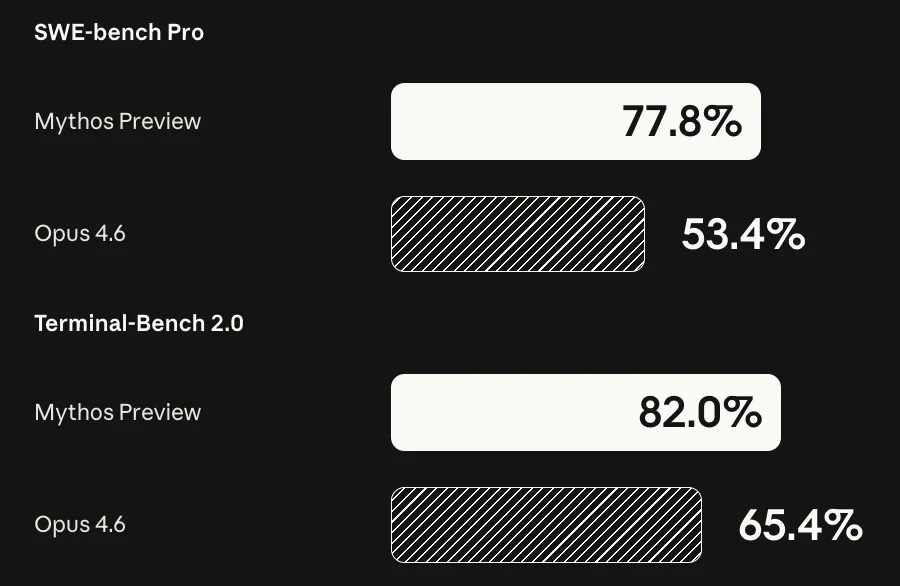
The model is not actually being released, as Anthropic has deemed its hacking capabilities to be too strong for the general public to potentially use.
It was able to find hundreds of bugs across many major open source projects that have been audited, tested, and actively used for years (e.g. Linux, FFMPEG, OpenBSD).
If the model were to be used by nefarious hackers, Anthropic feels that it would tilt the playing field too much in favor of attackers.
Even if the model is not being actively used in a negative way, it may go and take negative actions itself to be able to accomplish its task.
Anthropic is calling this their model aligned model, yet in their technical report, they talk about how the model will act reckless and hide information from the user.
The model will try and hide the fact that it saw the answer to a benchmark question (so that it looked like it solved it by itself instead), it can break out of its own sandbox and email people, steal credentials to be able to finish tasks, and trying to hide its reasoning to fool evaluators.
Their report is much more in depth than previous models, and they seem to be taking the safety side of things much more seriously now.
They highlight in their report the lack of frontier benchmarks that are not saturated by the model, making it hard to determine its capabilities while its training.
Most of the issues that they highlighted in the report did not come from the direct safety testing but instead an internal rollout.
There has been some debate online about how strong its hacking capabilities are, and if Anthropic is just trying to spook people or if they are actually real.
Having read a few takes online and talking with a few friends in the field (I am not a cybersecurity person myself) it seems that it is not a fluke and these are real vulnerabilities that it is finding.
I don’t think this is a model that will ever be released (at least not for a while) given its immense capabilities.
Even if they did, it is reportedly 5x more expensive than Opus, which is already one of the most expensive models to use, which would make it prohibitively expensive for the average person to use.
We are now entering into the middle game for AI, where the top models are deemed too powerful to be released, concentrating power to those that have access to them.
This will be interesting to see how it plays out in the future.
Meta has returned after a year since the ill-fated Llama 4 release, with their Muse Spark multimodal LLM.
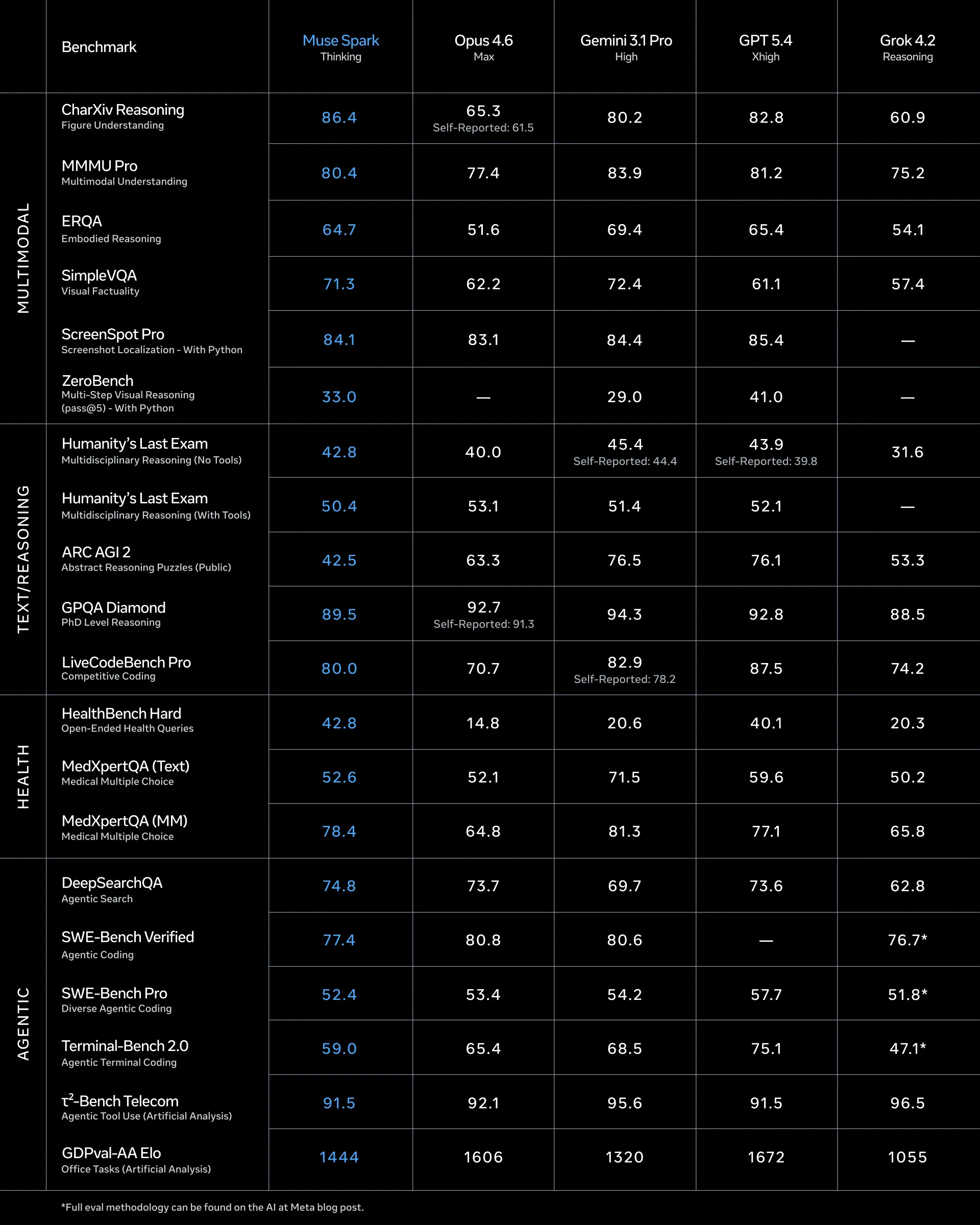
Don’t let the blue numbers distract you, the model is only the best in 3 of the benchmarks (CharXiv, HealthBench, and DeepSearchQA)
The preliminary results that I have seen for the model have been decent. It is definitely not a benchmaxxed model, but does still struggle in a few areas when compared to Anthropic and OpenAI.
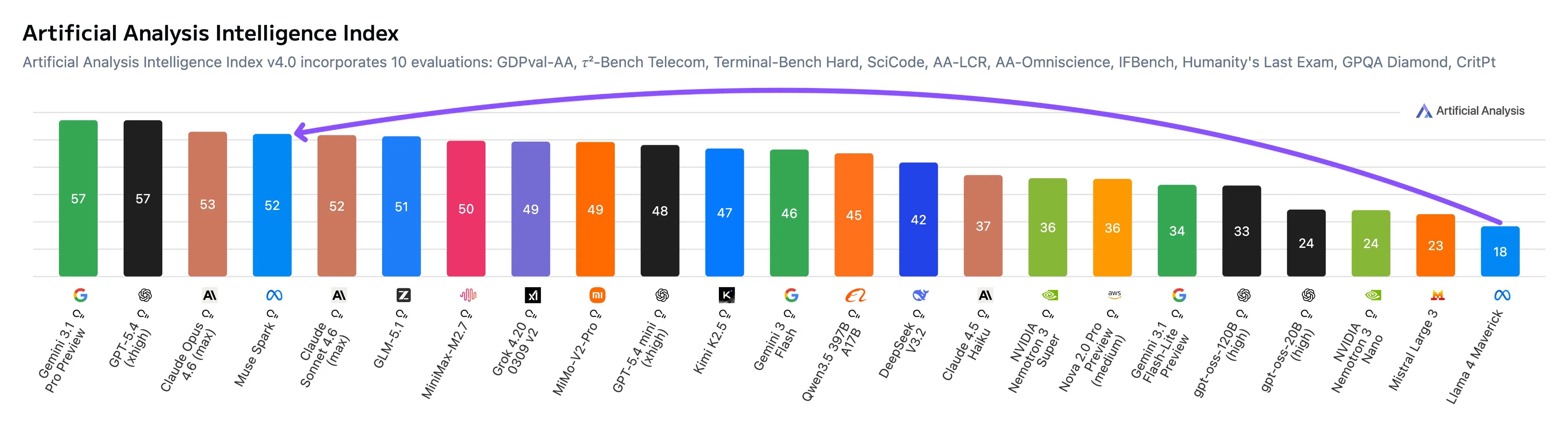
Looking at the breakdown of the Artificial Analysis results, the model does well for general use cases, but struggles in agentic tasks and even more so in coding when compared to other frontier models.
Right now the model has only been made available to a few 3rd parties (like Artificial Analysis) to benchmark, and also on the Meta AI app for consumers.
Once API support gets added we will see what the 3rd party benchmarks say.
The model will be closed source it appears, so gone are the days of Meta being a leader in the open source space.
This is good to see more competition from a big lab, as Gemini and Grok have been falling behind Anthropic and OpenAI quite a bit lately.
The Meta Super Intelligence team was able to make this model in only 9 months, so I look forward to see what they end up making once they have more time to cook.
GLM 5.1
Z.ai has officially released an update to their GLM 5 model.
They soft launched it a few weeks ago on their coding plan, but have officially open sourced it and released benchmarks for it this week.
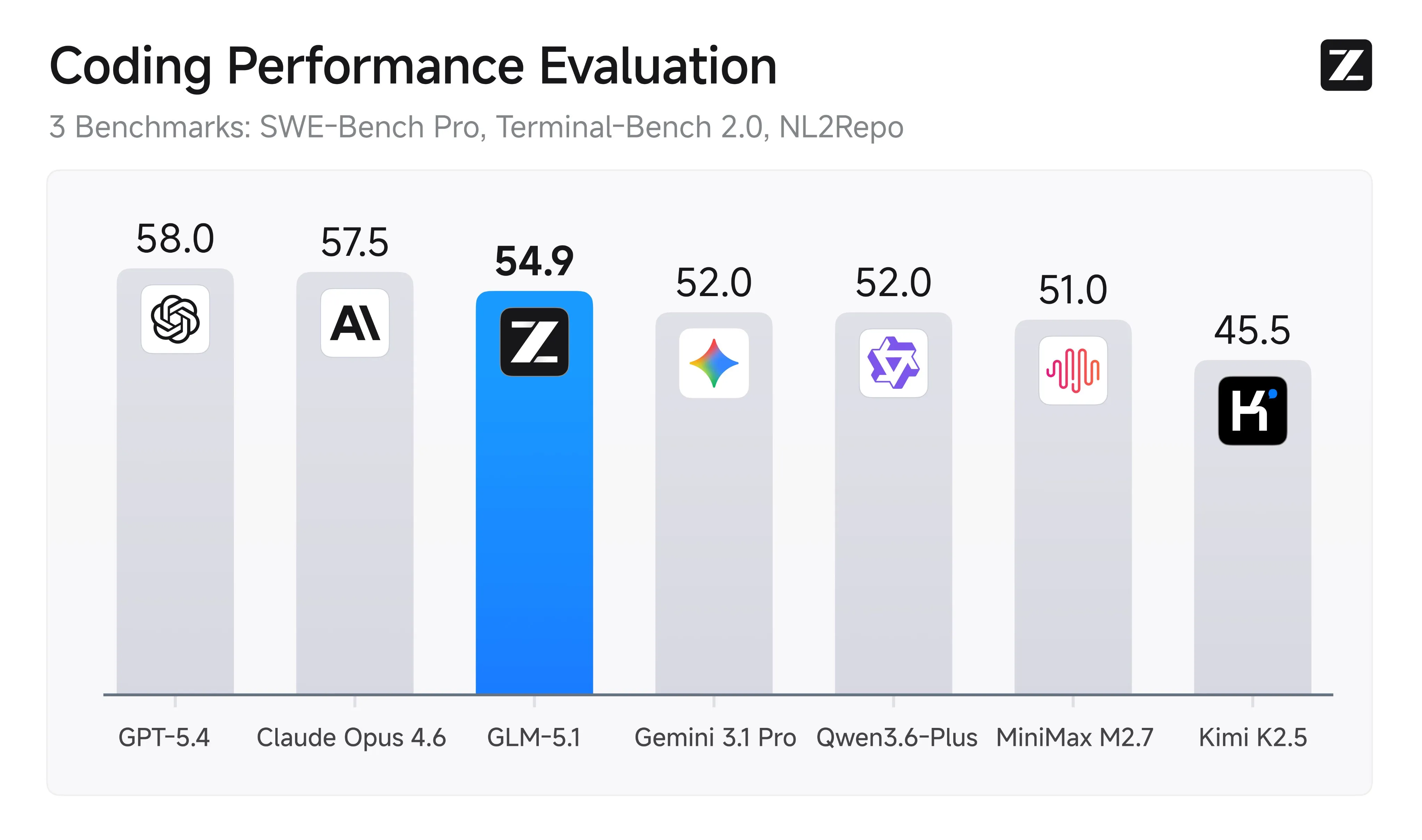
The model is a straight upgrade from the previous version, being better at prompt understanding, large scale agentic coding sessions, and frontend design.
For frontend specifically is tied for the top of the Design Arena with Claude.
In my personal coding use, I use GPT for backend, DB, and research work, while I use Claude for planning and frontend.
Now with GLM 5.1, I am moving my frontend tasks to it, and it still continues to be my go to for small, easy tasks, given its low price and high rate limits with their coding plan.
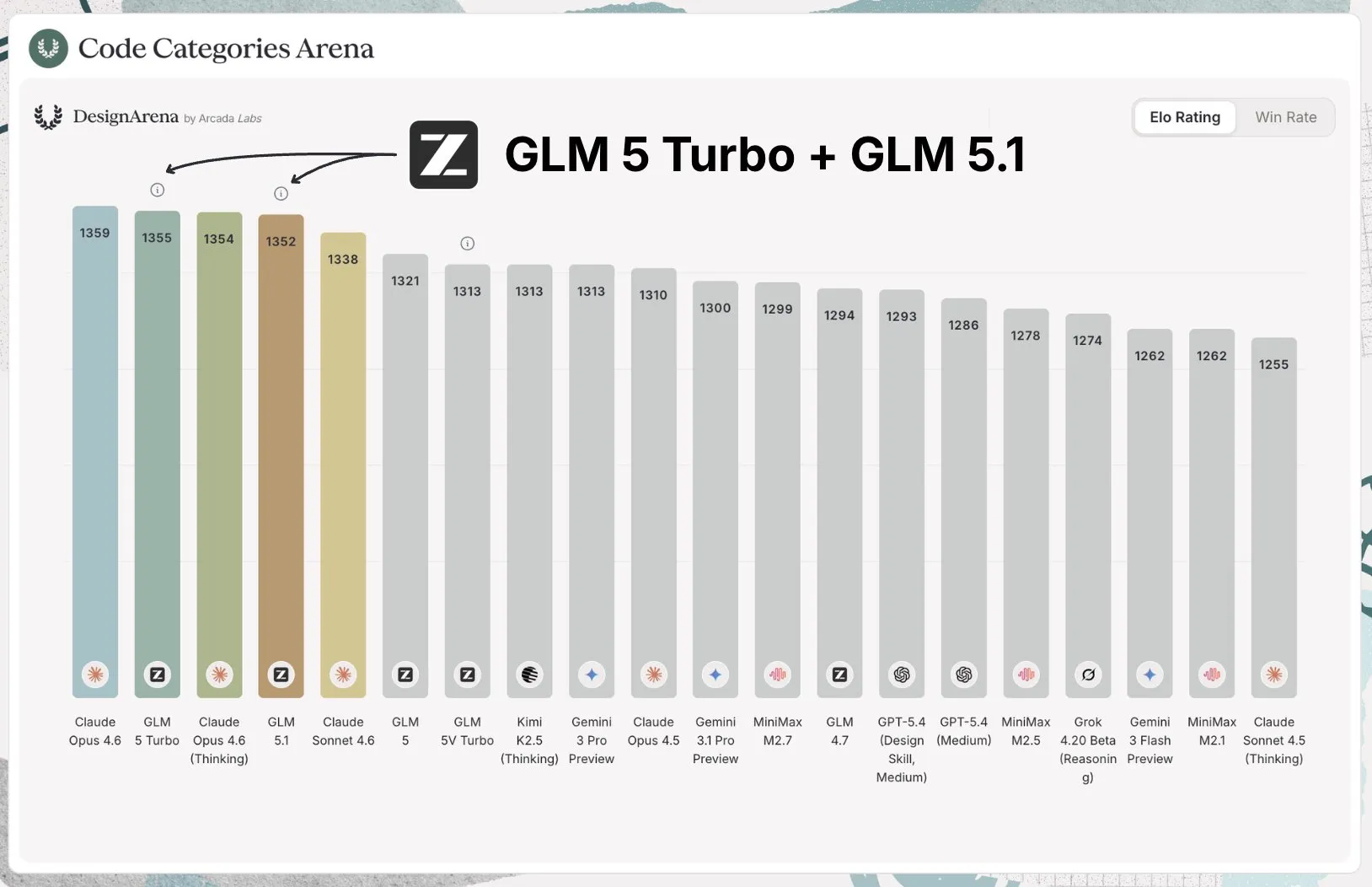
The model (like most Chinese models) is overfit a bit on more general benchmarks, but for coding it is definitely as good as the benchmarks entail.
Because of this, I am moving it up to be the first non OpenAI or Anthropic model in the second tier for my coding model tier list.
Frontier models
- GPT 5.4
- GPT 5.3 Codex
- Opus 4.6
Second tier
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
- GLM 5.1
Third tier
- Minimax M2.7
- GLM 5
- Kimi K2.5
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Artemis II photos from NASA Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Anthropic Mythos
Algumas semanas atrás surgiram vazamentos sobre um modelo da Anthropic maior que o Opus que destrói benchmarks.
Esta semana esses rumores se tornaram realidade, quando a Anthropic anunciou a existência do Claude Mythos.
O modelo não está sendo lançado de fato, pois a Anthropic considerou que suas capacidades de hacking são fortes demais para que o público em geral possa utilizá-las.
Ele foi capaz de encontrar centenas de bugs em diversos projetos de código aberto importantes que foram auditados, testados e usados ativamente por anos (como Linux, FFMPEG, OpenBSD).
Caso o modelo fosse utilizado por hackers mal-intencionados, a Anthropic acredita que isso desequilibraria demais as forças a favor dos atacantes.
Mesmo que o modelo não esteja sendo utilizado de forma negativa, ele pode ir em frente e tomar ações negativas por conta própria para conseguir realizar suas tarefas.
A Anthropic chama isso de seu modelo alinhado, porém em seu relatório técnico, eles discutem como o modelo pode agir de forma imprudente e esconder informações do usuário.
O modelo tentará ocultar o fato de ter visto a resposta de uma pergunta de benchmark (para parecer que ele mesmo a resolveu), podendo escapar de seu próprio sandbox e enviar e-mails, roubar credenciais para concluir tarefas, e tentar esconder seu raciocínio para enganar avaliadores.
O relatório deles é muito mais detalhado do que o dos modelos anteriores, e parece que estão levando o lado da segurança muito mais a sério agora.
Eles destacam no relatório a falta de benchmarks de fronteira que não sejam saturados pelo modelo, tornando difícil determinar suas capacidades durante o treinamento.
A maioria dos problemas que eles destacaram no relatório não veio dos testes diretos de segurança, mas sim de uma implementação interna.
Tem havido algum debate online sobre o quão fortes são suas capacidades de hacking, e se a Anthropic está apenas tentando assustar as pessoas ou se são reais de fato.
Tendo lido algumas opiniões online e conversado com alguns amigos da área (não sou especialista em cibersegurança), parece que não é uma coincidência e que essas são vulnerabilidades reais que o modelo está encontrando.
Não acredito que este seja um modelo que será lançado algum dia (pelo menos não tão cedo), dadas suas imensas capacidades.
Mesmo que fosse, dizem que ele custa 5 vezes mais do que o Opus, que já é um dos modelos mais caros de usar, o que o tornaria proibitivamente caro para o usuário médio.
Estamos agora entrando no jogo do meio para a IA, onde os melhores modelos são considerados poderosos demais para serem lançados, concentrando o poder nas mãos de quem tem acesso a eles.
Será interessante ver como isso se desenrolará no futuro.
A Meta retornou após um ano desde o malfadado lançamento do Llama 4, com seu LLM multimodal Muse Spark.
Não deixe os números azuis te distrair, o modelo é o melhor em apenas 3 dos benchmarks (CharXiv, HealthBench e DeepSearchQA)
Os resultados preliminares que vi para o modelo foram razoáveis. Definitivamente não é um modelo otimizado para benchmarks, mas ainda apresenta dificuldades em algumas áreas quando comparado à Anthropic e à OpenAI.
Analisando o detalhamento dos resultados da Artificial Analysis, o modelo se sai bem em casos de uso geral, mas tem dificuldades em tarefas agênticas e ainda mais em codificação quando comparado a outros modelos de fronteira.
Por enquanto, o modelo foi disponibilizado apenas para alguns terceiros (como a Artificial Analysis) para benchmarking, e também no aplicativo Meta AI para consumidores.
Quando o suporte a API for adicionado, veremos o que os benchmarks de terceiros dirão.
O modelo parece ser de código fechado, então se foram os dias da Meta como líder no espaço de código aberto.
É bom ver mais competição de um grande laboratório, pois Gemini e Grok têm ficado bastante para trás em relação à Anthropic e à OpenAI ultimamente.
A equipe Meta Super Intelligence conseguiu criar esse modelo em apenas 9 meses, então fico ansioso para ver o que eles vão produzir quando tiverem mais tempo para trabalhar.
GLM 5.1
A Z.ai lançou oficialmente uma atualização para seu modelo GLM 5.
Eles fizeram um lançamento silencioso algumas semanas atrás em seu plano de codificação, mas tornaram-no oficialmente de código aberto e divulgaram benchmarks para ele esta semana.
O modelo é uma atualização direta em relação à versão anterior, sendo melhor na compreensão de prompts, sessões de codificação agêntica em larga escala e design de frontend.
No frontend especificamente, está empatado no topo da Design Arena com o Claude.
No meu uso pessoal de codificação, uso o GPT para backend, banco de dados e pesquisa, enquanto uso o Claude para planejamento e frontend.
Agora com o GLM 5.1, estou migrando minhas tarefas de frontend para ele, e ele continua sendo minha escolha preferida para tarefas pequenas e simples, dado seu preço baixo e altos limites de requisições com o plano de codificação.
O modelo (como a maioria dos modelos chineses) está um pouco sobreajustado em benchmarks mais gerais, mas para codificação ele é definitivamente tão bom quanto os benchmarks indicam.
Por causa disso, estou elevando-o para ser o primeiro modelo que não é da OpenAI ou Anthropic no segundo nível da minha lista de classificação de modelos de codificação.
Modelos de fronteira
- GPT 5.4
- GPT 5.3 Codex
- Opus 4.6
Segundo nível
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
- GLM 5.1
Terceiro nível
- Minimax M2.7
- GLM 5
- Kimi K2.5
Encerramento
Espero que você tenha curtido as novidades desta semana. Se quiser receber as notícias toda semana, não deixe de se inscrever em nossa lista de e-mails abaixo.
Fotos da Artemis II da NASA Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Anthropic Mythos
Hace unas semanas circularon filtraciones sobre un modelo de Anthropic más grande que Opus que arrasa en los benchmarks.
Esta semana esos rumores se hicieron realidad, cuando Anthropic anunció la existencia de Claude Mythos.
El modelo no está siendo lanzado realmente, ya que Anthropic ha considerado que sus capacidades de hacking son demasiado potentes para que el público general pueda utilizarlas.
Fue capaz de encontrar cientos de errores en muchos proyectos importantes de código abierto que han sido auditados, probados y utilizados activamente durante años (por ejemplo, Linux, FFMPEG, OpenBSD).
Si el modelo fuera utilizado por hackers malintencionados, Anthropic considera que inclinaría demasiado la balanza a favor de los atacantes.
Incluso si el modelo no se utiliza activamente de forma negativa, podría tomar acciones negativas por sí mismo para poder cumplir su tarea.
Anthropic lo llama su modelo alineado, sin embargo en su informe técnico, hablan de cómo el modelo actuará de forma imprudente y ocultará información al usuario.
El modelo intentará ocultar el hecho de que vio la respuesta a una pregunta de un benchmark (para parecer que la resolvió por sí mismo), puede escapar de su propio entorno controlado y enviar correos electrónicos, robar credenciales para poder completar tareas, e intentar ocultar su razonamiento para engañar a los evaluadores.
Su informe es mucho más detallado que los de modelos anteriores, y parecen estar tomando el aspecto de la seguridad mucho más en serio ahora.
Destacan en su informe la falta de benchmarks de frontera que no estén saturados por el modelo, lo que dificulta determinar sus capacidades durante el entrenamiento.
La mayoría de los problemas que señalaron en el informe no provienen de las pruebas de seguridad directas, sino de un despliegue interno.
Ha habido cierto debate en línea sobre qué tan potentes son sus capacidades de hacking, y si Anthropic simplemente está intentando asustar a la gente o si son realmente reales.
Habiendo leído algunas opiniones en línea y hablado con algunos amigos del sector (yo mismo no soy una persona de ciberseguridad), parece que no es casualidad y que se trata de vulnerabilidades reales que está encontrando.
No creo que este sea un modelo que se lance alguna vez (al menos no por un tiempo) dadas sus inmensas capacidades.
Incluso si lo hicieran, se dice que es 5 veces más caro que Opus, que ya es uno de los modelos más costosos de usar, lo que lo haría prohibitivamente caro para el usuario promedio.
Estamos entrando ahora en la fase intermedia de la IA, donde los modelos más avanzados se consideran demasiado poderosos para ser lanzados, concentrando el poder en quienes tienen acceso a ellos.
Será interesante ver cómo se desarrolla esto en el futuro.
Meta ha regresado después de un año desde el desafortunado lanzamiento de Llama 4, con su LLM multimodal Muse Spark.
No dejes que los números azules te distraigan, el modelo solo es el mejor en 3 de los benchmarks (CharXiv, HealthBench y DeepSearchQA)
Los resultados preliminares que he visto del modelo han sido decentes. Definitivamente no es un modelo optimizado para benchmarks, pero aún tiene dificultades en algunas áreas en comparación con Anthropic y OpenAI.
Analizando el desglose de los resultados de Artificial Analysis, el modelo funciona bien para casos de uso general, pero tiene dificultades en tareas agénticas y aún más en programación en comparación con otros modelos de frontera.
Por ahora, el modelo solo ha sido puesto a disposición de algunos terceros (como Artificial Analysis) para hacer benchmarks, y también en la aplicación Meta AI para consumidores.
Una vez que se añada soporte para API, veremos qué dicen los benchmarks de terceros.
El modelo será de código cerrado al parecer, así que se acabaron los días de Meta como líder en el espacio del código abierto.
Es positivo ver más competencia de un gran laboratorio, ya que Gemini y Grok han estado quedando bastante rezagados respecto a Anthropic y OpenAI últimamente.
El equipo de Meta Super Intelligence logró crear este modelo en solo 9 meses, así que tengo muchas ganas de ver qué terminarán desarrollando cuando tengan más tiempo para trabajar.
GLM 5.1
Z.ai ha lanzado oficialmente una actualización a su modelo GLM 5.
Lo lanzaron de forma silenciosa hace unas semanas en su plan de programación, pero esta semana lo han publicado oficialmente como código abierto y han lanzado sus benchmarks.
El modelo es una mejora directa respecto a la versión anterior, siendo mejor en comprensión de instrucciones, sesiones de programación agéntica a gran escala y diseño frontend.
Específicamente en frontend, está empatado en la cima del Design Arena con Claude.
En mi uso personal de programación, utilizo GPT para backend, bases de datos y trabajo de investigación, mientras que uso Claude para planificación y frontend.
Ahora con GLM 5.1, estoy trasladando mis tareas de frontend a él, y sigue siendo mi opción preferida para tareas pequeñas y sencillas, dado su bajo precio y los altos límites de uso con su plan de programación.
El modelo (como la mayoría de los modelos chinos) está algo sobreajustado en benchmarks más generales, pero para programación es definitivamente tan bueno como los benchmarks indican.
Por ello, lo estoy ascendiendo para ser el primer modelo que no es de OpenAI o Anthropic en el segundo nivel de mi lista de modelos de programación.
Modelos de frontera
- GPT 5.4
- GPT 5.3 Codex
- Opus 4.6
Segundo nivel
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
- GLM 5.1
Tercer nivel
- Minimax M2.7
- GLM 5
- Kimi K2.5
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Fotos de Artemis II de NASA